什么是 Kafka
kafka 是一种消息队列。
当我们把数据从生产方发送给消费方时候,因为生产方产生消息的速度比较快,消费方消化速度比较慢,所以需要有一个中间方,缓存生产方的数据,然后再把消息一条条的推送给消费方(是 kafka 推送给消费方,还是消费方来拉去消息,这个需要确认下?)。
在这种架构下,producer 和 Consumer 可以随意的扩缩容。
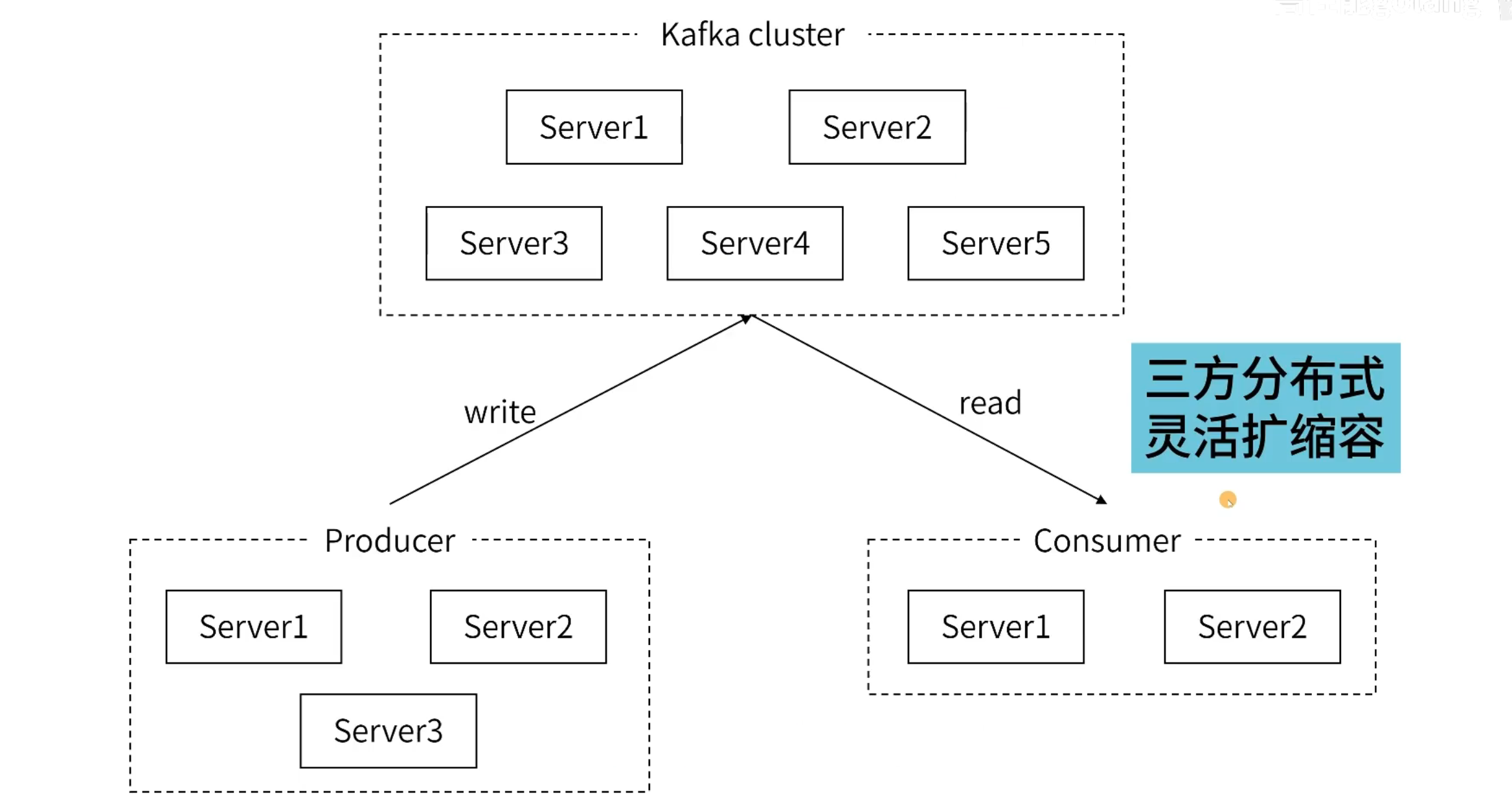
Kafka 集群
Kafka 集群是由许多个 broker 组成的,这个 broker 可以理解为 kafka 的一个进程,是一个专有名词。一般来说,会在每一台服务器上启一个 Kafka 进程。但是,从理论上来说,我们在测试的时候,可以在一台机器上启动多个 kafka 进程来搭建集群。
如下图所示,kafka 集群内有多个 broker,每个 broker 里有多个 topic,每个 topic 里有多个 partition,每个 partition 有 leader 和 fllower 主从备份。

Topic 概念
Kafka 里将某一种业务数据称作 topic。
这个 topic 可能会被多个团队来共同消费,例如,推荐算法团队、广告上报团队都需要来实时的读取这个 topic 的数据,那么,我们把同一种业务数据放在同一个 topic 里。
一个 topic 会分成多个 partition。例如,根据 key 哈希等方式,可以把原始的数据切分成多份,存在不同的 partion 上,这个就可以提高并发 IO 吞吐量的性能。
同一 partiton 数据又有多个备份,一个 leader 多个 flolower,主要是为了提高可靠性,一旦某个 partiton 失败了,可以启动备份。
Partition 和 consumer 关系
如下例中:
- consumer1 消费 partiton1、Partiton4
- Consumer2 消费 Partition2、Partition3、Partition5

关系如下:
- 一个 partition 只能由一个 consumer 来消费,一个 consumer 可以消费多个 Partition,所以 consumer 数小于 partition 数时才有意义,众多 partition 会均匀的分布在各个 consumer 上。如果 consumer 数量大于 partition 的数量,会导致有些 consumer 读取不到数据。
- Consumer 越多,吞吐越高,消费得越快。
- Consumer 增加或减少时,partition 和 consumer 的对应关系会自动调整(例如使用 HashRing算法),保证一个负载均衡的状态。
在实际开发过程中,小公司一般 partiton 的数量设置 10 个左右即可,设置的要比预期的要多一些,对于大公司而言,partition 设置个 100 多个。
Consumer 分组
Kafka 的 consumer 可以分组,一个组给一个业务方消费。例如点击数据,推荐算法团队要消费,广告团队也要消费。就可以创建推荐算法组和广告组,分别给不同的团队消费数据。
每一个组消费一份完整的 Topic 数据。同一个组可以启动多个 consumer 来消费同一个 topic,组内的多个 consumer 之间,不会消费到相同的数据。不同组之间会消费同样的数据。

Offset 概念
Partition 里的 offset,就好比表里的主键 id 一样,顺序递增。

- 同一个 partition 内部的消息是有序的,越新的消息 offset 越大。不同 partition 之间的消息根据
offset 无法比较新旧。 - Consumer 顺序地消费 partition 里的每一条消息,可以每读一条就向 kafka上报(commit)
一次当前读到了哪个位置(offset),也可以间隔性上报(每读多少条上报一次,或每隔多长
时间上报一次)。 - Consumer 重启时 kafka 根据该 group 上一次 commit 的最大offset,决定从哪个地方开始
消费。
数据写入
Producer 写数据时选择写哪个 partition?
- Producer 可以显式指定 partition
- 没有指定 partition 时,根据消息的 key 通过哈希算法选择一个 partition(一个key对应一个固定的partition)。
- 既没指定 partition,消息又没有 key 时,按时间片轮动选择Partition。例如:这5分钟,往 Partition0 写入数据,下5分钟,往 Partition1 写入数据,再下5分钟,往 Partition2 写入数据,最后又往 Partition0 写入数据,轮询。

Partition 主从
步骤如下:
- Producer 询问 Kafka Cluster, 得到特定 Topic 的特定 Partition 的 Leader。
- Producer 把数据发给 Leader,Leader 把数据写入本地磁盘
- Follower 从 Leader 拉取数据,把数据写入本地磁盘
- Follower 向 Leader 返回 ACK,确认成功
- Leader 向 Producer 返回 ACK,确认成功
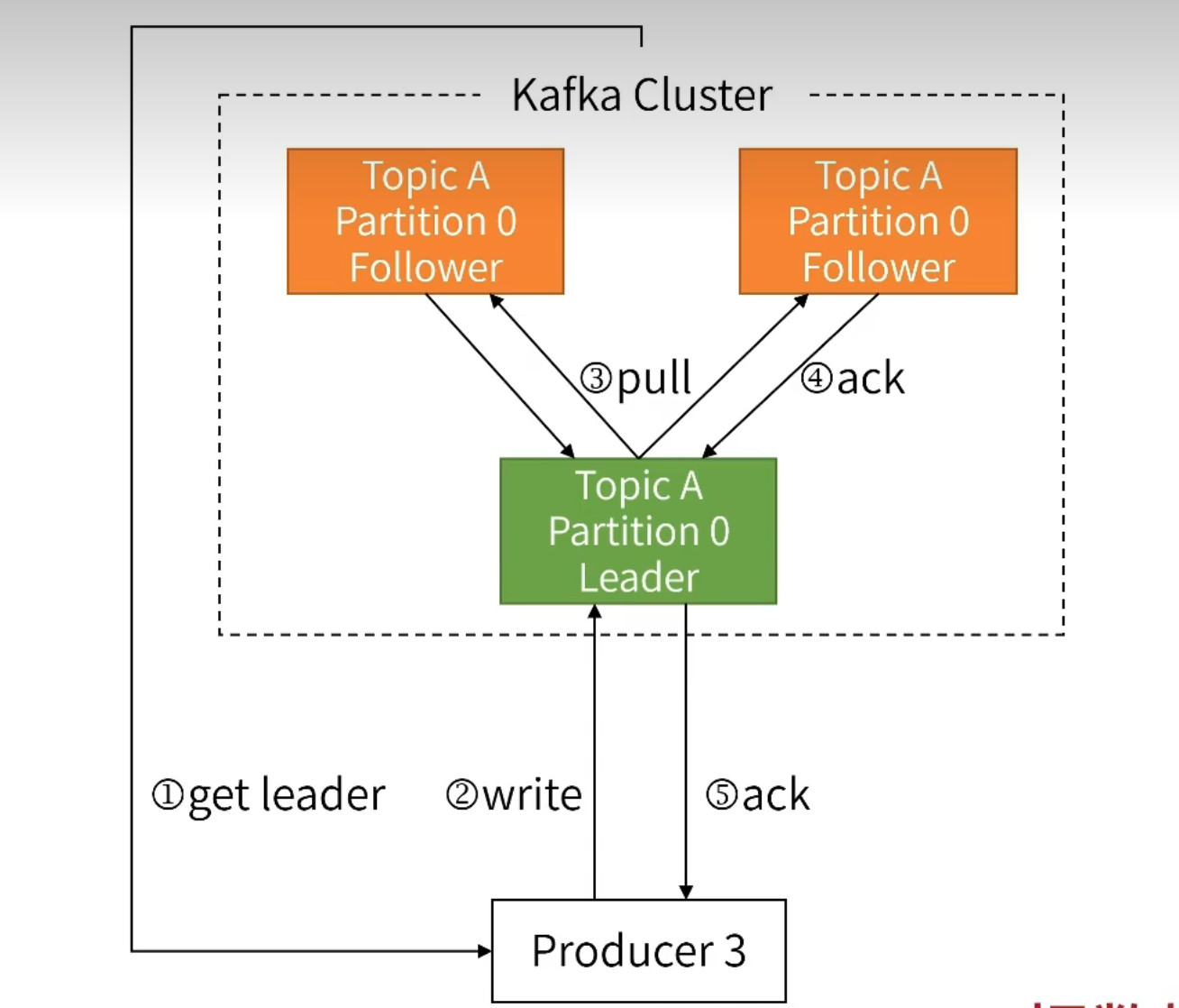
在实际操作中,producer 客户端有参数,可以设置是否需要等对方给我返回 ack 消息,如果设置了需要等待的话,会比较慢。producer 客户端的 ack 设置,有多种策略,比如可以设置为:
- 只要 leader 给我返回 ack 消息就好了,不需要等 fllower 向 leader 返回 ack,我就认为成功了,这样会相对快一点
- 都不需要等 ack 信号

1 条评论
真好呢