搜索到
14
篇与
的结果
-

-
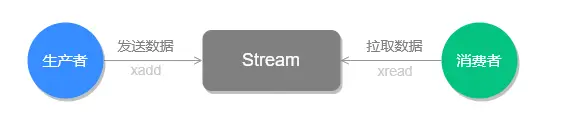
详细分析Redis的Stream类型 - 专业指南 介绍 Redis Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。 在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如: 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷; List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。 基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。 常见命令 Stream 消息队列操作命令: XADD:插入消息,保证有序,可以自动生成全局唯一 ID; XLEN :查询消息长度; XREAD:用于读取消息,可以按 ID 读取数据; XDEL : 根据消息 ID 删除消息; DEL :删除整个 Stream; XRANGE :读取区间消息 XREADGROUP:按消费组形式读取消息; XPENDING 和 XACK: XPENDING 命令可以用来查询每个消费组内所有消费者「已读取、但尚未确认」的消息; XACK 命令用于向消息队列确认消息处理已完成; 应用场景 消息队列 生产者通过 XADD 命令插入一条消息 # * 表示让 Redis 为插入的数据自动生成一个全局唯一的 ID # 往名称为 mymq 的消息队列中插入一条消息,消息的键是 name,值是 xiaolin > XADD mymq * name xiaolin "1654254953808-0" 插入成功后会返回全局唯一的 ID:"1654254953808-0"。消息的全局唯一 ID 由两部分组成: 第一部分“1654254953808”是数据插入时,以毫秒为单位计算的当前服务器时间; 第二部分表示插入消息在当前毫秒内的消息序号,这是从 0 开始编号的。例如,“1654254953808-0”就表示在“1654254953808”毫秒内的第 1 条消息。 消费者通过 XREAD 命令从消息队列中读取消息时,可以指定一个消息 ID,并从这个消息 ID 的下一条消息开始进行读取(注意是输入消息 ID 的下一条信息开始读取,不是查询输入ID的消息)。 # 从 ID 号为 1654254953807-0 的消息开始,读取后续的所有消息(示例中一共 1 条)。 > XREAD STREAMS mymq 1654254953807-0 1) 1) "mymq" 2) 1) 1) "1654254953808-0" 2) 1) "name" 2) "xiaolin" 如果想要实现阻塞读(当没有数据时,阻塞住),可以调用 XRAED 时设定 BLOCK 配置项,实现类似于 BRPOP 的阻塞读取操作。 比如,下面这命令,设置了 BLOCK 10000 的配置项,10000 的单位是毫秒,表明 XREAD 在读取最新消息时,如果没有消息到来,XREAD 将阻塞 10000 毫秒(即 10 秒),然后再返回。 # 命令最后的“$”符号表示读取最新的消息 > XREAD BLOCK 10000 STREAMS mymq $ (nil) (10.00s) Stream 的基础方法,使用 xadd 存入消息和 xread 循环阻塞读取消息的方式可以实现简易版的消息队列,交互流程如下图所示: 前面介绍的这些操作 List 也支持的,接下来看看 Stream 特有的功能。 Stream 可以以使用 XGROUP 创建消费组,创建消费组之后,Stream 可以使用 XREADGROUP 命令让消费组内的消费者读取消息。 创建两个消费组,这两个消费组消费的消息队列是 mymq,都指定从第一条消息开始读取: # 创建一个名为 group1 的消费组,0-0 表示从第一条消息开始读取。 > XGROUP CREATE mymq group1 0-0 OK # 创建一个名为 group2 的消费组,0-0 表示从第一条消息开始读取。 > XGROUP CREATE mymq group2 0-0 OK 消费组 group1 内的消费者 consumer1 从 mymq 消息队列中读取所有消息的命令如下: # 命令最后的参数“>”,表示从第一条尚未被消费的消息开始读取。 > XREADGROUP GROUP group1 consumer1 STREAMS mymq > 1) 1) "mymq" 2) 1) 1) "1654254953808-0" 2) 1) "name" 2) "xiaolin" 消息队列中的消息一旦被消费组里的一个消费者读取了,就不能再被该消费组内的其他消费者读取了,即同一个消费组里的消费者不能消费同一条消息。 比如说,我们执行完刚才的 XREADGROUP 命令后,再执行一次同样的命令,此时读到的就是空值了: > XREADGROUP GROUP group1 consumer1 STREAMS mymq > (nil) 但是,不同消费组的消费者可以消费同一条消息(但是有前提条件,创建消息组的时候,不同消费组指定了相同位置开始读取消息)。 比如说,刚才 group1 消费组里的 consumer1 消费者消费了一条 id 为 1654254953808-0 的消息,现在用 group2 消费组里的 consumer1 消费者消费消息: > XREADGROUP GROUP group2 consumer1 STREAMS mymq > 1) 1) "mymq" 2) 1) 1) "1654254953808-0" 2) 1) "name" 2) "xiaolin" 因为我创建两组的消费组都是从第一条消息开始读取,所以可以看到第二组的消费者依然可以消费 id 为 1654254953808-0 的这一条消息。因此,不同的消费组的消费者可以消费同一条消息。 使用消费组的目的是让组内的多个消费者共同分担读取消息,所以,我们通常会让每个消费者读取部分消息,从而实现消息读取负载在多个消费者间是均衡分布的。 例如,我们执行下列命令,让 group2 中的 consumer1、2、3 各自读取一条消息。 # 让 group2 中的 consumer1 从 mymq 消息队列中消费一条消息 > XREADGROUP GROUP group2 consumer1 COUNT 1 STREAMS mymq > 1) 1) "mymq" 2) 1) 1) "1654254953808-0" 2) 1) "name" 2) "xiaolin" # 让 group2 中的 consumer2 从 mymq 消息队列中消费一条消息 > XREADGROUP GROUP group2 consumer2 COUNT 1 STREAMS mymq > 1) 1) "mymq" 2) 1) 1) "1654256265584-0" 2) 1) "name" 2) "xiaolincoding" # 让 group2 中的 consumer3 从 mymq 消息队列中消费一条消息 > XREADGROUP GROUP group2 consumer3 COUNT 1 STREAMS mymq > 1) 1) "mymq" 2) 1) 1) "1654256271337-0" 2) 1) "name" 2) "Tom" 基于 Stream 实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息? Streams 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用 XACK 命令通知 Streams“消息已经处理完成”。 消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 XACK 命令确认消息已经被消费完成,整个流程的执行如下图所示: 如果消费者没有成功处理消息,它就不会给 Streams 发送 XACK 命令,消息仍然会留存。此时,消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。 例如,我们来查看一下 group2 中各个消费者已读取、但尚未确认的消息个数,命令如下: 127.0.0.1:6379> XPENDING mymq group2 1) (integer) 3 2) "1654254953808-0" # 表示 group2 中所有消费者读取的消息最小 ID 3) "1654256271337-0" # 表示 group2 中所有消费者读取的消息最大 ID 4) 1) 1) "consumer1" 2) "1" 2) 1) "consumer2" 2) "1" 3) 1) "consumer3" 2) "1" 如果想查看某个消费者具体读取了哪些数据,可以执行下面的命令: # 查看 group2 里 consumer2 已从 mymq 消息队列中读取了哪些消息 > XPENDING mymq group2 - + 10 consumer2 1) 1) "1654256265584-0" 2) "consumer2" 3) (integer) 410700 4) (integer) 1 可以看到,consumer2 已读取的消息的 ID 是 1654256265584-0。 一旦消息 1654256265584-0 被 consumer2 处理了,consumer2 就可以使用 XACK 命令通知 Streams,然后这条消息就会被删除。 > XACK mymq group2 1654256265584-0 (integer) 1 当我们再使用 XPENDING 命令查看时,就可以看到,consumer2 已经没有已读取、但尚未确认处理的消息了。 > XPENDING mymq group2 - + 10 consumer2 (empty array) 好了,基于 Stream 实现的消息队列就说到这里了,小结一下: 消息保序:XADD/XREAD 阻塞读取:XREAD block 重复消息处理:Stream 在使用 XADD 命令,会自动生成全局唯一 ID; 消息可靠性:内部使用 PENDING List 自动保存消息,使用 XPENDING 命令查看消费组已经读取但是未被确认的消息,消费者使用 XACK 确认消息; 支持消费组形式消费数据 Redis 基于 Stream 消息队列与专业的消息队列有哪些差距? 一个专业的消息队列,必须要做到两大块: 消息不丢。 消息可堆积 1、Redis Stream 消息会丢失吗? 使用一个消息队列,其实就分为三大块:生产者、队列中间件、消费者,所以要保证消息就是保证三个环节都不能丢失数据。 Redis Stream 消息队列能不能保证三个环节都不丢失数据? Redis 生产者会不会丢消息?生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。 从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 ( MQ 中间件) 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,如果返回异常则进行消息重发,那么这个阶段是不会出现消息丢失的。 Redis 消费者会不会丢消息?不会,因为 Stream ( MQ 中间件)会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,但是未被确认的消息。消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。等到消费者执行完业务逻辑后,再发送消费确认 XACK 命令,也能保证消息的不丢失。 Redis 消息中间件会不会丢消息?会,Redis 在以下 2 个场景下,都会导致数据丢失 AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能 主从复制也是异步的,主从切换时,也存在丢失数据的可能 可以看到,Redis 在队列中间件环节无法保证消息不丢。像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。 2、Redis Stream 消息可堆积吗? Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。 所以 Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。 当指定队列最大长度时,队列长度超过上限后,旧消息会被删除,只保留固定长度的新消息。这么来看,Stream 在消息积压时,如果指定了最大长度,还是有可能丢失消息的。 但 Kafka、RabbitMQ 专业的消息队列它们的数据都是存储在磁盘上,当消息积压时,无非就是多占用一些磁盘空间。 因此,把 Redis 当作队列来使用时,会面临的 2 个问题: Redis 本身可能会丢数据; 面对消息挤压,内存资源会紧张; 所以,能不能将 Redis 作为消息队列来使用,关键看你的业务场景: 如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。 如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧。 补充:Redis 发布/订阅机制为什么不可以作为消息队列? 发布订阅机制存在以下缺点,都是跟丢失数据有关: 发布/订阅机制没有基于任何数据类型实现,所以不具备「数据持久化」的能力,也就是发布/订阅机制的相关操作,不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,发布/订阅机制的数据也会全部丢失。 发布订阅模式是“发后既忘”的工作模式,如果有订阅者离线重连之后不能消费之前的历史消息。 当消费端有一定的消息积压时,也就是生产者发送的消息,消费者消费不过来时,如果超过 32M 或者是 60s 内持续保持在 8M 以上,消费端会被强行断开,这个参数是在配置文件中设置的,默认值是 client-output-buffer-limit pubsub 32mb 8mb 60。 所以,发布/订阅机制只适合即使通讯的场景,比如构建哨兵集群 (opens new window)的场景采用了发布/订阅机制。
-
Redis Geo类型深度解析与实践 介绍 Redis GEO 是 Redis 3.2 版本新增的数据类型,主要用于存储地理位置信息,并对存储的信息进行操作。 在日常生活中,我们越来越依赖搜索“附近的餐馆”、在打车软件上叫车,这些都离不开基于位置信息服务(Location-Based Service,LBS)的应用。LBS 应用访问的数据是和人或物关联的一组经纬度信息,而且要能查询相邻的经纬度范围,GEO 就非常适合应用在 LBS 服务的场景中 内部实现 GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型。 GEO 类型使用 GeoHash 编码方法 实现了 经纬度到 Sorted Set 中元素权重分数的转换 ,这其中的两个关键机制就是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数。 这样一来,我们就可以把经纬度保存到 Sorted Set 中,利用 Sorted Set 提供的“按权重进行有序范围查找”的特性,实现 LBS 服务中频繁使用的“搜索附近”的需求。 常用命令 # 存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。 GEOADD key longitude latitude member [longitude latitude member ...] # 从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。 GEOPOS key member [member ...] # 返回两个给定位置之间的距离。 GEODIST key member1 member2 [m|km|ft|mi] # 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。 GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] 应用场景 滴滴叫车 这里以滴滴叫车的场景为例,介绍下具体如何使用 GEO 命令:GEOADD 和 GEORADIUS 这两个命令。 假设车辆 ID 是 33,经纬度位置是(116.034579,39.030452),我们可以用一个 GEO 集合保存所有车辆的经纬度,集合 key 是 cars:locations。 执行下面的这个命令,就可以把 ID 号为 33 的车辆的当前经纬度位置存入 GEO 集合中 GEOADD cars:locations 116.034579 39.030452 33 当用户想要寻找自己附近的网约车时,LBS 应用就可以使用 GEORADIUS 命令。 例如,LBS 应用执行下面的命令时,Redis 会根据输入的用户的经纬度信息(116.054579,39.030452 ),查找以这个经纬度为中心的 5 公里内的车辆信息,并返回给 LBS 应用。 GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10
-
Redis HyperLogLog类型详细解析 介绍 Redis HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于「 基数统计 」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的, 不是非常准确 ,标准误算率是 0.81%。 所以,简单来说 HyperLogLog 提供不精确的去重计数。 HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的 内存空间总是固定的、并且是很小 的,为大数据而生的,不然的话用集合就好了。 在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。 这什么概念?举个例子给大家对比一下。 用 Java 语言来说,一般 long 类型占用 8 字节,而 1 字节有 8 位,即:1 byte = 8 bit,即 long 数据类型最大可以表示的数是:2^63-1。对应上面的2^64个数,假设此时有2^63-1这么多个数,从 0 ~ 2^63-1,按照long以及1k = 1024 字节的规则来计算内存总数,就是:((2^63-1) * 8/1024)K,这是很庞大的一个数,存储空间远远超过12K,而 HyperLogLog 却可以用 12K 就能统计完。 内部实现 HyperLogLog 的实现涉及到很多数学问题,太费脑子了,我也没有搞懂,如果你想了解一下,课下可以看看这个:HyperLogLog 常见命令 HyperLogLog 命令很少,就三个,所以功能很简单,就是统计去重后的数量。 # 添加指定元素到 HyperLogLog 中 PFADD key element [element ...] # 返回给定 HyperLogLog 的基数估算值。 PFCOUNT key [key ...] # 将多个 HyperLogLog 合并为一个 HyperLogLog PFMERGE destkey sourcekey [sourcekey ...] 应用场景 百万级网页 UV 计数 Redis HyperLogLog 优势在于只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。 所以,非常适合统计百万级以上的网页 UV 的场景。 在统计 UV 时,你可以用 PFADD 命令(用于向 HyperLogLog 中添加新元素)把访问页面的每个用户都添加到 HyperLogLog 中。 PFADD page1:uv user1 user2 user3 user4 user5 接下来,就可以用 PFCOUNT 命令直接获得 page1 的 UV 值了,这个命令的作用就是返回 HyperLogLog 的统计结果。 PFCOUNT page1:uv 不过,有一点需要你注意一下,HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。 这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型
-
Redis BitMap指南和应用 - 详解和教程 介绍 Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。 由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。 内部实现 Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。 String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组 常用命令 bitmap 基本操作 # 设置值,其中value只能是 0 和 1 SETBIT key offset value # 获取值 GETBIT key offset # 获取指定范围内值为 1 的个数 # start 和 end 以字节为单位 BITCOUNT key start end bitmap 运算操作 # BitMap间的运算 # operations 位移操作符,枚举值 AND 与运算 & OR 或运算 | XOR 异或 ^ NOT 取反 ~ # result 计算的结果,会存储在该key中 # key1 … keyn 参与运算的key,可以有多个,空格分割,not运算只能一个key # 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0。返回值是保存到 destkey 的字符串的长度(以字节byte为单位),和输入 key 中最长的字符串长度相等。 BITOP [operations] [result] [key1] [keyn…] # 返回指定key中第一次出现指定value(0/1)的位置 BITPOS [key] [value] 应用场景 Bitmap 类型非常适合二值状态统计的场景,这里的二值状态就是指集合元素的取值就只有 0 和 1 两种,在记录海量数据时,Bitmap 能够有效地节省内存空间。 签到统计 在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。 签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。 假设我们要统计 ID 100 的用户在 2022 年 6 月份的签到情况,就可以按照下面的步骤进行操作。 第一步,执行下面的命令,记录该用户 6 月 3 号已签到。 SETBIT uid:sign:100:202206 2 1 第二步,检查该用户 6 月 3 日是否签到。 GETBIT uid:sign:100:202206 2 第三步,统计该用户在 6 月份的签到次数。 BITCOUNT uid:sign:100:202206 这样,我们就知道该用户在 6 月份的签到情况了。 如何统计这个月首次打卡时间呢? Redis 提供了 BITPOS key bitValue [start] [end]指令,返回数据表示 Bitmap 中第一个值为 bitValue 的 offset 位置。 在默认情况下, 命令将检测整个位图, 用户可以通过可选的 start 参数和 end 参数指定要检测的范围。所以我们可以通过执行这条命令来获取 userID = 100 在 2022 年 6 月份首次打卡日期: BITPOS uid:sign:100:202206 1 需要注意的是,因为 offset 从 0 开始的,所以我们需要将返回的 value + 1 。 判断用户登陆态 Bitmap 提供了 GETBIT、SETBIT 操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。 只需要一个 key = login_status 表示存储用户登陆状态集合数据, 将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过 GETBIT判断对应的用户是否在线。 50000 万 用户只需要 6 MB 的空间。 假如我们要判断 ID = 10086 的用户的登陆情况: 第一步,执行以下指令,表示用户已登录。 SETBIT login_status 10086 1 第二步,检查该用户是否登陆,返回值 1 表示已登录。 GETBIT login_status 10086 第三步,登出,将 offset 对应的 value 设置成 0 SETBIT login_status 10086 0 连续签到用户总数 如何统计出这连续 7 天连续打卡用户总数呢? 我们把每天的日期作为 Bitmap 的 key,userId 作为 offset,若是打卡则将 offset 位置的 bit 设置成 1。 key 对应的集合的每个 bit 位的数据则是一个用户在该日期的打卡记录。 一共有 7 个这样的 Bitmap,如果我们能对这 7 个 Bitmap 的对应的 bit 位做 『与』运算。同样的 UserID offset 都是一样的,当一个 userID 在 7 个 Bitmap 对应对应的 offset 位置的 bit = 1 就说明该用户 7 天连续打卡。 结果保存到一个新 Bitmap 中,我们再通过 BITCOUNT 统计 bit = 1 的个数便得到了连续打卡 7 天的用户总数了。 Redis 提供了 BITOP operation destkey key [key ...]这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。 operation 可以是 and、OR、NOT、XOR。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0 。空的 key 也被看作是包含 0 的字符串序列。 假设要统计 3 天连续打卡的用户数,则是将三个 bitmap 进行 AND 操作,并将结果保存到 destmap 中,接着对 destmap 执行 BITCOUNT 统计,如下命令: # 与操作 BITOP AND destmap bitmap:01 bitmap:02 bitmap:03 # 统计 bit 位 = 1 的个数 BITCOUNT destmap 即使一天产生一个亿的数据,Bitmap 占用的内存也不大,大约占 12 MB 的内存(10^8/8/1024/1024),7 天的 Bitmap 的内存开销约为 84 MB。同时我们最好给 Bitmap 设置过期时间,让 Redis 删除过期的打卡数据,节省内存。
-
详细的Redis安装教程 | 如何安装Redis 单机安装 安装依赖 Redis是基于C语言编写的,因此首先需要安装RedisF所需要的gcc依赖 yum install -y gcc tcl 上传安装包并且解压 去官网下载安装包到/usr/local/src目录, cd /usr/local/src wget https://download.redis.io/releases/redis-6.2.7.tar.gz tar -zxvf redis-6.2.7.tar.gz 然后解压进入安装文件夹目录,然后安装到/usr/local/redis目录 cd redis-6.2.7 make make test make PREFIX=/usr/local/redis install 配置 进入源码目录,复制配置文件到安装目录 cd /usr/local/src/redis-6.2.7 cp /usr/local/src/redis-6.2.7/redis.conf /usr/local/redis/ 然后设置一些基本的配置 cd /usr/local/redis/ vim redis.conf 修改为 # 修改监听地址为所有id,线上不可以这样 bind 0.0.0.0 # 守护进程方式运行 dameonize yes # 设置需要密码 requirepass 123456 # 端口 port 6379 # 工作目录,默认是当前目录,也就是运行redis-server命令时候的目录,日志、持久化等文件会保存在这个目录 # 改成绝对路径!!! dir /usr/local/redis6.2 #数据库教量,设置为1,代表只使用1个库,默认有16个库,编号0~15 databases 16 #设置redis能够使用的最大内存 maxmemory 512mb #日志文件,默以为空,不记录日志,可以指定日志文件名logfile "redis.log" #会产生在dir指定的目录 logfile "redis.log" 添加到服务 修改解压目录的/usr/local/src/redis-6.2.7/utils/redis_init_script脚本 REDISPORT=6379 # 执行目录 EXEC=/usr/local/redis/bin/redis-server CLIEXEC=/usr/local/redis/bin/redis-cli PIDFILE=/var/run/redis_${REDISPORT}.pid # 配置文件,如果是多端口的话,可以修改文件名称为端口号 CONF="/usr/local/redis/redis.conf" 复制到init.d目录 cp /usr/local/src/redis-6.2.7/utils/redis_init_script /etc/init.d/redis6.2 添加服务 chkconfig redis6.2 on 启动 因为配置文件已经配置为守护进程启动,不然默认是前台启动 cd /usr/local/redis/ ./bin/redis-server redis.conf 这种方式启动的话,可以用kill命令停止。 不过前面加入了服务,所以可以用服务命令启动停止 service redis6.2 start service redis6.2 stop 客户端 启动参数: -h 指定主机,可以省略,默认是127.0.0.1 -p 端口开业省略,默认是6379 redis-cli -h 127.0.0.1 -p 6739 -a 123456
-
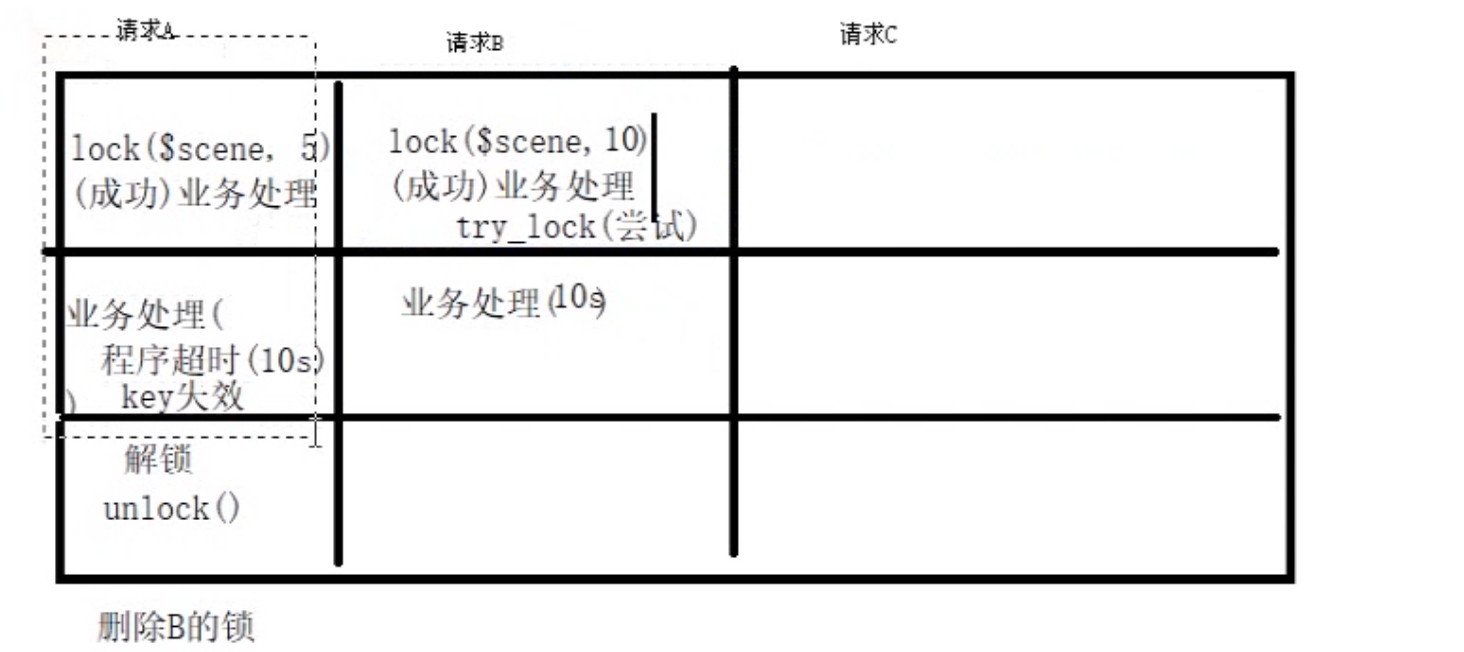
Redis分布式锁解决方案:抢票、秒杀并发问题优化 概述 锁是保护一些共享的资源,这个资源通常会发生竞争。 场景 以下代码,如果5秒内有多个请求,就会超卖 $redis = new Redis(); $redis->connect('127.0.0.1', 6379); $num = $redis->get('num'); if ($num < 1) { // 两个客户端并发执行的时候,因为前面的库存还没执行到增加num sleep(5);// 模拟购买逻辑时间 $store = $redis->incr('num'); var_dump($store); } else { echo '已经卖完'; } 单机锁 上述的问题,我们可以用文件锁的方法,不过这文件通常只能放在一台机器中,如果有多台机器的话,就会有问题 if (flock($fp,LOCK_EX)) {// 加悲观排他锁阻塞等待 fwrite($fp,"lock success\n"); sleep(5); flock($fp,LOCK_UN);// 解锁 } else { echo "文件被其它进程占用"; } fclose($fp); 我们还可以通过数据库的行锁进行锁定 select * from erp_storage where id = 1 for update; 分布式锁 分布式锁的基本条件: 互斥性。在任意时刻,只有一个客户端能持有锁。 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。 铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了,即不能误解锁。例如下例中,请求a的业务逻辑时间太长,导致锁缓存过期失效,请求b就获取到了锁,然后这个时候请求a业务逻辑执行完成了,要释放锁了,就把请求b的锁给释放了 以下代码符合上述条件 <?php class Lock { private $redis; private $clientUniqueId; public function __construct() { $this->redis = new Redis(); $this->redis->connect('127.0.0.1', 6379); } public function lock($scene = '小米11库存', $expire = 5, $retry = 5, $sleep = 1) { $res = false; while ($retry > 0) { // 获取锁,要多次尝试,不能一次返回 $value = session_create_id(); // 获取唯一字符 $this->clientUniqueId = $value; $res = $redis->set($scene, $value, [ 'NX', // 不存在则设置,也就是没有锁就加锁 'EX' => $expire, // 防止死锁,万一加锁后没有解锁,会自动释放锁 ]); if ($res) { // 加锁成功后返回 break; } echo "尝试获取锁"; sleep($sleep); $retry--; } } public function unlock($scene) { // $value = $this->redis->get($scene); // if ($value == $this->clientUniqueId) {// 不能删除掉别人的锁 // 正好锁过期了,这个时候,客户端b能获取到锁,这里就会把客户端b的锁给删除 // sleep(5);//极端情况下,可能这里会有io阻塞,导致把别人的锁给删除了 // $this->redis->del($scene); // } // KEYS类似全局变量 $script = <<<LUA local key=KEYS[1] local value=ARGV[1] if(redis.call('get','key') == value) then return redis.call('del',key) end LUA; // 为了保证原子性,get和del一起执行,不能分开执行 $this->redis->eval($script,[$scene,$this->clientUniqueId]); } }
-
-
Redis哈希教程-理解和使用HASH数据结构 介绍 Hash 是一个键值对(key - value)集合,其中 value 的形式如: value=[{field1,value1},...{fieldN,valueN}]。Hash 特别适合用于存储对象。 String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便: Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD: 内部实现 Hash 类型的底层数据结构是由压缩列表或哈希表实现的: 如果哈希类型元素个数小于 512 个(默认值,可由 hash-max-ziplist-entries 配置),所有值小于 64 字节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构; 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的 底层数据结构。 在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。 哈希表 哈希表是一种保存键值对(key-value)的数据结构。 哈希表中的每一个 key 都是独一无二的,程序可以根据 key 查找到与之关联的 value,或者通过 key 来更新 value,又或者根据 key 来删除整个 key-value等等。 在讲压缩列表的时候,提到过 Redis 的 Hash 对象的底层实现之一是压缩列表(最新 Redis 代码已将压缩列表替换成 listpack)。Hash 对象的另外一个底层实现就是哈希表。 哈希表优点在于,它能以 O(1) 的复杂度快速查询数据。怎么做到的呢?将 key 通过 Hash 函数的计算,就能定位数据在表中的位置,因为哈希表实际上是数组,所以可以通过索引值快速查询到数据。 但是存在的风险也是有,在哈希表大小固定的情况下,随着数据不断增多,那么哈希冲突的可能性也会越高。 解决哈希冲突的方式,有很多种。 Redis 采用了「链式哈希」来解决哈希冲突,在不扩容哈希表的前提下,将具有相同哈希值的数据串起来,形成链接起,以便这些数据在表中仍然可以被查询到。 接下来,详细说说哈希表。 哈希表结构设计 Redis 的哈希表结构如下: typedef struct dictht { //哈希表数组 dictEntry **table; //哈希表大小 unsigned long size; //哈希表大小掩码,用于计算索引值 unsigned long sizemask; //该哈希表已有的节点数量 unsigned long used; } dictht; 可以看到,哈希表是一个数组(dictEntry **table),数组的每个元素是一个指向「哈希表节点(dictEntry)」的指针。 哈希表节点的结构如下: typedef struct dictEntry { //键值对中的键 void *key; //键值对中的值 union { void *val; uint64_t u64; int64_t s64; double d; } v; //指向下一个哈希表节点,形成链表 struct dictEntry *next; } dictEntry; dictEntry 结构里不仅包含指向键和值的指针,还包含了指向下一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对链接起来,以此来解决哈希冲突的问题,这就是链式哈希。 另外,这里还跟你提一下,dictEntry 结构里键值对中的值是一个「联合体 v」定义的,因此,键值对中的值可以是一个指向实际值的指针,或者是一个无符号的 64 位整数或有符号的 64 位整数或double 类的值。这么做的好处是可以节省内存空间,因为当「值」是整数或浮点数时,就可以将值的数据内嵌在 dictEntry 结构里,无需再用一个指针指向实际的值,从而节省了内存空间。 哈希冲突 哈希表实际上是一个数组,数组里多每一个元素就是一个哈希桶。 当一个键值对的键经过 Hash 函数计算后得到哈希值,再将(哈希值 % 哈希表大小)取模计算,得到的结果值就是该 key-value 对应的数组元素位置,也就是第几个哈希桶。 什么是哈希冲突呢? 举个例子,有一个可以存放 8 个哈希桶的哈希表。key1 经过哈希函数计算后,再将「哈希值 % 8 」进行取模计算,结果值为 1,那么就对应哈希桶 1,类似的,key9 和 key10 分别对应哈希桶 1 和桶 6。 此时,key1 和 key9 对应到了相同的哈希桶中,这就发生了哈希冲突。 因此,当有两个以上数量的 kay 被分配到了哈希表中同一个哈希桶上时,此时称这些 key 发生了冲突。 链式哈希 Redis 采用了「链式哈希」的方法来解决哈希冲突。 链式哈希是怎么实现的? 实现的方式就是每个哈希表节点都有一个 next 指针,用于指向下一个哈希表节点,因此多个哈希表节点可以用 next 指针构成一个单项链表,被分配到同一个哈希桶上的多个节点可以用这个单项链表连接起来,这样就解决了哈希冲突。 还是用前面的哈希冲突例子,key1 和 key9 经过哈希计算后,都落在同一个哈希桶,链式哈希的话,key1 就会通过 next 指针指向 key9,形成一个单向链表。 不过,链式哈希局限性也很明显,随着链表长度的增加,在查询这一位置上的数据的耗时就会增加,毕竟链表的查询的时间复杂度是 O(n)。 要想解决这一问题,就需要进行 rehash,也就是对哈希表的大小进行扩展。 接下来,看看 Redis 是如何实现的 rehash 的。 rehash 哈希表结构设计的这一小节,我给大家介绍了 Redis 使用 dictht 结构体表示哈希表。不过,在实际使用哈希表时,Redis 定义一个 dict 结构体,这个结构体里定义了两个哈希表(ht[2])。 typedef struct dict { … //两个Hash表,交替使用,用于rehash操作 dictht ht[2]; … } dict; 之所以定义了 2 个哈希表,是因为进行 rehash 的时候,需要用上 2 个哈希表了。 在正常服务请求阶段,插入的数据,都会写入到「哈希表 1」,此时的「哈希表 2 」 并没有被分配空间。 随着数据逐步增多,触发了 rehash 操作,这个过程分为三步: 给「哈希表 2」 分配空间,一般会比「哈希表 1」 大 2 倍; 将「哈希表 1 」的数据迁移到「哈希表 2」 中; 迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备。 为了方便你理解,我把 rehash 这三个过程画在了下面这张图: 这个过程看起来简单,但是其实第二步很有问题,如果「哈希表 1 」的数据量非常大,那么在迁移至「哈希表 2 」的时候,因为会涉及大量的数据拷贝,此时可能会对 Redis 造成阻塞,无法服务其他请求。 渐进式 rehash 为了避免 rehash 在数据迁移过程中,因拷贝数据的耗时,影响 Redis 性能的情况,所以 Redis 采用了渐进式 rehash,也就是将数据的迁移的工作不再是一次性迁移完成,而是分多次迁移。 渐进式 rehash 步骤如下: 给「哈希表 2」 分配空间; 在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上; 随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点会把「哈希表 1 」的所有 key-value 迁移到「哈希表 2」,从而完成 rehash 操作。 这样就巧妙地把一次性大量数据迁移工作的开销,分摊到了多次处理请求的过程中,避免了一次性 rehash 的耗时操作。 在进行渐进式 rehash 的过程中,会有两个哈希表,所以在渐进式 rehash 进行期间,哈希表元素的删除、查找、更新等操作都会在这两个哈希表进行。 比如,查找一个 key 的值的话,先会在「哈希表 1」 里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。 另外,在渐进式 rehash 进行期间,新增一个 key-value 时,会被保存到「哈希表 2 」里面,而「哈希表 1」 则不再进行任何添加操作,这样保证了「哈希表 1 」的 key-value 数量只会减少,随着 rehash 操作的完成,最终「哈希表 1 」就会变成空表。 rehash 触发条件 介绍了 rehash 那么多,还没说什么时情况下会触发 rehash 操作呢? rehash 的触发条件跟负载因子(load factor)有关系。 负载因子可以通过下面这个公式计算: 触发 rehash 操作的条件,主要有两个: 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。 listpack quicklist 虽然通过控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来减少连锁更新带来的性能影响,但是并没有完全解决连锁更新的问题。 因为 quicklistNode 还是用了压缩列表来保存元素,压缩列表连锁更新的问题,来源于它的结构设计,所以要想彻底解决这个问题,需要设计一个新的数据结构。 于是,Redis 在 5.0 新设计一个数据结构叫 listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。 我看了 Redis 的 Github,在最新 6.2 发行版本中,Redis Hash 对象、ZSet 对象的底层数据结构的压缩列表还未被替换成 listpack,而 Redis 的最新代码(还未发布版本)已经将所有用到压缩列表底层数据结构的 Redis 对象替换成 listpack 数据结构来实现,估计不久将来,Redis 就会发布一个将压缩列表为 listpack 的发行版本。 listpack 结构设计 listpack 采用了压缩列表的很多优秀的设计,比如还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。 我们先看看 listpack 结构: listpack 头包含两个属性,分别记录了 listpack 总字节数和元素数量,然后 listpack 末尾也有个结尾标识。图中的 listpack entry 就是 listpack 的节点了。 每个 listpack 节点结构如下: 主要包含三个方面内容: encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码; data,实际存放的数据; len,encoding+data的总长度; 可以看到,listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。 常用命令 # 存储一个哈希表key的键值 HSET key field value # 获取哈希表key对应的field键值 HGET key field # 在一个哈希表key中存储多个键值对 HMSET key field value [field value...] # 批量获取哈希表key中多个field键值 HMGET key field [field ...] # 删除哈希表key中的field键值 HDEL key field [field ...] # 返回哈希表key中field的数量 HLEN key # 返回哈希表key中所有的键值 HGETALL key # 为哈希表key中field键的值加上增量n HINCRBY key field n # 获取一个hash类型的key中的所有的field HKEYS heima:user:4 # 获取一个hash类型的key中的所有的value HVALS heima:user:4 # 如果没有sex字段,就添加 HSETNX heima:user:4 sex woman 应用场景 缓存对象 Hash 类型的 (key,field, value) 的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。 在介绍 String 类型的应用场景时有所介绍,String + Json也是存储对象的一种方式,那么存储对象时,到底用 String + json 还是用 Hash 呢? 一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。 购物车 以用户 id 为 key,商品 id 为 field,商品数量为 value,恰好构成了购物车的3个要素,如下图所示 涉及的命令如下: 添加商品:HSET cart:{用户id} {商品id} 1 添加数量:HINCRBY cart:{用户id} {商品id} 1 商品总数:HLEN cart:{用户id} 删除商品:HDEL cart:{用户id} {商品id} 获取购物车所有商品:HGETALL cart:{用户id} 当前仅仅是将商品ID存储到了Redis 中,在回显商品具体信息的时候,还需要拿着商品 id 查询一次数据库,获取完整的商品的信息。
-
Redis 无序集合Set | 详解与实用指南 介绍 Set 类型是一个无序并唯一的键值集合,它的存储顺序不会按照插入的先后顺序进行存储。 一个集合最多可以存储 2^32-1 个元素。概念和数学中个的集合基本类似,可以交集,并集,差集等等,所以 Set 类型除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。 有点类似hashset,只是没有vaule。 内部实现 Set 类型的底层数据结构是由哈希表或整数集合实现的 如果集合中的元素都是整数且元素个数小于 512 (默认值,set-maxintset-entries配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构; 如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。 常用命令 Set常用操作 # 往集合key中存入元素,元素存在则忽略,若key不存在则新建 SADD key member [member ...] # 从集合key中删除元素 SREM key member [member ...] # 获取集合key中所有元素 SMEMBERS key # 获取集合key中的元素个数 SCARD key # 判断member元素是否存在于集合key中 SISMEMBER key member # 从集合key中随机选出count个元素,元素不从key中删除 SRANDMEMBER key [count] # 从集合key中随机选出count个元素,元素从key中删除 SPOP key [count] Set运算操作 # 交集运算 SINTER key [key ...] # 将交集结果存入新集合destination中 SINTERSTORE destination key [key ...] # 并集运算 SUNION key [key ...] # 将并集结果存入新集合destination中 SUNIONSTORE destination key [key ...] # 差集运算 SDIFF key [key ...] # 将差集结果存入新集合destination中 SDIFFSTORE destination key [key ...] 应用场景 集合的主要几个特性,无序、不可重复、支持并交差等操作。 因此 Set 类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等,当我们存储的数据是无序并且需要去重的情况下,比较适合使用集合类型进行存储。 但是要提醒你一下,这里有一个潜在的风险。Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。 在主从集群中,为了避免主库因为 Set 做聚合计算(交集、差集、并集)时导致主库被阻塞,我们可以选择一个从库完成聚合统计,或者把数据返回给客户端,由客户端来完成聚合统计 点赞 Set 类型可以保证一个用户只能点一个赞,这里举例子一个场景,key 是文章id,value 是用户id。 uid:1 、uid:2、uid:3 三个用户分别对 article:1 文章点赞了 # uid:1 用户对文章 article:1 点赞 > SADD article:1 uid:1 (integer) 1 # uid:2 用户对文章 article:1 点赞 > SADD article:1 uid:2 (integer) 1 # uid:3 用户对文章 article:1 点赞 > SADD article:1 uid:3 (integer) 1 uid:1 取消了对 article:1 文章点赞。 > SREM article:1 uid:1 (integer) 1 获取 article:1 文章所有点赞用户 : > SMEMBERS article:1 1) "uid:3" 2) "uid:2" 获取 article:1 文章的点赞用户数量: > SCARD article:1 (integer) 2 判断用户 uid:1 是否对文章 article:1 点赞了: > SISMEMBER article:1 uid:1 (integer) 0 # 返回0说明没点赞,返回1则说明点赞了 共同关注 Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。 key 可以是用户id,value 则是已关注的公众号的id uid:1 用户关注公众号 id 为 5、6、7、8、9,uid:2 用户关注公众号 id 为 7、8、9、10、11 # uid:1 用户关注公众号 id 为 5、6、7、8、9 > SADD uid:1 5 6 7 8 9 (integer) 5 # uid:2 用户关注公众号 id 为 7、8、9、10、11 > SADD uid:2 7 8 9 10 11 (integer) 5 uid:1 和 uid:2 共同关注的公众号 # 获取共同关注 > SINTER uid:1 uid:2 1) "7" 2) "8" 3) "9" 给 uid:2 推荐 uid:1 关注的公众号 > SDIFF uid:1 uid:2 1) "5" 2) "6" 验证某个公众号是否同时被 uid:1 或 uid:2 关注: > SISMEMBER uid:1 5 (integer) 1 # 返回0,说明关注了 > SISMEMBER uid:2 5 (integer) 0 # 返回0,说明没关注 抽奖活动 存储某活动中中奖的用户名 ,Set 类型因为有去重功能,可以保证同一个用户不会中奖两次。 key为抽奖活动名,value为员工名称,把所有员工名称放入抽奖箱 : >SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark (integer) 5 如果允许重复中奖,可以使用 SRANDMEMBER 命令。 # 抽取 1 个一等奖: > SRANDMEMBER lucky 1 1) "Tom" # 抽取 2 个二等奖: > SRANDMEMBER lucky 2 1) "Mark" 2) "Jerry" # 抽取 3 个三等奖: > SRANDMEMBER lucky 3 1) "Sary" 2) "Tom" 3) "Jerry" 如果不允许重复中奖,可以使用 SPOP 命令。 # 抽取一等奖1个 > SPOP lucky 1 1) "Sary" # 抽取二等奖2个 > SPOP lucky 2 1) "Jerry" 2) "Mark" # 抽取三等奖3个 > SPOP lucky 3 1) "John" 2) "Sean" 3) "Lindy" 黑名单白名单 黑名单/白名单,有业务出于安全性方面的考虑,需要设置用户黑名单、ip 黑名单、设备黑名单等,set 类型适合存储这些黑名单数据,sismember命令可用于判断用户、ip、设备是否处于黑名单之中。 随机展示 随机展示,通过 srandmember 随机返回对应的内容,像一些首页获取动态内容可以这么玩。 用户标签 给用户添加标签,跟我们上面的例子一样。一个人对应多个不同的标签。