概述
包是多个源代码的集合,是一种高级的代码复用方案,一个包可以简单理解为一个存放 .go 文件的文件夹,该文件夹下面的所有 go 文件都要在代码的第一行添加如下代码,声明该文件归属的包
// 这个包名其实就是命名空间
package 包名注意事项:
- 一个文件夹下的文件只能归属一个
package,同样一个package的文件不能在多个文件夹下,不过实际情况也有可能一个文件夹下有多个包,例如 mysql 目录下有:mysql 包和 mysql_test 包,mysql_test 包专门用于测试 - 包名可以不和文件夹的名字一样(通常要一样的),包名不能包含
-符号 - 包名为
main的包为应用程序的入口包,这种包编译后会得到一个可执行文件,而编译不包含main包的源代码则不会得到可执行文件 - 测试包:名称以_test. go 结尾的文件,包含此处所述的 TestXxx 函数,
_test.go文件放在与正在测试的文件包相同的包中。该文件将从常规软件包构建中排除,但在运行“go test”命令时将包含该文件 - 不同文件夹下的同个包名称,应该属于不同的包!
- 一个包里,不同的职责放在不同的文件里,例如 MySQL 驱动包要解析 dsn,则把 dsn 放在单独的文件里,暴露一个方法出来就可以了,包的常量也可以单独放在一个文件里,然后一般一个文件就只有一个结构体,代表一个类
- 一个文件夹就是一个包,包的名称可以和文件夹的名称不一样,建议写成和文件夹的名称一样。
- 同一个文件夹下的可以有多个源文件,不过每个源文件的包名称必须一样
- 同一个包里的方法可以直接调用
- 文件夹底下,还可以有文件夹,属于不同的包
包的分类
- main包,如果是main包,则必须有一个main函数,此函数就是项目的入口。如果是main包,并且有main函数,则编译的时候会生成可执行文件。如果不是main包,编译的时候会在pkg目录,生成
包名.a的包文件供其他项目使用 - 非main包,用来将我们的代码按功能分类,分别放在不同的包和文件中,这样好编辑管理
需要注意的是:当我们的main包里有多个文件,main函数里调用其它文件里的方法,用goland的直接执行,会报错,因为goland的默认只会编译一个文件

这个时候需要改下配置
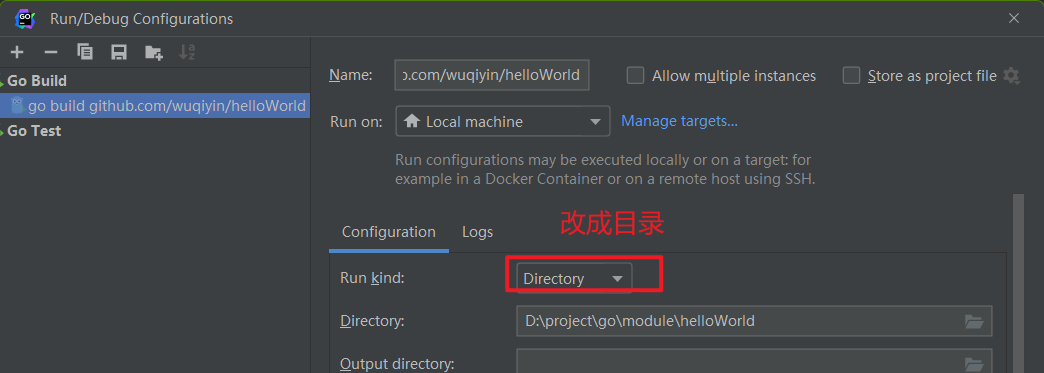
包导入
要在代码中引用其他包的内容,需要使用 import 关键字导入使用的包
// 查找方式见依赖管理的文章
import "导入路径"
// 这样也可以,不过好像不推荐
import "./项目的相对路径"注意事项:
- import 导入语句通常放在文件开头包声明语句的下面
- 导入路径只是一个目录,通常路径的最后一段的目录名称和包的名称一样,这样方便管理,如果不一样的话,需要声明包名称,例如
import 包名称 导入路径 - 导入的包名需要使用双引号包裹起来
- 文件位置查找规则,具体可以看 go依赖管理
- Go 语言中禁止循环导入包,比如: a 导入 b,b 又导入 a
- 导入的包会被整合到编译的可执行文件中
- 导入的包没有使用,会导致编译错误
- 每个包的依赖包是独立的,要重复导入,不能 a 包导过依赖后,b 包就不导入了
- 导入的包是文件级别的,所以导入后,可以在同一个文件中被使用,但是如果同一包的其他文件没有导入的话,将不能使用
小提示
go 的依赖导入自带的和第三方的应该要空行分开,方便阅读,例如:
import (
"context"
"database/sql"
"fmt"
"net/url"
_ "github.com/go-sql-driver/mysql"
"github.com/gogf/gf/v2/frame/g"
"github.com/gogf/gf/v2/util/gutil"
"github.com/gogf/gf/v2/database/gdb"
"github.com/gogf/gf/v2/errors/gcode"
"github.com/gogf/gf/v2/errors/gerror"
"github.com/gogf/gf/v2/text/gregex"
)单行导入
import "包1"
import "包2"多行导入
import (
"包1"
"包2"
)
// 最好是按顺序包1,然后包2,这种先包2,再包1的idea会提示
import (
"包2"
"包1"
)包的可见性
包名标识符首字母大写,表示对外可见,对外可见通常需要写注释,以标识符开头,空格隔开
// Sum 是求两个整型的和
func Sum(x int,y int) int {
return x + y
}标识符首字母小写,表示对外不可见,同一个包里多个源文件之间,是可以相互调用对方的函数、变量等
包别名
导入包名字冲突时候或者导入的包名字很长的时候,往往需要包的别名
// 单行的时候
import 别名 "包的路径"
// 多行的时候
import (
"fmt"
m "github.com/Q1mi/studygo/pkg_test"
)如果别名是 . 的话,就可以直接使用其内容,而不用再添加 fmt,如 fmt. Println 可以直接写成 Println,一般不这么使用,因为会比较混乱
package main
import (
. "fmt"
)
func main() {
Println("123")
}匿名导入
go 中如果只是导入包,而不使用的话就会报错,这个时候可以使用匿名包,为了防止报错,可以使用匿名导入包,主要是为了使用初始化的函数
import _ "包的路径"匿名导入的包与其他方式导入的包一样都会被编译到可执行文件中
包的初始化函数 init ()
通常包目录下有多个文件,执行的时候,会先对文件进行排序后执行:
- 包导入的时候自动执行
- 没有参数,也没有返回值
- 一个包可以有多个 int 函数,即一个源文件中函数名称为 init 的函数可以多个,名称可以重复,同一个包的 init 执行顺序,golang 没有明确定义,好像是按上下顺序,编程时要注意程序不要依赖这个执行顺序,不同文件里的,按文件的名称的顺序
- 单个包里执行顺序:首先全局声明(全局变量,全局常量声明),然后 init () 函数,最后是 mian () 函数
- 包 1 导入包 2 的时候,init ()函数执行顺序:首先执行包 2 里的 init (),然后执行包 1 里的 init ()
包的执行逻辑
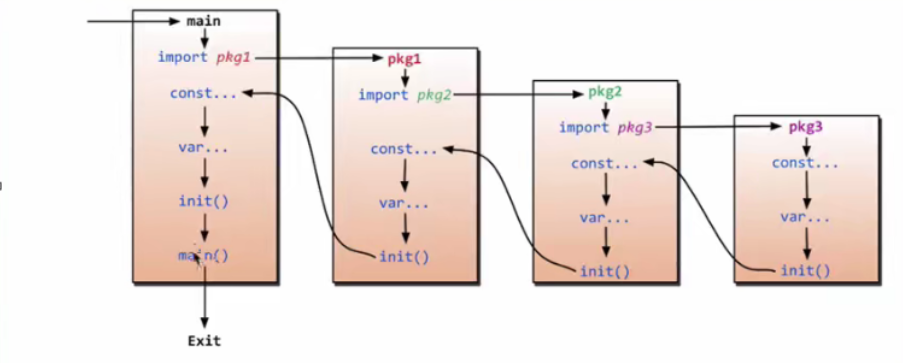
如上图所示,包的执行步骤是:
- 首先 main 包去找 pkg1 包
- pkg1 包找 pkg2 包
- pkg2 包找 pkg3 包
- pkg3 包从上往下执行,并且执行 init 函数
- 然后回到 pkg2 包从上往下执行
- 以此类推...
需要注意的是:
- 所有 init 函数都在同⼀个 goroutine 内执⾏,这个不知道有啥用❓
- 所有 init 函数结束后才会执⾏ main. main 函数
- 对同一个 package 中的不同文件,将文件名按字符串进行“从小到大”排序,之后顺序调用各文件中的 init () 函数
- 对同一个 go 文件的 init ( ) 调用顺序是从上到下的
- 同包下的不同 go 文件,按照文件名“从小到大”排序顺序执行,好像 idea 的目录下的文件已经是排序好的,所以在 idea 里就是从上往下执行
- 其他的包只有被 main 包 import 才会执行,按照 import 的先后顺序执行
- 一个包被其它多个包 import,但只能被初始化一次
- main 包总是被最后一个初始化,因为它总是依赖别的包
包的类型
大致分为 4 种类型:
import (
// Go 标准包
"fmt"
// 第三方包
"github.com/spf13/pflag"
// 匿名包
_ "github.com/jinzhu/gorm/dialects/mysql"
// 内部包
"github.com/marmotedu/iam/internal/apiserver"
)- Go 标准包:在 Go 源码目录下,随 Go 一起发布的包
- 第三方包:第三方提供的包,比如来自于 github. com 的包
- 匿名包:只导入而不使用的包。通常情况下,我们只是想使用导入包产生的副作用,即引用包级别的变量、常量、结构体、接口等,以及执行导入包的 init () 函数。
- 内部包:项目内部的包,位于项目目录下。
