搜索到
17
篇与
的结果
-
 Go 语言运算符详解与应用 概述 同一类型的变量才可以进行运算! 算数运算符 算数运算符和其它编程语言一样,+、-、*、/加减乘除,%求余。++(自增)和 --(自减)在 Go 语言中是单独的语句,并不是运算符 func main() { a := 1 a++ fmt.Println(a) // a是2 a++1 // 这个是不行的,因为不是运算符 fmt.Println(a++)// 这个也是不行的,因为是语句 } 关系运算符 断言左右两个值是否满足关系,是的话返回true,否的话返回false,和其它语言一样有==、!=、>、>=、<、<=。 逻辑运算符 和其它语言一样有&&、||、!。 位运算符 和其它语言一样有: &,位与 |,位或 ^,位异或 <<,左移 n 位就是乘以 2 的 n 次方 >>,右移 n 位就是除以 2 的 n 次方 赋值运算符 =,简单的赋值运算符,将一个表达式的值赋给一个左值 +=,相加后赋值 -=,相减后赋值 *=,相乘后赋值 /=,相除后赋值 %=,求余后再赋值 <<=,左移后赋值 >>=,右移后赋值 &=,按位与后赋值 |=,按位或后赋值 ^=,按位异或后赋值
Go 语言运算符详解与应用 概述 同一类型的变量才可以进行运算! 算数运算符 算数运算符和其它编程语言一样,+、-、*、/加减乘除,%求余。++(自增)和 --(自减)在 Go 语言中是单独的语句,并不是运算符 func main() { a := 1 a++ fmt.Println(a) // a是2 a++1 // 这个是不行的,因为不是运算符 fmt.Println(a++)// 这个也是不行的,因为是语句 } 关系运算符 断言左右两个值是否满足关系,是的话返回true,否的话返回false,和其它语言一样有==、!=、>、>=、<、<=。 逻辑运算符 和其它语言一样有&&、||、!。 位运算符 和其它语言一样有: &,位与 |,位或 ^,位异或 <<,左移 n 位就是乘以 2 的 n 次方 >>,右移 n 位就是除以 2 的 n 次方 赋值运算符 =,简单的赋值运算符,将一个表达式的值赋给一个左值 +=,相加后赋值 -=,相减后赋值 *=,相乘后赋值 /=,相除后赋值 %=,求余后再赋值 <<=,左移后赋值 >>=,右移后赋值 &=,按位与后赋值 |=,按位或后赋值 ^=,按位异或后赋值 -
Go 语言包管理 | 专业指导和最佳实践 概述 包是多个源代码的集合,是一种高级的代码复用方案,一个包可以简单理解为一个存放 .go 文件的文件夹,该文件夹下面的所有 go 文件都要在代码的第一行添加如下代码,声明该文件归属的包 // 这个包名其实就是命名空间 package 包名 注意事项: 一个文件夹下的文件只能归属一个 package,同样一个 package 的文件不能在多个文件夹下,不过实际情况也有可能一个文件夹下有多个包,例如 mysql 目录下有:mysql 包和 mysql_test 包,mysql_test 包专门用于测试 包名可以不和文件夹的名字一样(通常要一样的),包名不能包含 - 符号 包名为 main 的包为应用程序的入口包,这种包编译后会得到一个可执行文件,而编译不包含 main 包的源代码则不会得到可执行文件 测试包:名称以_test. go 结尾的文件,包含此处所述的 TestXxx 函数,_test.go 文件放在与正在测试的文件包相同的包中。该文件将从常规软件包构建中排除,但在运行“go test”命令时将包含该文件 不同文件夹下的同个包名称,应该属于不同的包! 一个包里,不同的职责放在不同的文件里,例如 MySQL 驱动包要解析 dsn,则把 dsn 放在单独的文件里,暴露一个方法出来就可以了,包的常量也可以单独放在一个文件里,然后一般一个文件就只有一个结构体,代表一个类 一个文件夹就是一个包,包的名称可以和文件夹的名称不一样,建议写成和文件夹的名称一样。 同一个文件夹下的可以有多个源文件,不过每个源文件的包名称必须一样 同一个包里的方法可以直接调用 文件夹底下,还可以有文件夹,属于不同的包 包的分类 main包,如果是main包,则必须有一个main函数,此函数就是项目的入口。如果是main包,并且有main函数,则编译的时候会生成可执行文件。如果不是main包,编译的时候会在pkg目录,生成包名.a的包文件供其他项目使用 非main包,用来将我们的代码按功能分类,分别放在不同的包和文件中,这样好编辑管理 需要注意的是:当我们的main包里有多个文件,main函数里调用其它文件里的方法,用goland的直接执行,会报错,因为goland的默认只会编译一个文件 这个时候需要改下配置 包导入 要在代码中引用其他包的内容,需要使用 import 关键字导入使用的包 // 查找方式见依赖管理的文章 import "导入路径" // 这样也可以,不过好像不推荐 import "./项目的相对路径" 注意事项: import 导入语句通常放在文件开头包声明语句的下面 导入路径只是一个目录,通常路径的最后一段的目录名称和包的名称一样,这样方便管理,如果不一样的话,需要声明包名称,例如 import 包名称 导入路径 导入的包名需要使用双引号包裹起来 文件位置查找规则,具体可以看 go依赖管理 Go 语言中禁止循环导入包,比如: a 导入 b,b 又导入 a 导入的包会被整合到编译的可执行文件中 导入的包没有使用,会导致编译错误 每个包的依赖包是独立的,要重复导入,不能 a 包导过依赖后,b 包就不导入了 导入的包是文件级别的,所以导入后,可以在同一个文件中被使用,但是如果同一包的其他文件没有导入的话,将不能使用 小提示 go 的依赖导入自带的和第三方的应该要空行分开,方便阅读,例如: import ( "context" "database/sql" "fmt" "net/url" _ "github.com/go-sql-driver/mysql" "github.com/gogf/gf/v2/frame/g" "github.com/gogf/gf/v2/util/gutil" "github.com/gogf/gf/v2/database/gdb" "github.com/gogf/gf/v2/errors/gcode" "github.com/gogf/gf/v2/errors/gerror" "github.com/gogf/gf/v2/text/gregex" ) 单行导入 import "包1" import "包2" 多行导入 import ( "包1" "包2" ) // 最好是按顺序包1,然后包2,这种先包2,再包1的idea会提示 import ( "包2" "包1" ) 包的可见性 包名标识符首字母大写,表示对外可见,对外可见通常需要写注释,以标识符开头,空格隔开 // Sum 是求两个整型的和 func Sum(x int,y int) int { return x + y } 标识符首字母小写,表示对外不可见,同一个包里多个源文件之间,是可以相互调用对方的函数、变量等 包别名 导入包名字冲突时候或者导入的包名字很长的时候,往往需要包的别名 // 单行的时候 import 别名 "包的路径" // 多行的时候 import ( "fmt" m "github.com/Q1mi/studygo/pkg_test" ) 如果别名是 . 的话,就可以直接使用其内容,而不用再添加 fmt,如 fmt. Println 可以直接写成 Println,一般不这么使用,因为会比较混乱 package main import ( . "fmt" ) func main() { Println("123") } 匿名导入 go 中如果只是导入包,而不使用的话就会报错,这个时候可以使用匿名包,为了防止报错,可以使用匿名导入包,主要是为了使用初始化的函数 import _ "包的路径" 匿名导入的包与其他方式导入的包一样都会被编译到可执行文件中 包的初始化函数 init () 通常包目录下有多个文件,执行的时候,会先对文件进行排序后执行: 包导入的时候自动执行 没有参数,也没有返回值 一个包可以有多个 int 函数,即一个源文件中函数名称为 init 的函数可以多个,名称可以重复,同一个包的 init 执行顺序,golang 没有明确定义,好像是按上下顺序,编程时要注意程序不要依赖这个执行顺序,不同文件里的,按文件的名称的顺序 单个包里执行顺序:首先全局声明(全局变量,全局常量声明),然后 init () 函数,最后是 mian () 函数 包 1 导入包 2 的时候,init ()函数执行顺序:首先执行包 2 里的 init (),然后执行包 1 里的 init () 包的执行逻辑 如上图所示,包的执行步骤是: 首先 main 包去找 pkg1 包 pkg1 包找 pkg2 包 pkg2 包找 pkg3 包 pkg3 包从上往下执行,并且执行 init 函数 然后回到 pkg2 包从上往下执行 以此类推... 需要注意的是: 所有 init 函数都在同⼀个 goroutine 内执⾏,这个不知道有啥用❓ 所有 init 函数结束后才会执⾏ main. main 函数 对同一个 package 中的不同文件,将文件名按字符串进行“从小到大”排序,之后顺序调用各文件中的 init () 函数 对同一个 go 文件的 init ( ) 调用顺序是从上到下的 同包下的不同 go 文件,按照文件名“从小到大”排序顺序执行,好像 idea 的目录下的文件已经是排序好的,所以在 idea 里就是从上往下执行 其他的包只有被 main 包 import 才会执行,按照 import 的先后顺序执行 一个包被其它多个包 import,但只能被初始化一次 main 包总是被最后一个初始化,因为它总是依赖别的包 包的类型 大致分为 4 种类型: import ( // Go 标准包 "fmt" // 第三方包 "github.com/spf13/pflag" // 匿名包 _ "github.com/jinzhu/gorm/dialects/mysql" // 内部包 "github.com/marmotedu/iam/internal/apiserver" ) Go 标准包:在 Go 源码目录下,随 Go 一起发布的包 第三方包:第三方提供的包,比如来自于 github. com 的包 匿名包:只导入而不使用的包。通常情况下,我们只是想使用导入包产生的副作用,即引用包级别的变量、常量、结构体、接口等,以及执行导入包的 init () 函数。 内部包:项目内部的包,位于项目目录下。
-
GoLang 原子操作详细教程 - 探索Go语言并发编程 概述 atomic 提供的原子操作能够确保任一时刻只能有一个goroutine对变量进行操作,善用 atomic 能够避免程序中出现大量的锁操作,应该是方法内部实现了锁操作。atomic常见操作有: 载入 比较并交换 交换 存储 增减 增减 atomic 包中提供了如下以Add为前缀的增减操作,对变量进行增加或者减少: func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) 需要注意的是,第一个参数必须是指针类型的值,通过指针变量可以获取被操作数在内存中的地址,确保同一时间只有一个goroutine能够进行操作。先来看一个例子: 分别用“锁”和原子操作来实现多个 goroutine 对同一个变量进行累加操作。 使用锁实现,可以保证每一个时刻保证只有一个协程可以拿到变量,并且对变量进行写的操作: func main() { var ( mux sync.Mutex total = 0 ) for i := 0; i < 10; i++ { go func() { for { mux.Lock() total += 1 mux.Unlock() time.Sleep(time.Millisecond) } }() } time.Sleep(time.Second) // 保证所有的协程都执行完毕 fmt.Println("The total number is", total) } 由于一直使用锁定的操作会很麻烦,所以我们可以使用 atomic 实现,也是没有问题的: func main() { var total int64 for i := 0; i < 10; i++ { go func() { for { atomic.AddInt64(&total, 1) // 应该类似事务,内部会对变量加锁 time.Sleep(time.Millisecond) } }() } time.Sleep(time.Second) fmt.Println("The total number is", total) } 载入 atomic 包中提供了如下以Load为前缀的载入操作,应该就是读的时候加读锁: func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) func LoadUint32(addr *uint32) (val uint32) func LoadUint64(addr *uint64) (val uint64) func LoadUintptr(addr *uintptr) (val uintptr) 载入操作能够保证原子的读变量的值,当读取的时候,任何其他 goroutine 都无法对该变量进行读写. 比较交换 该操作简称 CAS(Compare And Swap)。 这类操作的前缀为 CompareAndSwap ,比较新的值和旧的值是否相等,相等的话就交换,返回布尔值: func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) 该操作在进行交换前首先确保变量的值未被更改,即仍然保持参数 old 所记录的值,满足此前提下才进行交换操作。CAS的做法类似操作数据库时常见的乐观锁机制。 需要注意的是,当有大量的goroutine 对变量进行读写操作时,可能导致CAS操作无法成功,这时可以利用for循环多次尝试。 var value int64 func atomicAddOp(tmp int64) { for { oldValue := value if atomic.CompareAndSwapInt64(&value, oldValue, oldValue+tmp) { return } } } func main() { value = 10 atomicAddOp(1) fmt.Println(value) // 输出11 } 交换 此类操作直接交换,并且返回旧的值,的前缀为 Swap: func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) 相对于CAS,明显此类操作更为暴力直接,并不管变量的旧值是否被改变,直接赋予新值然后返回背替换的值。 func main() { var oldValue int32 oldValue = 10 fmt.Println(atomic.SwapInt32(&oldValue, 20), oldValue) // 10 20 } 存储 此类操作的前缀为 Store,这个操作没有任何的返回值,类似给变量写操作: func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) 在原子地存储某个值的过程中,任何 goroutine 都不会进行针对同一个值的读或写操作。 func main() { var oldValue int32 oldValue = 10 atomic.StoreInt32(&oldValue, 20) fmt.Println(oldValue) // 20 }
-
Go 语言中锁的使用 - 深度解析和实例教程 共享内存 我们知道,channel 可以在在多个 goroutine 之间进行通信,其实对于并发还有一种较为常用通信方式,那就是共享内存,这是因为每个协程函数里都可以访问到全局变量。首先我们来看一个例子: var name string func printName() { log.Println("name is", name) } func main() { name = "小明" go printName() // 输出小明 go printName() // 输出小明 time.Sleep(time.Second) name = "小红" go printName() // 输出小红 go printName() // 输出小红 time.Sleep(time.Second) } 可以看到在两个 goroutine 中我们都可以访问 name 这个变量,当修改它后,在不同的 goroutine 中都可以同时获取到最新的值。这就是一个最简单的通过共享变量(内存)的方式在多个 goroutine 进行通信的方式。 如上我们知道,对变量进行并行读问题不太大,但是对变量进行并行的写的时候如果不加锁就会出现问题: func main() { var ( wg sync.WaitGroup numbers []int ) for i := 0; i < 100; i++ { wg.Add(1) go func(i int) { numbers = append(numbers, i) wg.Done() }(i) } wg.Wait() fmt.Println("The numbers is", len(numbers)) } 上诉例子运行的之后,有的时候,输出的结果是是65,有的时候输出是80等等,反正输出的结果不固定,不符合预期结果100,可以看到当我们并发对同一个切片进行写操作的时候,会出现数据不一致的问题,这就是一个典型的共享变量的问题。 sync.Mutex互斥锁 针对这个问题我们可以使用 Mutex 锁(其它语言中也叫排他锁、写锁)来修复,sync.Mutex 一旦被锁住,其它的 Lock() 操作就无法再获取它的锁,只有通过 Unlock() 释放锁之后才能通过 Lock() 继续获取锁,从而保证数据的一致性。 另外需要注意,sync.Mutex 不区分读写锁,只有 Lock() 与 Lock() 之间才会导致阻塞的情况,如果在一个地方 Lock(),在另一个地方不 Lock() 而是直接修改或访问共享数据,这对于 sync.Mutex 类型来说是允许的,因为 mutex 不会和 goroutine 进行关联。例如: func main() { var ( wg sync.WaitGroup numbers []int mux sync.Mutex ) for i := 0; i < 100; i++ { wg.Add(1) go func(i int) { mux.Lock() numbers = append(numbers, i) mux.Unlock() wg.Done() }(i) } wg.Wait() fmt.Println("The numbers is", len(numbers)) } 修改过后,我们再次运行代码,可以看到最后的 numbers 的数量始终是100个了。 可以使用 TryLock 来不阻塞判断是否被锁住 // serverAutoUnregisterLocker 防止本任务还没执行完成,下个任务又开始,拖垮系统 var serverAutoUnregisterLocker sync.Mutex func Run() { ctx := context.Background() tqtlog.Info(ctx, fmt.Sprintf("auto unregister cron job start exec")) if serverAutoUnregisterLocker.TryLock() { defer serverAutoUnregisterLocker.Unlock() err := a.service.AutoUnregisterCronJob(ctx) if err != nil { tqtlog.Error(ctx, fmt.Sprintf(`AutoUnregisterCronJob exec failed, err:%v`, err)) } } else { tqtlog.Warn(ctx, fmt.Sprintf("AutoUnregisterCronJob 获取锁失败,存在任务正在执行")) } tqtlog.Info(ctx, fmt.Sprintf("auto unregister cron job exec end")) } sync.RWMutex读写互斥锁 sync.Mutex 是互斥锁,只有一个信号标量;在 Go 中还有一种读写锁 sync.RWMutex,对于我们的共享对象,如果可以分离出读和写两个互斥信号的情况,可以考虑使用它来提高读的并发性能。 RWMutex 是基于 Mutex 的,在 Mutex 的基础之上增加了读、写的信号量,并使用了类似引用计数的读锁数量: 读锁与读锁兼容,读锁与写锁互斥,写锁与写锁互斥,只有在锁释放后才可以继续申请互斥的锁: 可以同时申请多个读锁 有读锁时申请写锁将阻塞,有写锁时申请读锁将阻塞 只要有写锁,后续申请读锁和写锁都将阻塞 有以下几个方法: func (rw *RWMutex) Lock() func (rw *RWMutex) RLock() func (rw *RWMutex) RLocker() Locker func (rw *RWMutex) RUnlock() func (rw *RWMutex) Unlock() Lock() 和 Unlock() 用于申请和释放写锁;RLock() 和 RUnlock() 用于申请和释放读锁,一次 RUnlock() 操作只是对读锁数量减1,即减少一次读锁的引用计数;如果不存在写锁,则 Unlock() 引发 panic,如果不存在读锁,则 RUnlock() 引发 panic;RLocker() 用于返回一个实现了 Lock() 和 Unlock() 方法的 Locker 接口。 由于读锁之间是可以没有阻塞的,所以效率会比较高,如下所示: func main() { var ( mux sync.Mutex state1 = map[string]int{ "a": 65, } muxTotal uint64 rw sync.RWMutex state2 = map[string]int{ "a": 65, } rwTotal uint64 ) for i := 0; i < 10; i++ { go func() { for { mux.Lock() _ = state1["a"] mux.Unlock() atomic.AddUint64(&muxTotal, 1) } }() } for i := 0; i < 10; i++ { go func() { for { rw.RLock() _ = state2["a"] rw.RUnlock() atomic.AddUint64(&rwTotal, 1) } }() } time.Sleep(time.Second) fmt.Println("sync.Mutex readOps is", muxTotal) fmt.Println("sync.RWMutex readOps is", rwTotal) } 运行代码,可以得到以下结果,明显看到同样对变量进行读的话,读锁的效率比写锁高的多: sync.Mutex readOps is 485 9713 sync.RWMutex readOps is 359 94874
-
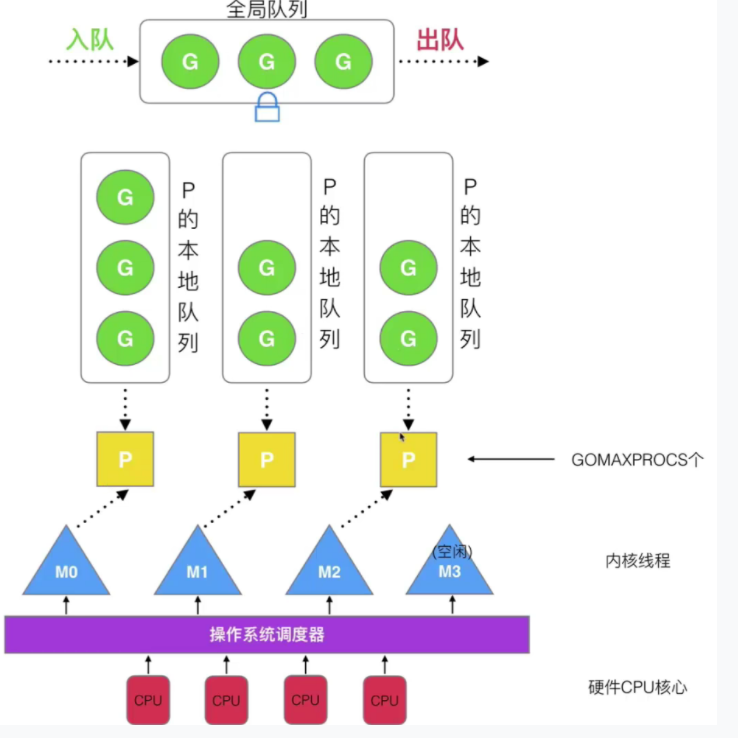
Go 语言中的 Goroutine - 轻松理解并掌握协程 概述 当代计算机的多进程、多线程模型 现在计算机的 cpu 核心数是有限的,比如 8 核心 cpu,同一时刻只能并行运行 8 个进程。而同一时间操作系统上要运行的程序要远远多于 cpu 的核心数。面对这个问题,操作系统的解决办法是不停的切换进程来执行,每个进程占用一小段时间片。 由于进程拥有太多的资源(虚拟内存占用 4Gb),进程的创建、切换、销毁会占用很长的时间。线程虽然占用的资源少了一点(也要占用 4MB),但是多线程开发会比较复杂,开发者要考虑很多同步竞争问题,比如锁,资源竞争。 由于进程和线程的切换成本高,当进程和线程的数量比较多的时候,会导致 cpu 很大一部分时间都浪费在切换进程和线程上,没有真正的用在执行逻辑程序上。 引入协程模型 协程类似于线程,属于用户态的线程,系统的是线程是内核态的线程;用户态的比内核态的轻量(goroutine 只占用几 Kb),切换的执行的时候,比较快。 一个用户态线程,必须绑定一个内核态线程,内核态线程可以由协程调度创建。 线程和协程的区别是: 线程由 cpu 调度,是抢占式的 协程是用户动态调度的,是协作式的,一个协程让出 cpu 后才会执行下一个协程 GPM 调度器模型 GPM 的模型中: G 指的是 go 协程 goroutine P 是协程调度器 processer,G 是放在 P 里,然后 M 执行 P 里的 G M 是 machine,也就是线程,用于执行 G 在 go 中,线程是运行 goroutine 的实体,调度器是把 goroutine 分配到线程上执行。在 GPM 模型中,有几个重要的概念,如下图所示: 全局队列:存放等待运行的 G,可以被任意的 P 获取执行,相当于整个 GPM 模型里的共用资源,所以需要加入互斥锁 P 的本地队列:存放的也是等待执行的 G,但是存放的数量有限,最多 256 个。该队列里的 G 新建的 G,会优先放到本队列,如果本队列的 G 满了,再放到全局队列中,具体见下文 P 列表:在程序启动的时候创建,最多可以有 GOMAXPORCS 个 M 线程:线程是由 P 创建,要执行 G 的话,M 首先要绑定 P,从 P 的本地队列获取 G,如果 P 的本地队列为空,则尝试从全局队列获取一批 G,放到本地队列,全局队列再为空的话再从其他 P 的本地队列偷一半放到本地队列。 有关 p 和 m 的数量的问题 P 的个数是启动的时候,环境变量 $GOMAXPROCS 或 runtime 的 GOMAXPROCS() 方法决定的。也就是说,程序在运行的时候,只有 $GOMAXPROCS 个 goroutine 同时在运行。这个数量一般设置成内核的一半 M 的数量,由 Go 语言本身的限制决定的,Go 在启动的时候,会设置 M 的最大数量为 1 万个,但是操作系统很难支撑这么多的线程,所以这个限制忽略不计。runtime/deBug 中的 SetMaxThreads() 方法,可以设置 M 的最大数量。当一个 M 阻塞的时候,会创建新的 M。 总得来说,P 和 M 的数量没有绝对关系,一个 M 阻塞,P 会创建新的 M 或切换到其它空闲的 M 上。 GPM 的设计策略 复用线程 GMP 会对线程复用,避免频繁的创建和销毁线程,也就避免让线程闲着。 偷取机制 线程 M 绑定到 P,当一个 P 上没有可执行的 G 的时候,本 P 就会从其他 P 的本地队列上偷去一半的 G 到本队列执行。这样就不会导致空闲的 P 无事可做了。 移交机制 当 M 正在执行的 G 发生了阻塞,那么 P 就会和绑定的 M 发生分离,和一个空闲的 M 再次绑定,如果没有空闲的 M, P 新创建一个 M,这样就不会因为一个 G 阻塞,影响到队列上的其他 G 没法执行。 利用并行 通过 GOMAXPROCS 来设置 P 的数量,一般设置为核心数的一半,表示最多利用核心数的一半在并行的运行 抢占 go 中的协程,一个 goroutine 最多执行 10ms ,就会获取下一个可执行状态的 G 来执行。 全局 G 队列 当 P 去其他 P 的本地队列上偷不到 G 的时候,它可以从全局队列获取 G。 创建 goroutine 的流程 当我们在代码中执行 go func() 的时候,GPM 会进行哪些操作呢? 当创建协程后,G 会优先保存到 P 的本地队列中,当 P 的本地队列满了,就会保存到全局队列中。执行流程如下图的序号所示: 调度器的生命周期 在 GPM 里,还有两个比较重要的角色,分别是 M0 和 G0。 M0 线程 启动程序后编号为 0 的主线程 在全局命令 runtime.m() 中,不需要在 heap 堆上分配 负责执行初始化操作,和启动第一个 G 启动 1 个 G 后,M0 就和其他 M 一样了 G0 协程 每启动一个 M,创建第一个 goroutine 就是 G0 G0 负责调度 G G0 不指向任何一个可执行的函数 每个 M 都会有一个自己的 G0 在调度或者系统调度的时候,M 会切换到 G0,再通过 G0 取获取其他 G M0 和 G0 会放在全局空间 gpm 可视化 trace go tool trace 的方式 例如: import ( "fmt" "os" "runtime/trace" ) func main() { f, err := os.Create("trace.out") if err != nil { panic(err) } defer f.Close() err = trace.Start(f) if err != nil { panic(err) } defer trace.Stop() fmt.Println("hello world") } 运行完上面代码,会得到 trace. out 文件,可以用下列命令打开 go tool trace trace.out 然后浏览器打开 http://127.0.0.1:34646/trace , 可以得到下图: debug trace 如下例代码 package main import ( "fmt" "time" ) func main() { for i := 0; i < 5; i++ { time.Sleep(time.Second) fmt.Println("hello world") } } 执行下面命令,得到 main.exe go build main.go 然后执行 GODEBUG=schedtrace=1000 ./main.exe 输出 SCHED 0ms: gomaxprocs=16 idleprocs=14 threads=5 spinningthreads=1 idlethreads=0 runqueue=0 [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] SCHED 1007ms: gomaxprocs=16 idleprocs=16 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] hello world SCHED 2016ms: gomaxprocs=16 idleprocs=16 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] hello world SCHED 3018ms: gomaxprocs=16 idleprocs=16 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] hello world SCHED 4027ms: gomaxprocs=16 idleprocs=16 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] hello world SCHED 5030ms: gomaxprocs=16 idleprocs=16 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] hello world 上面输出的含义: SCHED: 代表本行是调度器的输出日志 0ms: 从程序启动,到输出这行日志的时间 gomaxprocs: 设置的 processor 的数量 idlprocs: 处于 idl 状态的 P 的数量,gomaxprocs-idlprocs=正在运行的协程的数量 threads:总的线程的数量,包括 M 和 go 里自用的一些内部线程 spinningthreads:处于自旋状态的 os 线程数量 idlethreads:出于 idle 转头的 os 线程数量 runqueue=0:全局队列中 G 的数量 [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] :为 16 个 P 的本地队列的 G 的数量 场景 场景 1:G1 创建 G2,G2 会存在那个队列 G1 使用 go func () 创建 G2,为了局部性,因为 G1 和 G2 所保存的内存和堆栈信息最为相同,切换成本比较低,所以 G2 优先加入到 G1 的本地队列 场景 2 :G1 执行完成后,如何获取新的 G2 当 G1 执行完成后,M1 上的 goroutine 切换到 G0,G0 就可以取获取 G2 (先从本地队列,然后从全局队列,最后从其他 P 的本地队列获取),然后切换到 G2 来执行。 场景 3:如果 P 的本地队列只能存放 4 个 G,G1 创建了 6 个 G,此时多出来的 1 个 G 放在哪里? 因为 P 上可以放下 4 个 G,所以 G2,G3,G4,G5 会放在 G1 的本地队列里,G6 会放在全局队列里,然后还会讲 G1 本地队列的前面一半放到 G2,G3 放到全局队列里,然后把 G4,G5 移到队列的头部。此时 G1 的本地队列只有 G4,G5。 需要注意的是:G2, G3, G5 会以乱序的方式放到全局队列里。 场景 4:线程空闲的时候,会和 P 分离,并且休眠,如何重新唤醒休眠的线程呢? 空闲的线程,操作系统不会立刻回收,而是休眠,当尝试创建一个 G 的时候,就会尝试从休眠线程中获取 M,然后 M 尝试去绑定可以被利用的 P,绑定完成后,M ,P,G0 组成自旋线程,G0 会去寻找 G 放到自己的本地队列里 场景 5:自旋线程从全局队列获取多少个 G n = min(全局队列的G数量/GOMAXPROCS+1,cap(P的本地队列)/2) 场景 6:全局队列已经没有 G 了,自旋线程需要从其他 P 的本地队列偷取多少个 G 从其他 G 的 P 那里偷去一半 G,放到自己的本地队列里。 场景 7:G1 如果发生了阻塞的系统调用,这时候会发生什么呢 如果 G1 发生了阻塞,那么相应的 M1 和 P1 就会立即解绑。 此时如果 P1 本地队列或者全局对了有 G 待执行,如果有休眠的进程,P1 会唤醒一个线程和 P1 绑定,没有空闲的线程的话,就会创建一个新的线程和 P1 绑定。 否则,P1 会加入空闲的 P 列表,等待 M 获取可用的 P 当 G1 的阻塞状态解除后,M1 会尝试获取之前记住的 P1,如果 P1 是可获取状态 (也就是说此时 P1 没有和其他 M 绑定,在空闲 P 列表中),M1 和 P1 会重新绑定,否则就会从空闲的 P 列表里寻找可以用的 P。如果找不到空闲的 P,则 G1 会被标记为可以运行状态,并且加入到全局队列中。然后 M1 因为没有 P 的绑定变成休眠状态,长时间的休眠,会被 GC 回收 Goroutine 编程 Goroutine 是 go 程序并发的执行体。 在程序启动的时候,只有一个 goroutine 调用 main 函数,叫做主 goroutine。新的 goroutine 需要用 go 语句创建,go 语句本身执行是立即完成: f() go f() 需要注意的是,当 main 函数返回的时候,所有的 goroutine 都会被暴力的直接终止退出。 func hello() { fmt.Println("2") } func main() { go hello() // 这个有时候不会打印,因为有时候main很快就结束了 fmt.Println("1") } 我们可以用 sync.WaitGroup 来解决父 goroutine 过早的退出的问题 var wg sync.WaitGroup func hello() { fmt.Println("2") wg.Done() } func main() { wg.Add(1) go hello() fmt.Println("1") wg.Wait() } 还可以通过同步通道来解决 func hello(ch chan int) { ch <- 0 fmt.Println("2") } func main() { ch := make(chan int) go hello(ch) <-ch fmt.Println("1") close(ch) } 如何在不修改原有函数的情况下,并行执行函数 可以用一个闭包嵌套以下 func hello() { fmt.Println("2") } func main() { ch := make(chan int) for i := 1; i < 5; i++ { // 嵌套一个闭包 go func() { hello() ch <- 1 }() } for i := 1; i < 5; i++ { <-ch } fmt.Println("1") close(ch) }
-
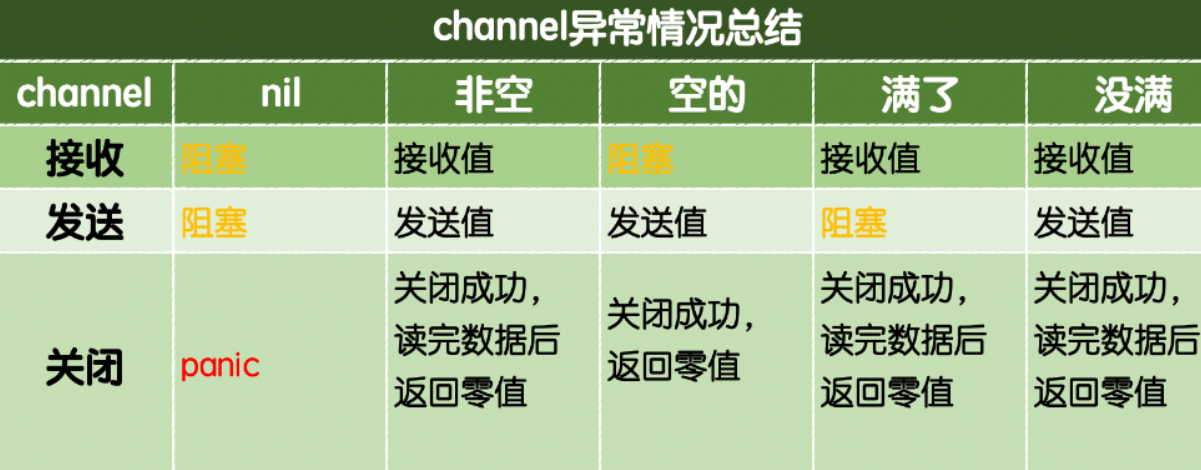
Go语言复合类型 - Channel详解 概述 Channel 是一种特殊的引用类型,中文直译一般叫做通道,是 goroutine 执行体之间进行通信的桥梁,可以实现一个 goroutine 发生特定的值到另外一个 goroutine。 每个通道都是一个具体类型的导管,叫做通道的元素类型。使用 make 函数创建一个通道 ch := make(chan int) 和 map 一样,通道是一个使用 make 创建的数据结构的引用。所以当复制,或者作为参数传递到一个函数的时候,复制的是引用,这样调用者和被调用者都引用同一份数据结构。 通道之间可以比较吗? 同一个类型的通道之间是可以用 == 进行比较的,当二者都是同一个底层的引用的时候,结果是 true。 通道还可以和 nil 进行比较 声明 可以通过 var 关键字进行定义 channel,由于 channel 是一种引用类型,所以 var 定义的并没有在内存种实例化,var 定义后的 channel 零值为 nil,还需要初始化化,比较麻烦,因此这种定义方式不常用。 var ch1 chan int // 声明一个传递整型的通道 var ch2 chan bool // 声明一个传递布尔型的通道 var ch3 chan []int // 声明一个传递int切片的通道 fmt.Println(ch1, ch2, ch3) // 输出<nil> <nil> <nil> 另外一种方式是通过 make 函数定义,定义之后就已经在内存中初始化了,这个方式比较常用 chInt := make(chan int) // 无缓冲 chBool := make(chan bool, 0) // 无缓冲 chStr := make(chan string, 2) // 容量为2的缓冲通道 以上两种声明 channel 的都是双向的,意味着可以向该 channel 可以发送数据并接收数据。"发送"和"接收"是 channel 的两个基本操作,统称为通信,可以通过箭头操作符书写 ch <- x // 发送 x <- ch // 接收 <-ch // 接收并且丢弃结果 通道的第三个个操作是关闭。它设置一个标志位来表明现在已经发送完毕,这个通道不会再发送新的值了。 close(ch) 关闭后的发送操作会导致宕机。 在已经关闭的通道进行接收操作,将获取已经发送的值,直到通道为空。这个时候对已关闭的空通道上进行接收,会立即返回零值。 关闭一个 nil 的通道也会导致宕机 关闭以一个已经关闭的通道也会导致宕机 通道缓冲 无缓冲通道 如下用 make 创建无缓冲通道 chInt := make(chan int) // 无缓冲 chBool := make(chan bool, 0) // 无缓冲 对无缓冲通道的发送操作,将会阻塞(相当于挂起休眠了),直到其他 goroutine 在对应的通道上执行接收操作(发送的 goroutine 再次被唤醒),这时候传值完成。相反,如果接收操作先执行,接收方的 goroutine 将阻塞,直到另一个 goroutine 在同一个通道上发送值。 因为无缓冲通道会导致发送和接收 goroutine 同步化,所以无缓冲通道也称作同步通道。这个也是它的一个重要特征。 无缓冲通道如何导致死锁? 当在一个 goroutine 中对同一个无缓冲的通道进行收发操作,就会导致死锁,因为收发都在同一协程,就会导致互相等待,导致死锁 func main() { ch := make(chan string) ch <- "ping" fmt.Println(<-ch) } 缓冲通道 缓冲通道有一个元素队列,队列长度可以在 make 的时候指定 // 队列的长度是2 ch := make(chan int, 2) 缓冲通道的发送操作,会在队列的尾部插入元素(lpush),接收操作会在对了的头部移出(rpop)。如果通道满了,发送操作就会阻塞所在的 goroutine,直到另一个 goroutine 对它进行了接收操作来腾出空间。反过来,如果通道是空的,执行接收操作的 goroutine 阻塞,直到另一个 goroutine 在通道上发送数据。 因为缓冲空间足够的时候,不会阻塞,所以缓冲通道的一个重要特点是解耦。 在同一个 goroutine 上收发缓冲通道,会导致死锁吗? 如果没有超过缓冲的容量,就不会,但是如果超过容量就会触发阻塞,从而导致死锁。通道一般是用于 goroutine 之间通信的,所以一般不要在同一个 goroutine 上进行收发操作。 // 利用channel 实现了一个队列的操作,不过有死锁的风险 func main() { ch := make(chan int, 2) ch <- 1 ch <- 2 // ch <- 3 如果增加这个,就会死锁 fmt.Println(<-ch) fmt.Println(<-ch) } 一般所谓的死锁,是阻塞了主进程,如果只是阻塞子协程,并不会导致死锁 func main() { go func() { ch := make(chan int, 2) ch <- 1 // 会一直阻塞在这里,但是并不会报死锁 <-ch }() for { fmt.Println("end") time.Sleep(time.Second) } } 需要注意的是,在内存无法提供缓冲容量的情况下,可能导致程序死锁。 如何获取通道的容量呢? 可以通过 cap 函数获取,例如 cap(ch) 如何获取通道的内的元素的个数 可以通过 len 函数获取,例如 len(ch) 缓冲通道的使用场景? 一般用于上游生产比下游消耗的速度快的场景。可以一下子生产很多东西,下游慢慢的去消费。当一个下游 goroutine 消费速度太慢的时候,可以再创建一个 goroutine 来一起消费这个通道,提高消费速度。 通道的遍历 下例中 goroutine 产生自然数传递给另外一个 goroutine,并且求平方后给主 goroutine 打印 func main() { naturals := make(chan int) squares := make(chan int) go func() { for i := 1; ; i++ { // 无限产生自然数到通道naturals naturals <- i } }() go func() { for { // 无限从naturals通道读取数据,并且求平方 x := <-naturals squares <- (x * x) } }() for { // 求得的平方无限打印出来 val := <-squares fmt.Println(val) } } 上述例子是发送无限的数字,如果想要发送有限的数字怎么办呢? 如果发送方直到没有更多的数据要发送,就应该告诉接受者所在的 goroutine 不要再等待了。通过 close(naturals) 来通知接收者就好了。 通道 naturals 被关闭后,后续就不能再往该通道发送数据,否则会异常退出。并且关闭的通道 naturals 被读完之后,所有后续的接收操作都不会被阻塞,而是顺畅的获取到零值,传递给了 squares 通道 func main() { naturals := make(chan int) squares := make(chan int) go func() { for i := 1; i <= 5; i++ { naturals <- i } // 产生5个自然数到通道naturals close(naturals) }() go func() { for { // 获取5个自然数后,从关闭的通道上获取的数都是0 x := <-naturals squares <- (x * x) } }() for { // 打印出1,4,9,16,25,0,0....后续都是0 val := <-squares fmt.Println(val) } } 那么,有没一个方式来判断该通道是否已经被关闭了呢? 可以在接收参数上加一个 ok 参数,当为 true 的时候表示接收成功,为 false 的话表示当前接收操作在一个关闭并且读完的通道上。 func main() { naturals := make(chan int) squares := make(chan int) go func() { // 产生5个自然数到通道naturals,然后关闭通道 for i := 1; i <= 5; i++ { naturals <- i } close(naturals) }() go func() { for { // 当5个数接收完后,由于通道被关闭,所有ok会为false x, ok := <-naturals if !ok { break } squares <- (x * x) } close(squares) }() for { val, ok := <-squares if !ok { break } // 打印出1,4,9,16,25 fmt.Println(val) } } 有没有更简单的写法呢? 由于 for 循环里通过 ok 判断来退出循环的方式比较笨拙,所以提供了 range 循环语法,可以直接在通道上迭代。Range 更方便的从通道上接收值,并且接收完最后一个后退出循环。所以可以简写为 func main() { naturals := make(chan int) squares := make(chan int) go func() { // 产生5个自然数到通道naturals,然后关闭通道 for i := 1; i <= 5; i++ { naturals <- i } close(naturals) }() go func() { for x := range naturals { squares <- (x * x) } close(squares) }() for val := range squares { // 打印出1,4,9,16,25 fmt.Println(val) } } 通道关闭是必须的吗? 并不是必须的,只有需要通知接收方的 goroutine 所有的数据都发送完毕的时候,才需要关闭通道。因为如果像是 range 循环,不通知的通道关闭的话,会一直等到,导致死锁,例如 func main() { naturals := make(chan int) go func() { for i := 1; i <= 5; i++ { naturals <- i } }() // 由于naturals 没有被关闭,所以这里会一直等待,导致死锁 for val := range naturals { fmt.Println(val) } } 对于未关闭的通道,垃圾回收器可以通过它是否可以被访问来决定是否回收它。 单向通道 当一个通道作为函数的参数时候,它经常会被有意的设置不能发送或不能接收。Go 的类型系统提供了单向通道类型,仅仅导出发送或者接收操作。 类型 chan<- int 是一个只能发送的通道,允许向这个通道发送,不能从这个通过接收 类型 <-chan int 是一个只能接收的通道,允许向从这个通道接收,不能向这个通过发送 // 只能发送 func counter(out chan<- int) { for i := 1; i <= 5; i++ { out <- i } close(out) } // 发送和接收 func squarer(out chan<- int, in <-chan int) { for x := range in { out <- (x * x) } close(out) } func main() { naturals := make(chan int) squares := make(chan int) go counter(naturals) go squarer(squares, naturals) for val := range squares { // 打印出1,4,9,16,25 fmt.Println(val) } } 需要注意的是:在变量声明中是不应该出现单向通道的,因为通道本来就是为了通信而生,定义一个只能接收或者只能发送数据的通道是没有意义的。 ch := make(chan<- string, 1) ch <- "str" 这个例子中定义了一个只能用来接收数据的通道,从语法上来看没有错误,但这是一种糟糕的实践。 Select 多路复用 正常我们一行代码只能监听一个 channel,看下该 channel 是否有数据,有时候我们希望同时监听多个 channel,如果同时有数据,多个 channel 则是并发执行。在下述例子中,通过 select 的使用,使得代码阻塞在 select 那,直到每个通道都关闭了,才会退出 select,保证了 worker 中的事务可以执行完毕后才退出 main 函数 func strWorker(ch chan string) { time.Sleep(1 * time.Second) fmt.Println("do something with strWorker...") ch <- "str" } func intWorker(ch chan int) { time.Sleep(2 * time.Second) fmt.Println("do something with intWorker...") ch <- 1 } func main() { chStr := make(chan string) chInt := make(chan int) go strWorker(chStr) go intWorker(chInt) for i := 0; i < 2; i++ { select { case <-chStr:// 这个通道一有值就会执行这 fmt.Println("get value from strWorker") case <-chInt:// 这个通道一有值就会执行这 fmt.Println("get value from intWorker") } } } 通过 select 里的default,我们还可以实现不阻塞 channel package main import ( "fmt" "time" ) func readBlocWithNoBlock() { dataCh := make(chan int) go func() { for i := 0; i < 100; i++ { dataCh <- i time.Sleep(time.Second) } }() for i := 0; i < 100; i++ { select { // 这个取到值后,就走这个 case data := <-dataCh: fmt.Println(data) // 如果上面的阻塞,就默认执行这个 default: } fmt.Println("YES") time.Sleep(500 * time.Millisecond) } } func main() { readBlocWithNoBlock() } 通过 channel 实现同步机制 一个经典的例子如下,main 函数中起了一个 goroutine,通过非缓冲队列的使用,能够保证在 goroutine 执行结束之前 main 函数不会提前退出。 func worker(done chan bool) { fmt.Println("start working...") done <- true fmt.Println("end working...") } func main() { done := make(chan bool, 1) go worker(done) <-done // 阻塞在这里,确保协程执行完成 } 如果没有 <-done 的话,worker 里的内容将不会执行,当然我们还可以通过 sync. WaitGroup 来实现同步,见 go语言的goroutine 章节 通道总结 哪些情况会导致 channel 死锁? 在同一个协程了使用非缓冲通道 Foreach 变量通道,没有关闭协程
-
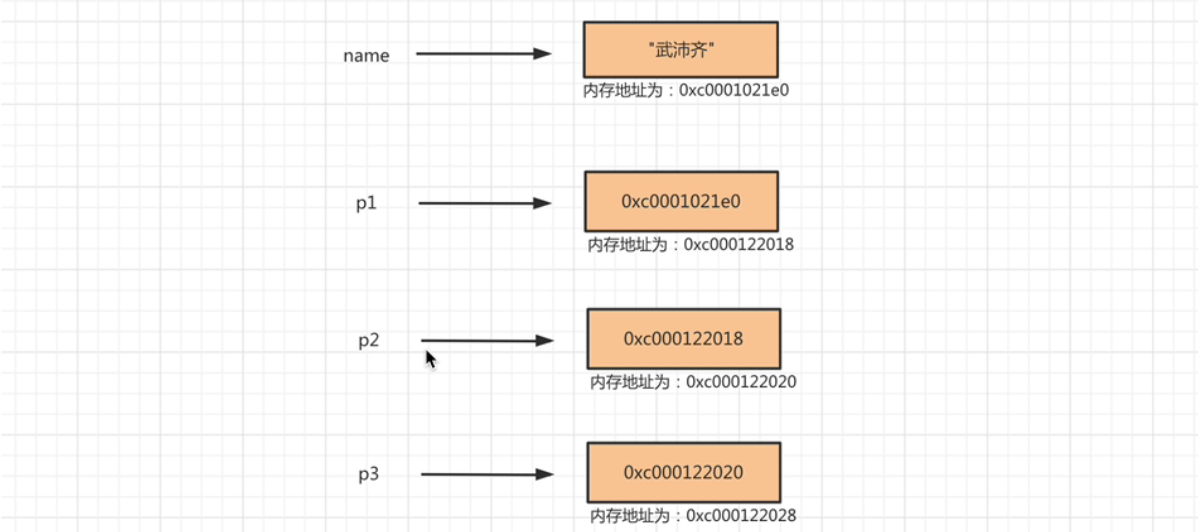
Go指针语法详细解析 | Go语言编程指南 使用场景 使用指针,出于以下两个目的: 指针变量复制和拷贝的是地址,所以比较轻量,对于大的结构体变量,这样拷贝会比较快。 在生命周期的任何位置可以修改原变量的值 示例 函数内部改变外部变量值 package main import "fmt" func main() { v1 := "武沛齐" // 参数传递,是将值复制一份给形参 // 所以形参里面是个副本,修改里面的值不会改变外面的值的值 changeData(&v1) // 哈哈哈 fmt.Println(v1) } func changeData(data *string) { *data = "哈哈哈" } 获取控制台输入: package main import "fmt" func main() { var userName string fmt.Println("请输入你的名字:") fmt.Scanf("%s", &userName) // 在Scanf里改变userName的值 // 打印输入的值 fmt.Println(userName) } 指针类型声明 指针类型和其它的类型一样,也是个数据类型,任何类型(包括指针类型)都有一个对应的指针类型。 声明指针类型,只需要在该类型前面加个 *,默认零值是 nil。 普通类型的变量存储的是该类型的值,指针类型的变量存储的是该类型的内存地址! 😎 var v1 string // string类型 var v2 *string // string类型的指针类型 var v1 int // int类型 var v2 *int // int类型的指针类型 举例说明,指针的指针类型,这个不常用,了解即可。 因为指针变量本身也是个变量,自己也有地址,所以可以对指针类型取地址。 name := "武沛齐" var p1 *string = &name // 两个**表示,是指针的指针类型 var p2 **string = &p1 // 3个星表示是指针的指针的指针类型 var p3 ***string = &p2 // 指针的指针的指针类型,取值要相应的加3个* ***p3 = "哈哈哈" fmt.Println(name) 取地址 所有变量都有内存地址,只需要在对应的变量前面加个 & 就可以取变量的地址。这个地址可以存在对应指针类型变量上。 var name string = "武沛齐" var pointer *string = &name 还可以用 new 函数进行取值,可以在内存中初始化一个该类型的变量,并且返回该变量的内存地址。 func main() { p := new(int) fmt.Println(p) // 0xc00000e0d8 *p = 100 fmt.Println(*p) } 空指针 因为指针类型的零值是 nil,即:空指针。如果忘记初始化,就容易 panic: 空指针并不会有语法错误,运行到该位置的时候才会 panic(panic: runtime error: invalid memory address or nil pointer dereference),所以需要特别注意。 空值代表什么都没有,使用空变量会 panic: 以下空指针会 panic 调用空指针的成员方法 package main import "fmt" type A struct { } func (a A) Hello() { fmt.Println("hello world") } type B struct { a *A } func main() { b := B{} // 初始化的时候,b的零值是nil b.a.Hello() } 直接使用空指针 func main() { var p *int fmt.Println(*p) // 直接获取空指针值 } 数组第一个元素的指针 数组中的每个元素的地址是连续的,数组的地址,等于数组的第一个元素的地址。 dataList := [3]int{11, 22, 33} // 0xc000012180 0xc000012180 fmt.Printf("%p %p", &dataList, &dataList[0]) &dataList 和 &dataList[0] 虽然地址是一样的,但是却是不同的类型 &dataList 是 *[3]int 类型 &dataList[0] 是 *int 类型 内存地址偏移 指针类型不能直接算数计算,需要依赖 unsafe.Pointer 和 uintptr 进行转换后计算 dataList := [3]int8{11, 22, 33} // 1 获取第一个元素的指针 var firstDataPtr *int8 = &dataList[0] // 2 转成pointer类型 ptr := unsafe.Pointer(firstDataPtr) // 3 转成uintptr类型,然后才能进行内存地址计算,也就是+1个字节,取第二个索引元素的地址 targetAddr := uintptr(ptr) + 1 // 4 转为pointer类型 newPtr := unsafe.Pointer(targetAddr) // 5 转为对应的指针类型 value := (*int8)(newPtr) // 6 打印第二个元素的值,22 fmt.Println(*value) 结构体的指针计算,会比较麻烦,要使用 unsafe.Sizeof 计算出结构体每个字段的长度 type User struct { name string age int } func main() { dataList := [3]User{{}, {name: "huang"}, {age: 11}} var fistDataPtr *User = &dataList[0] ptr := unsafe.Pointer(fistDataPtr) targetAddr := uintptr(ptr) + unsafe.Sizeof(dataList[0].name) + unsafe.Sizeof(dataList[0].age) newPtr := unsafe.Pointer(targetAddr) value := (*User)(newPtr) // dataList[1] fmt.Println(*value) }
-
深入理解Go语言:复合类型之结构体 前言 Go 语言中,没有类的概念,使用结构实现类似类的功能。 语言内置的基础数据类型是用来描述一个值,而结构体是用来描述一组值。 数组、切片和 Map 可以用来表示 同一种数据类型 的集合,但是当我们要表示 不同数据类型 的集合时就需要用到结构体。 定义结构体 使用 type 和 struct 关键字来定义结构体 type 结构体名 struct { 字段名 字段类型 字段名 字段类型 … } // 例如 type person struct { name string city string age int8 } 结构体名:表示结构体的名称,在同一个包内不能重复,并且最好不要以包的名称开头,不然 idea 会警告 字段名:表示结构体字段名,结构体中的字段名必须唯一 字段类型:表示结构体字段的具体类型 通常结构体中一个字段占一行,但是类型相同的字段,也可以放在同一行,同样类型的字段也可以写在一行 type person struct { name, city string // name, city是同一个类型 age int8 } 一个结构体中的字段名是唯一的,例如一下代码,出现了两个 Name 字段,是错误的: type Student struct { Name string Name string } 结构体还可以省略字段名称,这种字段叫:结构体匿名字段。匿名结构体字段,默认会采用类型名作为字段名;由于结构体要求字段名称必须唯一,所以结构体中同种类型的匿名字段只能有一个,不然就会重复。 type person struct { string // 匿名字段 int8 // 匿名字段 } func main() { p1 := person{ string: "张三", int8: 18, } fmt.Println(p1.string) fmt.Println(p1.int8) } 结构体还可以定义字段的可见性,字段大写开头表示可公开访问,小写表示私有(仅在定义当前结构体的包中可访问),那么其他 package 就无法直接使用该字段 // 在包 pk1 中定义 Student 结构体 package pk1 type Student struct{ Age int name string } // 在另外一个包 pk2 中调用 Student 结构体 package pk2 func main(){ stu := Student{} stu.Age = 18 //正确 stu.name = "name" // 错误,因为`name` 字段为小写字母开头,不对外暴露 } 对结构体 json 化的时候,私有的字段将会丢失 type Student struct { Id int Name string age int // 私有 } func main() { studentInfo := Student{ Id: 1, Name: "小明", age: 35, } // json 格式化 data, err := json.Marshal(studentInfo) if err != nil { fmt.Println("json encode 错误") return } fmt.Printf("%s", data) // {"Id":1,"Name":"小明"},年龄字段已经丢失了 } 这样对结构体进行 json 的时候,默认输出字段的名称就是结构体字段的名称,我们经常需要修改,不希望输出的字段名称是大写字母开头的,这个时候就需要 结构体标签 的功能了,结构体标签可以是多个,用空格隔开 type Student struct { Id int `json:"id"` Name string `json:"name"` age int // 私有 } func main() { studentInfo := Student{ Id: 1, Name: "小明", age: 35, } // json 格式化 data, err := json.Marshal(studentInfo) if err != nil { fmt.Println("json encode 错误") return } fmt.Printf("%s", data) // {"id":1,"name":"小明"},这个时候字段的名称就是小写的了 } 结构体初始化 声明结构体的类型的变量的时候进行初始化,这个时候结构体的变量每个字段都有它默认类型的零值,这个和切片、map 不一样,切片和 map 定义之后,需要初始化才能使用 type person struct { name string city string age int8 } func main() { var p person fmt.Printf("%#v\n", p) // 输出main.person{name:"", city:"", age:0} } 结构体是通过 {} 括号进行初始化的 func main() { p1 := person{} fmt.Printf("%#v\n", p1) // 输出main.person{name:"", city:"", age:0} p2 := person{ name: "张三", city: "厦门", age: 30, //最后一个逗号不能忘记 } fmt.Printf("%#v\n", p2) // 输出main.person{name:"张三", city:"厦门", age:30} } 可以对结构体的部分字段进行初始化,其它字段的值是默认类型的零值 type person struct { name, city string age int8 } func main () { p:= &person{ name:"张三", age: 30, } fmt.Printf("%#v",p) } 还可以使用值列表对结构体进行初始化,不需要写 key,不过有几个约束条件: 必须初始化结构体的 所有字段 初始值的填充顺序必须与字段在结构体中的声明 顺序一致 该方式不能和键值初始化方式 混用 type person struct { name, city string age int8 } func main () { p := person{ "张三", "厦门", 30, } fmt.Printf("%#v",p) } 结构体变量,可以通过 . 访问并且设置结构体字段的值 type person struct { name, city string age int8 } func main () { var p person // 声明结构体的类型的变量 // 通过`.`访问并且设置结构体字段的值 p.name = "张三" p.city = "厦门" p.age = 30 fmt.Printf("p=%#v\n",p) fmt.Println(p.name) } 点号不仅可以作用在结构体变量上,还可以作用在结构体指针上 type person struct { name, city string age int8 } func main() { var p *person = &person{} (*p).name = "张三" (*p).city = "厦门" (*p).age = 30 fmt.Printf("p=%#v\n", (*p)) fmt.Println((*p).name) } 还可以获取成员变量的指针,通过指针来访问成员变量 type person struct { name, city string age int8 } func main() { var p person = person{} name := &p.name fmt.Println(*name) } 匿名结构体 正常情况下都是先定义结构体,然后把变量声明为结构体的,但是匿名结构体主要用于临时使用,不需要先定义结构体的类型,可以直接把变量声明为没有名称的结构体 func main () { // 不需要type定义结构体 var user struct{ name string married bool } user.name = "张三" user.married = false fmt.Println(user) } 指针类型的结构体 使用 new 关键字对结构体实例化,可以得到结构体的指针 type person struct { name, city string age int } func main() { var p = new(person) fmt.Printf("%#v\n", p) // 输出&main.person{name:"", city:"", age:0} } 还有一种方式也可以快速的获取结构体的指针,那就是 & 符号,person{} 表示对 person 结构体进行初始化,然后用 & 符号进行取值 func main() { p := &person{} fmt.Printf("%#v\n", p) // 输出&main.person{name:"", city:"", age:0} } 然后可以同 * 号来访问指针地址的实际位置 var p = new(person) (*p).name = "张三" (*p).city = "厦门" (*p).age = 30 fmt.Printf("%#v\n", p) // &main.person{name:"张三", city:"厦门", age:30} 正常情况下,要改变指针的实际值,都需要用 * 号来指向实际值,然后修改,但是每次都这样就显得麻烦,所以在结构体中,可以省略这步骤,直接访问,这个是语法糖的形式,如下所示也是可以的 var p = new(person) p.name = "张三" p.city = "厦门" p.age = 30 fmt.Printf("%#v\n", p) 结构体内存布局 结构体变量占用一块连续的内存,也就是说字段在内存中是连续的,但是空的匿名结构体是不占用内存空间的 var v struct{} fmt.Println(unsafe.Sizeof(v)) // 0 结构体构造函数 结构体没有构造函数,但是可以自己实现,其实就是构造一个结构体类型变量,并且赋值,并且函数名称约定成俗的以 new 开头。结构体是值类型,赋值的话是拷贝,所以复杂的结构体赋值会影响性能,因此构造函数最好返回指针类型 type person struct { name, city string age int } func newPerson(name string, city string, age int) *person { return &person{ name: name, city: city, age: age, } } func main() { p := newPerson("小明", "厦门", 18) fmt.Printf("%#v\n", p) // &main.person{name:"小明", city:"厦门", age:18} } 方法 Go 语言中,接收者的类型只能为用关键字 type 定义的类型,例如自定义类型,结构体。类型的方法指明该方法属于某个类型,只有这个类型的实例才能调用。同一个接收者的方法名不能重复。值作为接收者无法修改其值,如果有更改需求,需要使用指针类型。 type MyInt int //SayHello 为MyInt添加一个SayHello的方法 func (m MyInt) SayHello() { fmt.Println("Hello, 我是一个int。") } 同样,对结构体这种自定义类型,也可以添加自己的方法函数 type person struct { name, city string age int } func (p person) dream() { fmt.Printf("%s的梦想是赚大钱", p.name) } func main() { p := person{ name: "小明", city: "厦门", age: 18, } p.dream() } 关于接受者变量和类型有几个要注意的是: 接受者变量的名称,一般使用类型的首个小写字母,例如上例中 MyInt 类型的接受变量就用 m 接受者变量的类型有值类型和指针类型,但是并不要求调用者也要对于的值类型或者指针类型,调用者只要是跟接受者同一个类型就好了,编译器会自动转换;值类型的接受者是对实例的拷贝,方法内部的改变不会影响到调用者实例本身;指针类型的接收者,方法内部对实例的改变,将会影响到实例本身的值。 结构体方法最后统一使用值接受者,或者指针接受者,一般统一使用指针接受者,保持统一,不然 idea 会警告 如果构造函数返回的是接口类型,并且接口实例的方法是指针接受者,那么构造必须返回指针,不然会报错 type IServer interface { Start() } type Server struct { Name string IPVersion string IP string Port int } // 指针类型接受者 func (s *Server) Start() { } // 返回接口类型 func NewServer(name string) IServer { // !!因为接受者是指针类型,所以必须返回指针 s := &Server{ Name: name, IPVersion: "tcp4", IP: "0.0.0.0", Port: 8999, } return s } 往值上添加方法,接受者就是值本身 type myInt int func (m myInt) PrintValue() { fmt.Println(m) } func main() { var m myInt m = 10 m.PrintValue() // 10 } 结构体的嵌套 一个结构体中可以包含另一个结构体或结构体指针,就好比 json 对象中,某个字段又是一个 json 对象 type Address struct { Province string City string } type User struct { Name string Gender string Address Address // 嵌套另外一个结构体 } func main() { userInfo := User{ Name: "小王子", Gender: "男", Address: Address{ Province: "山东", City: "威海", }, } fmt.Printf("%#v\n", userInfo) // main.User{Name:"小王子", Gender:"男", Address:main.Address{Province:"山东", City:"威海"}} } 但是需要注意的是,如果嵌入的结构体是本身,那么只能用指针。请看以下例子。 type Tree struct { value int left, right *Tree } func main() { tree := Tree{ value: 1, left: &Tree{ value: 1, left: nil, right: nil, }, right: &Tree{ value: 2, left: nil, right: nil, }, } fmt.Printf(">>> %#v\n", tree) } 如果嵌套结构体的字段是匿名字段,那么访问结构体成员时会先在结构体中查找该字段,找不到再去嵌套的匿名字段中查找,这个特性很重要,我们就可以实现类似类里的属性和方法的覆盖特性。 type Address struct { Province string City string } type User struct { Name string Gender string Address } func main() { userInfo := User{ Name: "小王子", Gender: "男", Address: Address{ Province: "山东", City: "威海", }, } fmt.Println(userInfo.City) // 输出了匿名字段Address结构体上的字段了 } 如果嵌套的结构体数量一多,很可能字段会重复,如果利用嵌套匿名字段结构体的查找规则,很可能会出问题,所以如果嵌套比较多结构体,最好指定具体的内嵌结构体字段名会比较清晰 //Address 地址结构体 type Address struct { Province string City string CreateTime string // 和email结构体中的createTime重复 } //Email 邮箱结构体 type Email struct { Account string CreateTime string } //User 用户结构体 type User struct { Name string Gender string Address Email } func main() { var user3 User user3.Name = "沙河娜扎" user3.Gender = "男" // user3.CreateTime = "2019" //ambiguous selector user3.CreateTime,会报错 user3.Address.CreateTime = "2000" //指定Address结构体中的CreateTime user3.Email.CreateTime = "2000" //指定Email结构体中的CreateTime } 利用结构体的嵌套特性,我们就可以实现结构体的继承了。 //Animal 动物 type Animal struct { name string } func (a *Animal) move() { fmt.Printf("%s会动!\n", a.name) } func (a *Animal) eat() { fmt.Printf("%s会吃!\n", a.name) } //Dog 狗 type Dog struct { Feet int8 Animal //通过嵌套匿名结构体实现继承 } // 重写父类的方法 func (d *Dog) eat() { fmt.Printf("%s会大口的吃~\n", d.name) } // 子类新定义的方法 func (d *Dog) wang() { fmt.Printf("%s会汪汪汪~\n", d.name) } func main() { dogInfo := &Dog{ Feet: 4, Animal: Animal{ name: "旺财", }, } dogInfo.eat() dogInfo.wang() //旺财会汪汪汪~ dogInfo.move() //旺财会动! } 结构体的比较 前提是结构体中的字段类型是可以比较的,应该是各个字段之间进行比较,如果每个字段的值都相等的话,就是相等 type Tree struct { value int left, right *Tree } func main() { tree1 := Tree{ value: 2, } tree2 := Tree{ value: 1, } fmt.Printf(">>> %#v\n", tree1 == tree2) }
-
Go 函数语法规则 | Go语言函数编程全解析 函数的定义 函数的定义使用 func 关键字定义 func 函数名(参数)(返回值){ 函数体 } 函数名:由 字母、数字、下划线 组成,但函数名的第一个字母不能是数字,在同一个包内,函数名也称 不能重复; 参数由:参数变量 和 参数变量的类型 组成,例如:(amount int,name string),多个参数之间使用 , 分隔,可以没有参数;当参数比较长的时候,可以定义为结构体。 返回值:由变量和类型的形式,返回值变量可以在函数体中被使用,此时 return 语句后可为空,将定义的返回变量给返回,也就是将 return 变量值返回: func intSum(x int,y int) (result int) { result = x + y return // return语句后可为空 } 返回值参数还可以只有类型的形式,这个时候 return 语句后不能为空 // 只有int类型,没有变量 func intSum(x int,y int) int { return x + y // 这个时候return语句后不能为空 } 函数还可以返回多个值,或者没有返回值 // 返回两个int类型的值 func test () (int,int) { return 1,2 } 函数的参数 如果相邻变量的类型相同,则可以省略类型 // x类型也是int,和y一样 func intSum(x, y int) int { return x + y } 还可以声明为可变参数,在参数名后加 … 来标识,可变参数通常要作为函数的最后一个参数 func main() { ret := intSum(10, 20) fmt.Println(ret) } // 求和 func intSum(x ...int) int { fmt.Println(x) //x是一个切片 sum := 0 for _, v := range x { sum = sum + v } return sum } 声明指针类型的参数,传入的值必须是指针 // Person 是一个结构体 type Person struct { name string age int8 } func test(p *Person) { } func main() { p1 := &Person{ name: "张三", age: 30, } test(p1) } 函数参数必须传,但是参数可以没有被使用 func test(name string) { // name 没有被使用是允许的 fmt.Println("123") } func main() { test("123") // 但是参数必须传递 } 函数参数的默认值是如何设置的呢? 方式一:使用中间对象的方式 // 默认参数的选项,中间对象 type TeaOptions struct { heat bool } // 创建默认参数对象 func NewDaulft() *TeaOptions { return &TeaOptions{ heat: false, // 默认不加热 } } type Tea struct { name string heat bool } // 创建具体对象 func NewTea(name string, ops *TeaOptions) (*Tea, error) { return &Tea{ name: name, heat: ops.heat, }, nil } func (t Tea) getTea() { fmt.Printf("name:%s , heat:%t ", t.name, t.heat) } func main() { // 使用默认参数 tea1, _ := NewTea("tea1", NewDaulft()) tea1.getTea() // 不使用默认参数,创建TeaOptions对象传参 tea2, _ := NewTea("tea2", &TeaOptions{heat: true}) tea2.getTea() } 方式二:使用 选项模式,该模式便于扩展,可以使用设计模式中的选项模式来创建对象 type config struct { logicalRegionIdKey string logicalRegionNameKey string } type Option func(cfg *config) // WithSetLogicalRegionIdKey 修改默认值 func WithSetLogicalRegionIdKey(key string) Option { return func(cfg *config) { cfg.logicalRegionIdKey = key } } func NewLogicalRegionConverter(name string, opts ...Option) { // 默认值 cfg := config{ logicalRegionIdKey: "logical_region_id", logicalRegionNameKey: "logical_region_name", } if opts != nil && len(opts) > 0 { for _, opt := range opts { opt(&cfg) } } fmt.Println(name, cfg.logicalRegionIdKey, cfg.logicalRegionNameKey) } func main() { NewLogicalRegionConverter("区域配置") NewLogicalRegionConverter("区域配置", WithSetLogicalRegionIdKey("logical_region_id_不是默认值")) } 函数的返回值 函数可以有多个返回值,有多个返回值时必须用 () 将所有返回值包裹起来 // (int,int) func calc(x, y int) (int, int) { sum := x + y sub := x - y return sum, sub } 可以对返回值进行命名,在函数体中直接使用这些变量,最后通过 return 关键字返回 func calc(x, y int) (sum, sub int) { sum = x + y sub = x - y return } 函数的调用 通过 函数名() 的方式调用函数,调用有返回值的函数时,可以不接收其返回值 func main() { // 调用 sayHello() ret := intSum(10, 20) fmt.Println(ret) } 函数参数有时候很长,需要换行显示,最后一个参数需要有逗号,这样好像也没关系 func QueryByPage( logicalRegionId int, page, pageSize int, // 需要有逗号 ) { // 实现 } 函数的作用域 在函数中可以访问到全局变量,也就是定义在函数外部的全局变量,在函数内部定义的局部变量只有当前函数作用域中生效,如果局部变量和全局变量重名,优先访问局部变量。 函数类型的变量 可以将变量声明为函数类型 type calculation func(int, int) int // 例如,就是calculation类型 func add(x, y int) int { return x + y } func main() { var c calculation // 声明一个calculation类型的变量c c = add // 把add赋值给c fmt.Printf("type of c:%T\n", c) // type of c:main.calculation fmt.Println(c(1, 2)) // 像调用add一样调用c f := add // 将函数add赋值给变量f1 fmt.Printf("type of f:%T\n", f) // type of f:func(int, int) int fmt.Println(f(10, 20)) // 像调用add一样调用f } 函数作为参数 既然函数可以作为变量类型,并且用于赋值,那么函数自然可以传递给函数的参数 func add(x, y int) int { return x + y } // 接收函数类型为:func(int, int) int的函数 func calc(x, y int, op func(int, int) int) int { return op(x, y) } func main() { ret2 := calc(10, 20, add) fmt.Println(ret2) //30 } 函数作为返回值类型 同理,返回值类型也可以定义为函数类型 func add(x, y int) int { return x + y } // 返回类型:func(int, int) int func do() (func(int, int) int) { return add } 匿名函数 我们把没有函数名称的函数,叫做匿名函数,这个跟 php 的匿名函数类似 func main() { // 将匿名函数保存到变量 add := func(x, y int) { fmt.Println(x + y) } add(10, 20) // 通过变量调用匿名函数 //自执行函数:匿名函数定义完加()直接执行 func(x, y int) { fmt.Println(x + y) }(10, 20) } 闭包 闭包是一个 函数 和 与其相关的引用环境 组合而成的实体,就好比是封闭的一个包,有点像类的,里面有属性和方法。 // 类似于一个类:属性+方法 func adder(x int) func(int) int { // 属性 var z int // 函数 return func(y int) int { z = y + x + z x++ return z } } func main() { // 属性x、z在f对象的整个声明周期内有效 var f = adder(10) // 构造函数初始化 fmt.Println(f(20)) //30 调用对象的方法 fmt.Println(f(50)) //91 } defer 语句 defer 语句会将其后面跟随的语句进行延迟处理,函数即将返回时,按 defer 定义的逆序进行执行 // 输出:start end 3 2 1 func main() { fmt.Println("start") defer fmt.Println(1) defer fmt.Println(2) defer fmt.Println(3) fmt.Println("end") }
-
Go语言中的自定义类型与别名详解 介绍 使用关键字定义类型有两种操作: 不带有 = 的是新类型定义 带有 = 的是别名定义 自定义类型 通过 type 关键字自定义类型, 是一个全新的类型,底层数据结构一模一样。主要用途是进行概念上进行区分于另外一个类型,是得业务更加清晰明了。 虽然说,它们的底层内存数据结构一样,但是它们概念上是不同。 package main // Duration 定义一个时长类型 type Duration int64 const ( Nanosecond Duration = 1 Microsecond = 1000 * Nanosecond Millisecond = 1000 * Microsecond Second = 1000 * Millisecond Minute = 60 * Second Hour = 60 * Minute ) func main() { var a int64 const b int64 = 5 var c Duration a = int64(c) c = Duration(a) * Hour // 不同类型之间,需要转换,小括号类型转换 c = 5 * Hour // 字面量会自动执行类型转 } Duration 就是一种新的类型,它底层和 int64 一样,但是代表的意思不一样。不同类型之间,需要转换,小括号类型转换,需要注意的是,字面量会自动执行类型转换。 再举个例子,下例中,Plane 类型和 Car 类型的数据结构一样,但是代表的东西不一样,拥有的方法也不一样。 package main type Car struct { Name string } func (c Car) Drive() { } // Plane 类型和Car类型的数据结构一样,成员变量一样 // 但是方法不一样,概念不一样 type Plane Car func (p Plane) Fly() { } func main() { car := Car{ Name: "车子", } car.Drive() plane := Plane{ Name: "飞机", } plane.Fly() } 类型转换 自定义的类型,是个全新的类型,因为他们底层都一样,可以进行类型转换。对于每个类型,都有一个类型转换操作 T(x),以下两种情况可以类型之间可以相互转换 都拥有同样的底层类型的话 都是指向同一种类型的指针类型 需要注意的是:数字类型之间、字符串和一些 slice 类型也是允许转换的,例如: 浮点数转整数,小数部分丢失 字符串转为 []byte 切片,会分配一份字符串数据副本 命令类型的底层类型,决定了它支持什么操作,例如底层如果是数值类型的话,那么就支持算数运算。 option 模式 这个模式在 go 语言里到处都是,很常见。主要有两种方式: 函数模式 接口模式 方式一:将 option 定义为匿名函数模式 这个模式比较简单,主要是在传入回调函数,然后在构造函数里调用回调函数,修改默认的值。 package main import "fmt" type User struct { Name string Age int } // UserOption 函数的参数一样要是指针类型,因为要修改User结构体 // 用于修改user结构体实例 type UserOption func(*User) // WithName 用于生产UserOption func WithName(name string) UserOption { return func(u *User) { // 调用的时候,这个name会被实际值替换掉,这样的话可以灵活的赋值,例如WithName("张三") // 此时相当于u.Name="张三" u.Name = name } } // WithAge 用于生产UserOption func WithAge(age int) UserOption { return func(u *User) { // 调用的时候,这个age会被实际值替换掉,例如WithName(18) // 此时相当于u.Age=18 u.Age = age } } // opts 定义成不定长的参数 func NewUser(opts ...UserOption) *User { // 默认值 user := &User{ Age: 30, Name: "小明", } // 修改默认值 for _, opt := range opts { opt(user) } return user } func main() { // 传人参数,修改默认值 user := NewUser( WithName("张三"), WithAge(18), ) fmt.Println(user) } 方式二:将 options 定义为接口模式 比第一种写法复杂了很多,优势是:接口里可以包含多个函数,后续如果要新增方法的话,调整起来比较方便。 package main import "fmt" type User struct { Name string Age int } // UserOption 函数的参数一样要是指针类型,因为要修改User结构体 // 用于修改user结构体实例 type UserOption interface { // Apply 因为也是要改user实例的内容,所以也要指针类型 Apply(*User) } type UserName struct { Name string } // Apply 实现UserOption接口 func (u *UserName) Apply(user *User) { user.Name = u.Name } func NewUserName(name string) *UserName { return &UserName{ Name: name, } } type UserAge struct { Age int } // Apply 实现UserOption接口 func (u *UserAge) Apply(user *User) { user.Age = u.Age } func NewUserAge(age int) *UserAge { return &UserAge{ Age: age, } } func NewUser(opts ...UserOption) *User { // 默认值 user := &User{ Age: 30, Name: "小明", } // 修改默认值 for _, opt := range opts { opt.Apply(user) } return user } func main() { // 传人参数,修改默认值 user := NewUser( NewUserName("张三"), NewUserAge(18), ) fmt.Println(user) } 别名 别名类型是带有等号的,主要用途是:为了使用方便,减少代码量,例如 interface{} 用别名 Any 来替换,用起来方便。 别名类型只有在代码中存在,编译完成不会有别名类型,所以可以理解为,别名类型和原来的类型一模一样,可以互相比较赋值。 package main // go 源码里定义的别名 type byte = uint8 type rune = int32 type any = interface{} func useByteFunc(a byte) { } func main() { var a uint8 // 因为byte是uint8的别名,所以可以直接复制 var b byte = 100 a = b // unit8类型的变量也可以直接赋值给byte类型 useByteFunc(a) } 当然,别名类型的源类型,可以是自定义类型。 // Car 自定义类型 type Car struct { } type BlackCar = Car 函数类型 函数类型和结构体类型的初始化方式不一样。函数类型可以有自己成员方法,但是没有成员变量。实例化的话,需要传递一个同个类型的函数进来。 package main // FV 是一个函数类型的变量 var fv = func(arg int) {} // FT 是一样类型,没有成员变量 type FT func(arg int) // Hello 类型可以有自己的成员方法 func (ft FT) Hello(arg int) { ft(arg) } // IFC FT类型可以实现接口 type IFC interface { Hello(arg int) } func main() { // 函数后面加括号,表示调用 fv(3) // 由于FT没有成员变量,不是struct,创建实力不能用{} // 需要用()传递一个类型匹配的函数进来,FT的实力可以当做函数使用 FT(fv)(3) // 函数实例可以调用成员方法 FT(fv).Hello(3) }