搜索到
37
篇与
的结果
-
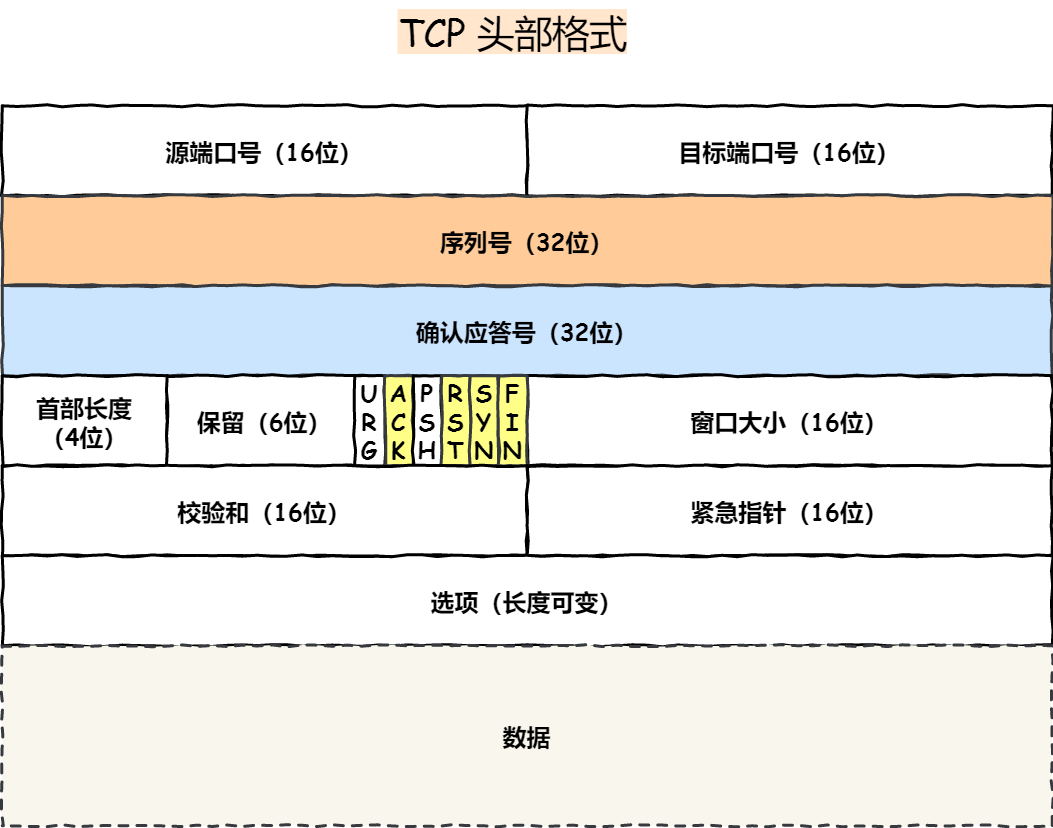
 TCP协议详解 | 网络通信的核心技术 tcp概述 TCP(Transmission Control Protocol)又叫传输控制协议,是面向连接的、可靠的、基于字节流的传输层通信协议。 面向连接:一定是「一对一」才能连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的; 可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端; 字节流:用户消息通过 TCP 协议传输时,消息可能会被操作系统「分组」成多个的 TCP 报文,如果接收方的程序如果不知道「消息的边界」,是无法读出一个有效的用户消息的。并且 TCP 报文是「有序的」,当「前一个」TCP 报文没有收到的时候,即使它先收到了后面的 TCP 报文,那么也不能扔给应用层去处理,同时对「重复」的 TCP 报文会自动丢弃。 优点: 可靠,稳定。TCP的可靠性体现在传输数据之前,三次握手建立连接(四次挥手断开连接),并且在数据传递时,有确认,窗口,重传,拥塞控制机制,数据传完之后断开连接来节省系统资源。 应用场景: 对网络通信质量有要求时,比如:整个数据要准确无误的传递给对方,这往往对于一些要求可靠的应用,比如HTTP,HTTPS,FTP等传输文件的协议,POP,SMTP等邮件的传输协议,websocket协议等。 头部格式 我们先来看看 TCP 头的格式,标注颜色的表示与本文关联比较大的字段,其他字段不做详细阐述 序列号: 在建立连接时由计算机生成的随机数作为其初始值,通过 SYN 包传给接收端主机,每发送一次数据,就「累加」一次该「数据字节数」的大小。用来解决网络包乱序问题。 确认应答号: 指下一次「期望」收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。用来解决丢包的问题。 控制位: ACK(Acknowledge character即是确认字符):该位为 1 时,「确认应答」的字段变为有效,TCP 规定除了最初建立连接时的 SYN 包之外该位必须设置为 1 。 RST:该位为 1 时,表示 TCP 连接中出现异常必须强制断开连接。 SYN(同步序列编号Synchronize Sequence Numbers):该位为 1 时,表示希望建立连接,需要同步序列号,并在其「序列号」的字段进行序列号初始值的设定。 FIN:该位为 1 时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换 FIN 位为 1 的 TCP 段。 3次握手4次挥手 一个可靠连接肯定会有以下三个过程:创建连接、 数据传输、 终止连接 创建连接 这里就是常说的‘三次握手’,其实完全可以用常识来理解这个过程,两个人之间如果想建立一个通信,至少需要有三次对话才能保证通信的可靠。举个栗子,相信大家打游戏的时候都跟队友语音过。 {timeline} {timeline-item color="#19be6b"} A:听得到吗? 建立连接,客户端发送连接请求报文段,将SYN位置为1,Sequence Number为x;然后,客户端进入SYN_SEND状态,等待服务器的确认 {/timeline-item} {timeline-item color="#ed4014"} B:我听到了,你能听到我说话吗? 服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);同时,自己自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态; {/timeline-item} {timeline-item color="#ed4014"} A:ok,我能听到~ 客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手。 {/timeline-item} {/timeline} 数据传输 {timeline} {timeline-item color="#19be6b"} A:我给你发个一堆东西,你按照顺序拼好 {/timeline-item} {timeline-item color="#ed4014"} B:收到了 发送的文件其实被拆成一个一个的小块,seq(Sequence Number)的作用是序列号,让服务器端能拼回来。 {/timeline-item} {/timeline} 终止连接 当数据传输完毕之后,就要终止连接了,也就是 ‘四次挥手’ {timeline} {timeline-item color="#19be6b"} A:我要下了,你有什么想对我说的吗? 主机1(可以使客户端,也可以是服务器端),设置Sequence Number和Acknowledgment Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了; {/timeline-item} {timeline-item color="#ed4014"} B:等等,让我说完 xxxxx…… 主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2同意‘关闭’,但是要等一下,因为这里可能还有数据没有接受完 {/timeline-item} {timeline-item color="#ed4014"} B:好了,我说完了。 主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态; {/timeline-item} {timeline-item color="#ed4014"} A:那拜拜啦~ 主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。 {/timeline-item} {/timeline}
TCP协议详解 | 网络通信的核心技术 tcp概述 TCP(Transmission Control Protocol)又叫传输控制协议,是面向连接的、可靠的、基于字节流的传输层通信协议。 面向连接:一定是「一对一」才能连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的; 可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端; 字节流:用户消息通过 TCP 协议传输时,消息可能会被操作系统「分组」成多个的 TCP 报文,如果接收方的程序如果不知道「消息的边界」,是无法读出一个有效的用户消息的。并且 TCP 报文是「有序的」,当「前一个」TCP 报文没有收到的时候,即使它先收到了后面的 TCP 报文,那么也不能扔给应用层去处理,同时对「重复」的 TCP 报文会自动丢弃。 优点: 可靠,稳定。TCP的可靠性体现在传输数据之前,三次握手建立连接(四次挥手断开连接),并且在数据传递时,有确认,窗口,重传,拥塞控制机制,数据传完之后断开连接来节省系统资源。 应用场景: 对网络通信质量有要求时,比如:整个数据要准确无误的传递给对方,这往往对于一些要求可靠的应用,比如HTTP,HTTPS,FTP等传输文件的协议,POP,SMTP等邮件的传输协议,websocket协议等。 头部格式 我们先来看看 TCP 头的格式,标注颜色的表示与本文关联比较大的字段,其他字段不做详细阐述 序列号: 在建立连接时由计算机生成的随机数作为其初始值,通过 SYN 包传给接收端主机,每发送一次数据,就「累加」一次该「数据字节数」的大小。用来解决网络包乱序问题。 确认应答号: 指下一次「期望」收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。用来解决丢包的问题。 控制位: ACK(Acknowledge character即是确认字符):该位为 1 时,「确认应答」的字段变为有效,TCP 规定除了最初建立连接时的 SYN 包之外该位必须设置为 1 。 RST:该位为 1 时,表示 TCP 连接中出现异常必须强制断开连接。 SYN(同步序列编号Synchronize Sequence Numbers):该位为 1 时,表示希望建立连接,需要同步序列号,并在其「序列号」的字段进行序列号初始值的设定。 FIN:该位为 1 时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换 FIN 位为 1 的 TCP 段。 3次握手4次挥手 一个可靠连接肯定会有以下三个过程:创建连接、 数据传输、 终止连接 创建连接 这里就是常说的‘三次握手’,其实完全可以用常识来理解这个过程,两个人之间如果想建立一个通信,至少需要有三次对话才能保证通信的可靠。举个栗子,相信大家打游戏的时候都跟队友语音过。 {timeline} {timeline-item color="#19be6b"} A:听得到吗? 建立连接,客户端发送连接请求报文段,将SYN位置为1,Sequence Number为x;然后,客户端进入SYN_SEND状态,等待服务器的确认 {/timeline-item} {timeline-item color="#ed4014"} B:我听到了,你能听到我说话吗? 服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);同时,自己自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态; {/timeline-item} {timeline-item color="#ed4014"} A:ok,我能听到~ 客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手。 {/timeline-item} {/timeline} 数据传输 {timeline} {timeline-item color="#19be6b"} A:我给你发个一堆东西,你按照顺序拼好 {/timeline-item} {timeline-item color="#ed4014"} B:收到了 发送的文件其实被拆成一个一个的小块,seq(Sequence Number)的作用是序列号,让服务器端能拼回来。 {/timeline-item} {/timeline} 终止连接 当数据传输完毕之后,就要终止连接了,也就是 ‘四次挥手’ {timeline} {timeline-item color="#19be6b"} A:我要下了,你有什么想对我说的吗? 主机1(可以使客户端,也可以是服务器端),设置Sequence Number和Acknowledgment Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了; {/timeline-item} {timeline-item color="#ed4014"} B:等等,让我说完 xxxxx…… 主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2同意‘关闭’,但是要等一下,因为这里可能还有数据没有接受完 {/timeline-item} {timeline-item color="#ed4014"} B:好了,我说完了。 主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态; {/timeline-item} {timeline-item color="#ed4014"} A:那拜拜啦~ 主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。 {/timeline-item} {/timeline} -
Redis Geo类型深度解析与实践 介绍 Redis GEO 是 Redis 3.2 版本新增的数据类型,主要用于存储地理位置信息,并对存储的信息进行操作。 在日常生活中,我们越来越依赖搜索“附近的餐馆”、在打车软件上叫车,这些都离不开基于位置信息服务(Location-Based Service,LBS)的应用。LBS 应用访问的数据是和人或物关联的一组经纬度信息,而且要能查询相邻的经纬度范围,GEO 就非常适合应用在 LBS 服务的场景中 内部实现 GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型。 GEO 类型使用 GeoHash 编码方法 实现了 经纬度到 Sorted Set 中元素权重分数的转换 ,这其中的两个关键机制就是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数。 这样一来,我们就可以把经纬度保存到 Sorted Set 中,利用 Sorted Set 提供的“按权重进行有序范围查找”的特性,实现 LBS 服务中频繁使用的“搜索附近”的需求。 常用命令 # 存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。 GEOADD key longitude latitude member [longitude latitude member ...] # 从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。 GEOPOS key member [member ...] # 返回两个给定位置之间的距离。 GEODIST key member1 member2 [m|km|ft|mi] # 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。 GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] 应用场景 滴滴叫车 这里以滴滴叫车的场景为例,介绍下具体如何使用 GEO 命令:GEOADD 和 GEORADIUS 这两个命令。 假设车辆 ID 是 33,经纬度位置是(116.034579,39.030452),我们可以用一个 GEO 集合保存所有车辆的经纬度,集合 key 是 cars:locations。 执行下面的这个命令,就可以把 ID 号为 33 的车辆的当前经纬度位置存入 GEO 集合中 GEOADD cars:locations 116.034579 39.030452 33 当用户想要寻找自己附近的网约车时,LBS 应用就可以使用 GEORADIUS 命令。 例如,LBS 应用执行下面的命令时,Redis 会根据输入的用户的经纬度信息(116.054579,39.030452 ),查找以这个经纬度为中心的 5 公里内的车辆信息,并返回给 LBS 应用。 GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10
-
Redis HyperLogLog类型详细解析 介绍 Redis HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于「 基数统计 」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的, 不是非常准确 ,标准误算率是 0.81%。 所以,简单来说 HyperLogLog 提供不精确的去重计数。 HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的 内存空间总是固定的、并且是很小 的,为大数据而生的,不然的话用集合就好了。 在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。 这什么概念?举个例子给大家对比一下。 用 Java 语言来说,一般 long 类型占用 8 字节,而 1 字节有 8 位,即:1 byte = 8 bit,即 long 数据类型最大可以表示的数是:2^63-1。对应上面的2^64个数,假设此时有2^63-1这么多个数,从 0 ~ 2^63-1,按照long以及1k = 1024 字节的规则来计算内存总数,就是:((2^63-1) * 8/1024)K,这是很庞大的一个数,存储空间远远超过12K,而 HyperLogLog 却可以用 12K 就能统计完。 内部实现 HyperLogLog 的实现涉及到很多数学问题,太费脑子了,我也没有搞懂,如果你想了解一下,课下可以看看这个:HyperLogLog 常见命令 HyperLogLog 命令很少,就三个,所以功能很简单,就是统计去重后的数量。 # 添加指定元素到 HyperLogLog 中 PFADD key element [element ...] # 返回给定 HyperLogLog 的基数估算值。 PFCOUNT key [key ...] # 将多个 HyperLogLog 合并为一个 HyperLogLog PFMERGE destkey sourcekey [sourcekey ...] 应用场景 百万级网页 UV 计数 Redis HyperLogLog 优势在于只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。 所以,非常适合统计百万级以上的网页 UV 的场景。 在统计 UV 时,你可以用 PFADD 命令(用于向 HyperLogLog 中添加新元素)把访问页面的每个用户都添加到 HyperLogLog 中。 PFADD page1:uv user1 user2 user3 user4 user5 接下来,就可以用 PFCOUNT 命令直接获得 page1 的 UV 值了,这个命令的作用就是返回 HyperLogLog 的统计结果。 PFCOUNT page1:uv 不过,有一点需要你注意一下,HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。 这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型
-
Redis BitMap指南和应用 - 详解和教程 介绍 Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。 由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。 内部实现 Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。 String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组 常用命令 bitmap 基本操作 # 设置值,其中value只能是 0 和 1 SETBIT key offset value # 获取值 GETBIT key offset # 获取指定范围内值为 1 的个数 # start 和 end 以字节为单位 BITCOUNT key start end bitmap 运算操作 # BitMap间的运算 # operations 位移操作符,枚举值 AND 与运算 & OR 或运算 | XOR 异或 ^ NOT 取反 ~ # result 计算的结果,会存储在该key中 # key1 … keyn 参与运算的key,可以有多个,空格分割,not运算只能一个key # 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0。返回值是保存到 destkey 的字符串的长度(以字节byte为单位),和输入 key 中最长的字符串长度相等。 BITOP [operations] [result] [key1] [keyn…] # 返回指定key中第一次出现指定value(0/1)的位置 BITPOS [key] [value] 应用场景 Bitmap 类型非常适合二值状态统计的场景,这里的二值状态就是指集合元素的取值就只有 0 和 1 两种,在记录海量数据时,Bitmap 能够有效地节省内存空间。 签到统计 在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。 签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。 假设我们要统计 ID 100 的用户在 2022 年 6 月份的签到情况,就可以按照下面的步骤进行操作。 第一步,执行下面的命令,记录该用户 6 月 3 号已签到。 SETBIT uid:sign:100:202206 2 1 第二步,检查该用户 6 月 3 日是否签到。 GETBIT uid:sign:100:202206 2 第三步,统计该用户在 6 月份的签到次数。 BITCOUNT uid:sign:100:202206 这样,我们就知道该用户在 6 月份的签到情况了。 如何统计这个月首次打卡时间呢? Redis 提供了 BITPOS key bitValue [start] [end]指令,返回数据表示 Bitmap 中第一个值为 bitValue 的 offset 位置。 在默认情况下, 命令将检测整个位图, 用户可以通过可选的 start 参数和 end 参数指定要检测的范围。所以我们可以通过执行这条命令来获取 userID = 100 在 2022 年 6 月份首次打卡日期: BITPOS uid:sign:100:202206 1 需要注意的是,因为 offset 从 0 开始的,所以我们需要将返回的 value + 1 。 判断用户登陆态 Bitmap 提供了 GETBIT、SETBIT 操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。 只需要一个 key = login_status 表示存储用户登陆状态集合数据, 将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过 GETBIT判断对应的用户是否在线。 50000 万 用户只需要 6 MB 的空间。 假如我们要判断 ID = 10086 的用户的登陆情况: 第一步,执行以下指令,表示用户已登录。 SETBIT login_status 10086 1 第二步,检查该用户是否登陆,返回值 1 表示已登录。 GETBIT login_status 10086 第三步,登出,将 offset 对应的 value 设置成 0 SETBIT login_status 10086 0 连续签到用户总数 如何统计出这连续 7 天连续打卡用户总数呢? 我们把每天的日期作为 Bitmap 的 key,userId 作为 offset,若是打卡则将 offset 位置的 bit 设置成 1。 key 对应的集合的每个 bit 位的数据则是一个用户在该日期的打卡记录。 一共有 7 个这样的 Bitmap,如果我们能对这 7 个 Bitmap 的对应的 bit 位做 『与』运算。同样的 UserID offset 都是一样的,当一个 userID 在 7 个 Bitmap 对应对应的 offset 位置的 bit = 1 就说明该用户 7 天连续打卡。 结果保存到一个新 Bitmap 中,我们再通过 BITCOUNT 统计 bit = 1 的个数便得到了连续打卡 7 天的用户总数了。 Redis 提供了 BITOP operation destkey key [key ...]这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。 operation 可以是 and、OR、NOT、XOR。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0 。空的 key 也被看作是包含 0 的字符串序列。 假设要统计 3 天连续打卡的用户数,则是将三个 bitmap 进行 AND 操作,并将结果保存到 destmap 中,接着对 destmap 执行 BITCOUNT 统计,如下命令: # 与操作 BITOP AND destmap bitmap:01 bitmap:02 bitmap:03 # 统计 bit 位 = 1 的个数 BITCOUNT destmap 即使一天产生一个亿的数据,Bitmap 占用的内存也不大,大约占 12 MB 的内存(10^8/8/1024/1024),7 天的 Bitmap 的内存开销约为 84 MB。同时我们最好给 Bitmap 设置过期时间,让 Redis 删除过期的打卡数据,节省内存。
-
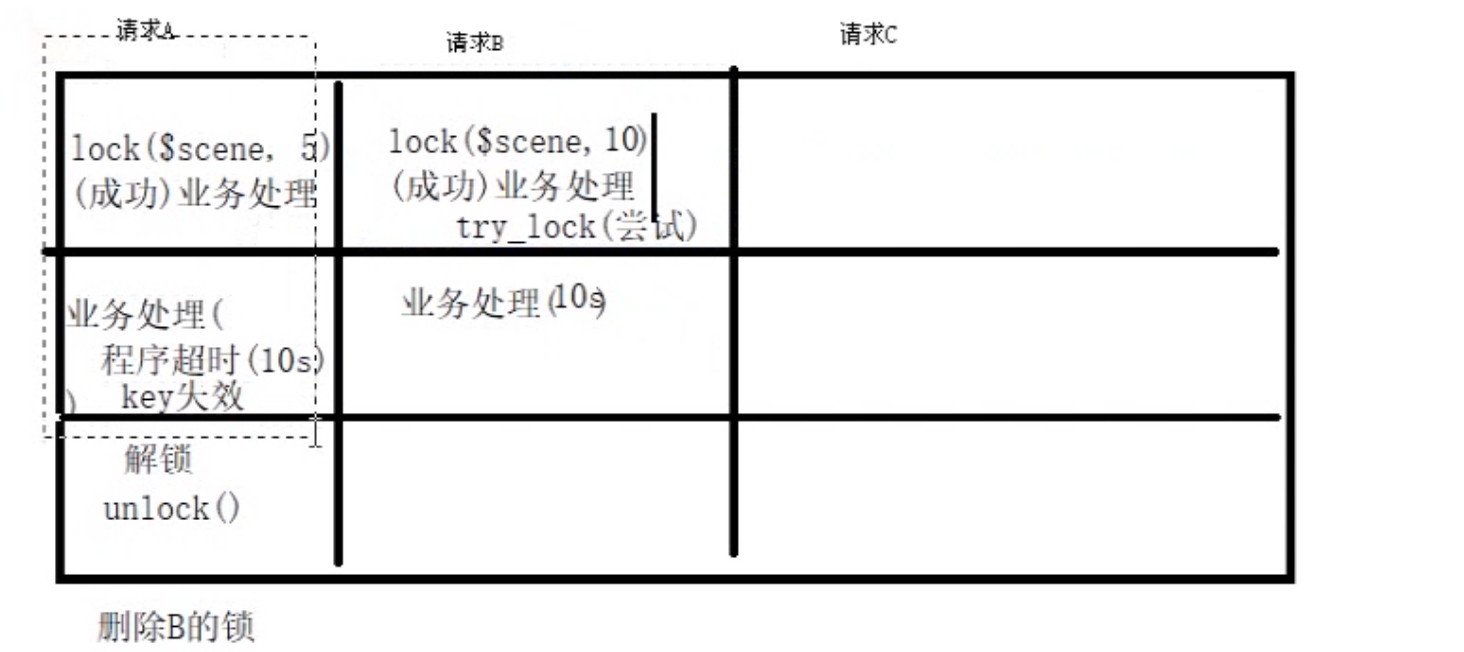
Redis分布式锁解决方案:抢票、秒杀并发问题优化 概述 锁是保护一些共享的资源,这个资源通常会发生竞争。 场景 以下代码,如果5秒内有多个请求,就会超卖 $redis = new Redis(); $redis->connect('127.0.0.1', 6379); $num = $redis->get('num'); if ($num < 1) { // 两个客户端并发执行的时候,因为前面的库存还没执行到增加num sleep(5);// 模拟购买逻辑时间 $store = $redis->incr('num'); var_dump($store); } else { echo '已经卖完'; } 单机锁 上述的问题,我们可以用文件锁的方法,不过这文件通常只能放在一台机器中,如果有多台机器的话,就会有问题 if (flock($fp,LOCK_EX)) {// 加悲观排他锁阻塞等待 fwrite($fp,"lock success\n"); sleep(5); flock($fp,LOCK_UN);// 解锁 } else { echo "文件被其它进程占用"; } fclose($fp); 我们还可以通过数据库的行锁进行锁定 select * from erp_storage where id = 1 for update; 分布式锁 分布式锁的基本条件: 互斥性。在任意时刻,只有一个客户端能持有锁。 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。 铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了,即不能误解锁。例如下例中,请求a的业务逻辑时间太长,导致锁缓存过期失效,请求b就获取到了锁,然后这个时候请求a业务逻辑执行完成了,要释放锁了,就把请求b的锁给释放了 以下代码符合上述条件 <?php class Lock { private $redis; private $clientUniqueId; public function __construct() { $this->redis = new Redis(); $this->redis->connect('127.0.0.1', 6379); } public function lock($scene = '小米11库存', $expire = 5, $retry = 5, $sleep = 1) { $res = false; while ($retry > 0) { // 获取锁,要多次尝试,不能一次返回 $value = session_create_id(); // 获取唯一字符 $this->clientUniqueId = $value; $res = $redis->set($scene, $value, [ 'NX', // 不存在则设置,也就是没有锁就加锁 'EX' => $expire, // 防止死锁,万一加锁后没有解锁,会自动释放锁 ]); if ($res) { // 加锁成功后返回 break; } echo "尝试获取锁"; sleep($sleep); $retry--; } } public function unlock($scene) { // $value = $this->redis->get($scene); // if ($value == $this->clientUniqueId) {// 不能删除掉别人的锁 // 正好锁过期了,这个时候,客户端b能获取到锁,这里就会把客户端b的锁给删除 // sleep(5);//极端情况下,可能这里会有io阻塞,导致把别人的锁给删除了 // $this->redis->del($scene); // } // KEYS类似全局变量 $script = <<<LUA local key=KEYS[1] local value=ARGV[1] if(redis.call('get','key') == value) then return redis.call('del',key) end LUA; // 为了保证原子性,get和del一起执行,不能分开执行 $this->redis->eval($script,[$scene,$this->clientUniqueId]); } }
-
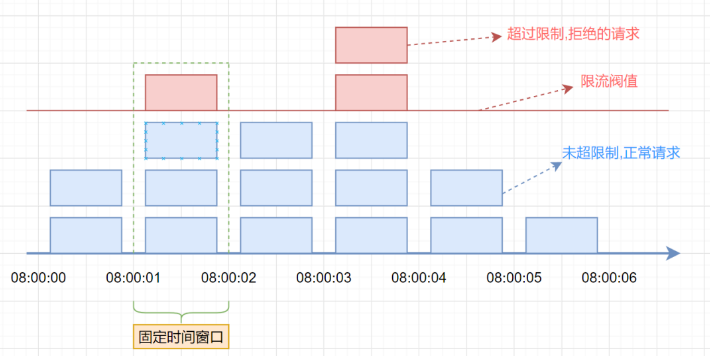
3种简单的限流算法解析与实现 固定窗口限流算法 首维护一个计数器,将单位时间段当做一个窗口,计数器记录这个窗口接收请求的次数。 当次数少于限流阀值,就允许访问,并且计数器+1 当次数大于限流阀值,就拒绝访问。 当前的时间窗口过去之后,计数器清零。 假设单位时间是1秒,限流阀值为3。在单位时间1秒内,每来一个请求,计数器就加1,如果计数器累加的次数超过限流阀值3,后续的请求全部拒绝。等到1s结束后,计数器清0,重新开始计数。如下图: 伪代码如下: /** * 固定窗口时间算法 * @return */ boolean fixedWindowsTryAcquire() { long currentTime = System.currentTimeMillis(); //获取系统当前时间 if (currentTime - lastRequestTime > windowUnit) { //检查是否在时间窗口内 counter = 0; // 计数器清0 lastRequestTime = currentTime; //开启新的时间窗口 } if (counter < threshold) { // 小于阀值 counter++; //计数器加1 return true; } return false; } 但是,这种算法有一个很明显的临界问题:假设限流阀值为5个请求,单位时间窗口是1s,如果我们在单位时间内的前0.8-1s和1-1.2s,分别并发5个请求。虽然都没有超过阀值,但是如果算0.8-1.2s,则并发数高达10,已经超过单位时间1s不超过5阀值的定义啦。 滑动窗口限流算法 滑动窗口限流解决固定窗口临界值的问题。它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。 一张图解释滑动窗口算法,如下: 假设单位时间还是1s,滑动窗口算法把它划分为5个小周期,也就是滑动窗口(单位时间)被划分为5个小格子。每格表示0.2s。每过0.2s,时间窗口就会往右滑动一格。然后呢,每个小周期,都有自己独立的计数器,如果请求是0.83s到达的,0.8~1.0s对应的计数器就会加1。 我们来看下滑动窗口是如何解决临界问题的? 假设我们1s内的限流阀值还是5个请求,0.8~1.0s内(比如0.9s的时候)来了5个请求,落在黄色格子里。时间过了1.0s这个点之后,又来5个请求,落在紫色格子里。如果是固定窗口算法,是不会被限流的,但是滑动窗口的话,每过一个小周期,它会右移一个小格。过了1.0s这个点后,会右移一小格,当前的单位时间段是0.2~1.2s,这个区域的请求已经超过限定的5了,已触发限流啦,实际上,紫色格子的请求都被拒绝啦。 TIPS: 当滑动窗口的格子周期划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越。 滑动窗口算法伪代码实现如下: /** * 单位时间划分的小周期(单位时间是1分钟,10s一个小格子窗口,一共6个格子) */ private int SUB_CYCLE = 10; /** * 每分钟限流请求数 */ private int thresholdPerMin = 100; /** * 计数器, k-为当前窗口的开始时间值秒,value为当前窗口的计数 */ private final TreeMap<Long, Integer> counters = new TreeMap<>(); /** * 滑动窗口时间算法实现 */ boolean slidingWindowsTryAcquire() { long currentWindowTime = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) / SUB_CYCLE * SUB_CYCLE; //获取当前时间在哪个小周期窗口 int currentWindowNum = countCurrentWindow(currentWindowTime); //当前窗口总请求数 //超过阀值限流 if (currentWindowNum >= thresholdPerMin) { return false; } //计数器+1 counters.get(currentWindowTime)++; return true; } /** * 统计当前窗口的请求数 */ private int countCurrentWindow(long currentWindowTime) { //计算窗口开始位置 long startTime = currentWindowTime - SUB_CYCLE* (60s/SUB_CYCLE-1); int count = ; //遍历存储的计数器 Iterator<Map.Entry<Long, Integer>> iterator = counters.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Long, Integer> entry = iterator.next(); // 删除过期的子窗口计数器 if (entry.getKey() < startTime) { iterator.remove(); } else { //累加当前窗口的所有计数器之和 count =count + entry.getValue(); } } return count; } 滑动窗口算法虽然解决了固定窗口的临界问题,但是还是有一些问题:因为滑动窗口算法,需要将请求记录起来,然后下次请求来的时候,要把过期的请求清空,然后再计算数量,这个比较耗费时间,thinkphp6的Throttle中间件就是这个算法。 class Throttle { /** * 缓存对象 * @var Cache */ protected $cache; /** * 配置参数 * @var array */ protected $config = [ // 缓存键前缀,防止键值与其他应用冲突 'prefix' => 'throttle_', // 节流规则 true为自动规则 'key' => true, // 节流频率 null 表示不限制 eg: 10/m 20/h 300/d 'visit_rate' => null, // 访问受限时返回的http状态码 'visit_fail_code' => 429, // 访问受限时访问的文本信息 'visit_fail_text' => 'Too Many Requests', ]; protected $wait_seconds = 0; protected $duration = [ 's' => 1, 'm' => 60, 'h' => 3600, 'd' => 86400, ]; protected $need_save = false; protected $history = []; protected $key = ''; protected $now = 0; protected $num_requests = 0; protected $expire = 0; public function __construct(Cache $cache, Config $config) { $this->cache = $cache; $this->config = array_merge($this->config, $config->get('throttle', [])); } /** * 生成缓存的 key * @param Request $request * @return null|string */ protected function getCacheKey($request) { $key = $this->config['key']; if ($key instanceof \Closure) { $key = call_user_func($key, $this, $request); } if (null === $key || false === $key || null === $this->config['visit_rate']) { // 关闭当前限制 return; } if (true === $key) { $key = $request->ip(); } elseif (false !== strpos($key, '__')) { $key = str_replace(['__CONTROLLER__', '__ACTION__', '__IP__'], [$request->controller(), $request->action(), $request->ip()], $key); } return md5($this->config['prefix'] . $key); } /** * 解析频率配置项 * @param $rate * @return array */ protected function parseRate($rate) { list($num, $period) = explode("/", $rate); $num_requests = intval($num); $duration = $this->duration[$period] ?? intval($period); return [$num_requests, $duration]; } /** * 计算距离下次合法请求还有多少秒 * @param $history * @param $now * @param $duration * @return void */ protected function wait($history, $now, $duration) { $wait_seconds = $history ? $duration - ($now - $history[0]) : $duration; if ($wait_seconds < 0) { $wait_seconds = 0; } $this->wait_seconds = $wait_seconds; } /** * 请求是否允许 * @param $request * @return bool */ protected function allowRequest($request) { $key = $this->getCacheKey($request); if (null === $key) { return true; } list($num_requests, $duration) = $this->parseRate($this->config['visit_rate']); $history = $this->cache->get($key, []); $now = time(); // 移除过期的请求的记录 $history = array_values(array_filter($history, function ($val) use ($now, $duration) { return $val >= $now - $duration; })); if (count($history) < $num_requests) { // 允许访问 $this->need_save = true; $this->key = $key; $this->now = $now; $this->history = $history; $this->expire = $duration; $this->num_requests = $num_requests; return true; } $this->wait($history, $now, $duration); return false; } /** * 处理限制访问 * @param Request $request * @param Closure $next * @return Response */ public function handle($request, Closure $next) { $allow = $this->allowRequest($request); if (!$allow) { // 访问受限 $code = $this->config['visit_fail_code']; $content = str_replace('__WAIT__', $this->wait_seconds, $this->config['visit_fail_text']); $response = Response::create($content)->code($code); $response->header(['Retry-After' => $this->wait_seconds]); return $response; } $response = $next($request); if ($this->need_save && 200 == $response->getCode()) { $this->history[] = $this->now; $this->cache->set($this->key, $this->history, $this->expire); // 将速率限制 headers 添加到响应中 $remaining = $this->num_requests - count($this->history); $response->header([ 'X-Rate-Limit-Limit' => $this->num_requests, 'X-Rate-Limit-Remaining' => $remaining < 0 ? 0: $remaining, 'X-Rate-Limit-Reset' => $this->now + $this->expire, ]); } return $response; } public function setRate($rate) { $this->config['visit_rate'] = $rate; } } 令牌桶算法 面对突发流量的时候,我们可以使用令牌桶算法限流。 令牌桶算法原理: 有一个令牌管理员,根据限流大小,定速往令牌桶里放令牌 如果令牌数量满了,超过令牌桶容量的限制,那就丢弃。 系统在接受到一个用户请求时,都会先去令牌桶要一个令牌。如果拿到令牌,那么就处理这个请求的业务逻辑; 如果拿不到令牌,就直接拒绝这个请求 漏桶算法伪代码实现如下: /** * 每秒处理数(放入令牌数量) */ private long putTokenRate; /** * 后刷新时间 */ private long refreshTime; /** * 令牌桶容量 */ private long capacity; /** * 当前桶内令牌数 */ private long currentToken = 0L; /** * 漏桶算法 * @return */ boolean tokenBucketTryAcquire() { long currentTime = System.currentTimeMillis(); //获取系统当前时间 long generateToken = (currentTime - refreshTime) / 1000 * putTokenRate; //生成的令牌 =(当前时间-上次刷新时间)* 放入令牌的速率 currentToken = Math.min(capacity, generateToken + currentToken); // 当前令牌数量 = 之前的桶内令牌数量+放入的令牌数量 refreshTime = currentTime; // 刷新时间 //桶里面还有令牌,请求正常处理 if (currentToken > 0) { currentToken--; //令牌数量-1 return true; } return false; } 参考 https://z.itpub.net/article/detail/B049B6F216829EDD0827E97BC1AA9100
-
PHP接口与抽象类型的差异性解析 概述 抽象类和接口使用场景 抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。 抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。 例子 举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个抽象类AirplaneAbstract,将鸟设计为一个抽象类BirdAbstract,但是不能将 飞行 这个特性也设计为类,因为它只是一个行为特性,并不是对一类事物的抽象描述。 此时可以将 飞行 设计为一个接口FlyInterFace,包含方法fly( ),然后Airplane和Bird分别根据自己的需要实现Fly这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承Airplane即可,对于鸟也是类似的,不同种类的鸟直接继承Bird类即可。 从这里可以看出, 继承是一个 "是不是"的关系 ,而 接口 实现则是 "有没有"的关系 。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。 // 对飞机这事务进行抽象,包括属性、行为 // 只要是飞机都有这些东西 abstract class AirplaneAbstract { // 飞机有机长 protected $captain; // 飞机有检票,具体各种飞机的检票方式不一样 // 例如:客机需要候机,战斗机刷卡 abstract public function checkIn(); } // 对鸟这事务进行抽象,包括属性、行为 // 只要是鸟都有这些东西,具体怎么吃,要看具体的鸟 abstract class BirdAbstract { // 鸟有性别 protected $sex; // 鸟要吃 abstract public function eat(); } // 对飞的行为的抽象 interface FlyInterFace { // public function fly(); } // 客机 class Airliner extends AirplaneAbstract implements FlyInterFace { public function checkIn() { echo "客机候机检票"; } public function fly() { echo "客机喷气飞行"; } } class Eagle extends GlobalBirdAbstract implements GlobalFlyInterFace { public function eat() { echo "老鹰抓小鸡"; } public function fly() { echo '老鹰翱翔'; } } 注意 需要注意的是,修改抽象类,不一定要修改其之类,例如添加抽象类的方法; 但是修改接口,实现改接口的类都必须修改。
-
深度解析Thinkphp6的事件机制 | PHP开发教程 概述 tp6的事件,是通过观察者模式设计的,事件的基本原理是,首先在系统初始化的时候注册一些监听事件,然后观察事件的触发,只要事件触发的时候就就能执行这些观察者。 事件机制再不修改框架代码的情况下,提升了框架的扩展性。 源码解析 别名功能 事件的别名,触发的时候可以直接触发这个别名,系统自定义的基本事件别名已经写死在事件类的属性里了。 class Event { // 事件的别名,触发的时候可以直接触发这个别名 protected $bind = [ 'AppInit' => event\AppInit::class, ]; // 批量注册别名 public function bind(array $events) { $this->bind = array_merge($this->bind, $events); return $this; } } 事件配置,因为事件相关的配置,最好放在一个配置文件里,所以通过key来分开 return [ 'bind' => [ 'UserLogin' => 'app\event\UserLogin', ], ]; 然后系统初始化加载配置的时候,会批量加载别名,配置文件如下 $this->event->bind($event['bind']); 绑定别名后,就可以通过别名触发事件 $this->event->trigger('AppInit'); 当然这个别名不设置也是可以的,只要触发的时候,直接触发事件类名称就好了,不要触发别名,下面触发事件的方式和上面别名触发的方式效果是一样的 $this->event->trigger(AppInit::class); 需要注意的是,这个别名最好是大写开头,因为事件自动订阅模式,截取on开头后,第一个字符是大写,详情见下面的事件订阅 事件的监听 事件的监听就是观察者,是事件的核心 class Event { // 监听类的类名 protected $listener = []; // 批量注册监听 public function listenEvents(array $events) { foreach ($events as $event => $listeners) { if (isset($this->bind[$event])) { $event = $this->bind[$event]; } $this->listener[$event] = array_merge($this->listener[$event] ?? [], $listeners); } return $this; } // 单个监听 public function listen(string $event, $listener) { if (isset($this->bind[$event])) { $event = $this->bind[$event]; } $this->listener[$event][] = $listener; return $this; } } 由上我门可以知道,监听基本的参数是事件的名称、监听类(到时候会执行监听类里的handle方法)或者闭包,例如批量监听的时候,是通过系统配置的方式 return [ 'listen' => [ 'UserLogin' => ['app\listener\UserLogin'], ], ]; 这个配置文件,会在系统初始化的是被批量注册 $this->event->listenEvents($event['listen']); 当然,我们还可以注册单个 // 类名称,触发的时候会执行UserLogin里的handle方法 Event::listen('UserLogin', UserLogin::class); // 闭包 Event::listen('UserLogin', function($user) { // }); // 对象的具体方法 $this->listen('UserLogin', [$userLoginObject, 'onUserLogin']); 订阅功能 订阅的概念跟关注差不多,类似一次性可以关注多个明星,因此我们也可以一次性订阅多个事件,例如用户相关的事件,可以放在用户订阅类里,这样好管理事件的监听 // 事件类 class Event { // 批量订阅,可以传入字符串或者对象 public function subscribe($subscriber) { // 如果不是数组的,转成数组,支持订阅单个 $subscribers = (array) $subscriber; foreach ($subscribers as $subscriber) { if (is_string($subscriber)) { $subscriber = $this->app->make($subscriber); } // 如果订阅类里有subscribe方法,代表需要手动订阅 if (method_exists($subscriber, 'subscribe')) { // 手动订阅,在该方法里,手工动态监听事件 $subscriber->subscribe($this); } else { // 智能订阅,根据规则,自动注册事件监听 $this->observe($subscriber); } } return $this; } // 根据方法on+事件别名名称的方法,自动注册对应事件监听 public function observe($observer, string $prefix = '') { if (is_string($observer)) { $observer = $this->app->make($observer); } $reflect = new ReflectionClass($observer); $methods = $reflect->getMethods(ReflectionMethod::IS_PUBLIC); if (empty($prefix) && $reflect->hasProperty('eventPrefix')) { $reflectProperty = $reflect->getProperty('eventPrefix'); $reflectProperty->setAccessible(true); $prefix = $reflectProperty->getValue($observer); } foreach ($methods as $method) { $name = $method->getName(); if (0 === strpos($name, 'on')) { $this->listen($prefix . substr($name, 2), [$observer, $name]); } } return $this; } } 同样,我们可以同配置文件,批量订阅 return [ 'subscribe' => [ 'app\subscribe\User', ], ]; 系统初始化的时候,会加载配置文件 if (isset($event['subscribe'])) { $this->event->subscribe($event['subscribe']); } 当然,我们也可以动态订阅 Event::subscribe('app\subscribe\User'); 订阅类有subscribe方法,手动监听到指定的方法 class User { public function onUserLogin($user) { // UserLogin事件响应处理 } public function subscribe(Event $event) { $event->listen('UserLogin', [$this,'onUserLogin']); } } 订阅类没有subscribe方法,自动监听 class User { // UserLogin必须在事件别名 public function onUserLogin($user) { // UserLogin事件响应处理 } } 事件的触发 我们一般在可能需要扩展的地方触发响应的事件,触发逻辑如下所示 class Event { public function trigger($event, $params = null) { // 由此可知,触发可以传入事件类的对象 if (is_object($event)) { // 对象的话,把对象作为参数传入观察者 $params = $event; $event = get_class($event); } // 由此可知,触发可以传入事件类的别名 if (isset($this->bind[$event])) { $event = $this->bind[$event]; } $result = []; $listeners = $this->listener[$event] ?? []; $listeners = array_unique($listeners, SORT_REGULAR); // 执行事件的所有监听 foreach ($listeners as $key => $listener) { // 触发可以传入参数 $result[$key] = $this->dispatch($listener, $params); } // 可以返回每个监听者的返回值 return $result; } // 执行监听者 protected function dispatch($event, $params = null) { if (!is_string($event)) { // 闭包类型的监听者 $call = $event; } elseif (strpos($event, '::')) { // 静态方法类型的监听者 $call = $event; } else { // 类名称类型的监听者 $obj = $this->app->make($event); $call = [$obj, 'handle']; } return $this->app->invoke($call, [$params]); } } 可以通过别名触发 $this->event->trigger("AppInit"); 可以通过,监听类名称触发 $this->event->trigger(AppInit::class); 可以通过对象触发 $this->event->trigger(new UserLogin([ 'login_time'=>time()// 事件对象可以设置一些参数,如果事件对象有这个属性的话 ])); 可以通过静态方法触发,并且传入参数 $this->event->trigger("events\UserLogin::OnLogin",[$userId]);
-
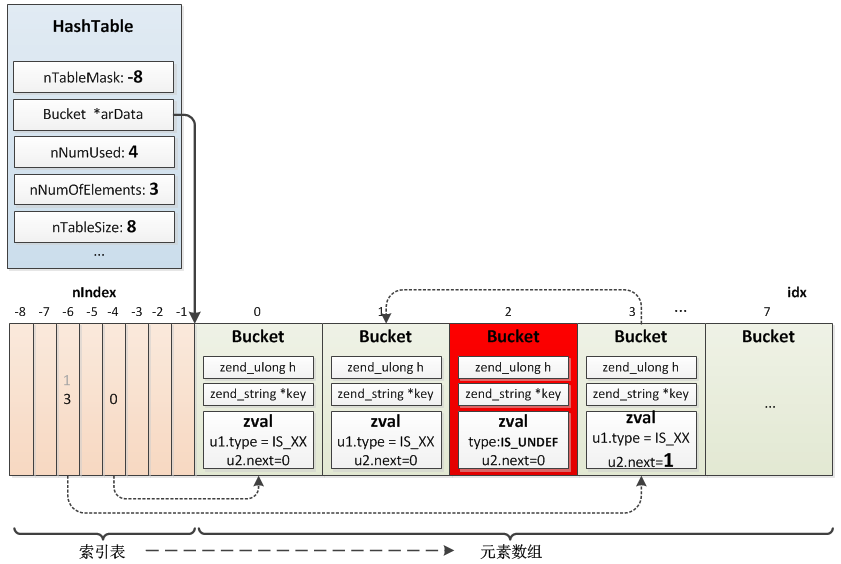
PHP的Hash Map教程:深度解析与应用 概述 php数组原理大概是这样的: 首先有个散列表,然后通过“times 33”hash算法计算key得到一个整形值,把key存在这个位置上;然后要找到这个位置的是,只需要计算key的整型值,与散列的总大小取模得到在散列表中的存储位置了。 由于key的散列表上,存有value的内存地址,所以很快就找到key对于的值了。 //Bucket:散列表中存储的元素 typedef struct _Bucket { zval val; //存储的具体value,这里嵌入了一个zval,而不是一个指针 zend_ulong h; //key根据times 33计算得到的哈希值,或者是数值索引编号 zend_string *key; //存储元素的key } Bucket; //HashTable结构 typedef struct _zend_array HashTable; struct _zend_array { zend_refcounted_h gc; union { struct { ZEND_ENDIAN_LOHI_4( zend_uchar flags, zend_uchar nApplyCount, zend_uchar nIteratorsCount, zend_uchar reserve) } v; uint32_t flags; } u; uint32_t nTableMask; //哈希值计算掩码,等于nTableSize的负值(nTableMask = -nTableSize) Bucket *arData; //存储元素数组,指向第一个Bucket uint32_t nNumUsed; //已用Bucket数 uint32_t nNumOfElements; //哈希表有效元素数 uint32_t nTableSize; //哈希表总大小,为2的n次方 uint32_t nInternalPointer; zend_long nNextFreeElement; //下一个可用的数值索引,如:arr[] = 1;arr["a"] = 2;arr[] = 3; 则nNextFreeElement = 2; dtor_func_t pDestructor; }; arData HashTable中一个非常重要的值arData,存着数组值和数组的key的散列表: 插入数组value元素时按顺序 依次插入 数组,比如第一个元素在arData[0]、第二个在arData[1]...arData[nNumUsed],PHP数组的有序性正是通过arData保证的 key的散列表,是在第一个value元素之前,分配内存时这个散列表与Bucket数组一起分配,因为arData这个值指向存储元素数组的第一个Bucket,所以可以通过arData[-1]、arData[-2]、arData[-3]......来访问到key散列表的位置; 所以,整体来看HashTable主要依赖arData实现元素的存储、索引。插入一个元素时先将元素按先后顺序插入Bucket数组,位置是idx,再根据key的哈希值映射到散列表中的某个位置nIndex,将idx存入这个位置;查找时先在散列表中映射到nIndex,得到value在Bucket数组的位置idx,再从Bucket数组中取出元素。比如: $arr["a"] = 1; $arr["b"] = 2; $arr["c"] = 3; $arr["d"] = 4; unset($arr["c"]); 对应的HashTable如下图所示 nNumUsed、nNumOfElements nNumOfElements哈希表有效元素数,nNumUsed已用Bucket数。 当将一个元素从哈希表删除时并不会将对应的Bucket移除,而是将Bucket存储的zval修改为IS_UNDEF,也就是nNumOfElements数量减少,只有扩容时发现nNumOfElements与nNumUsed相差达到一定数量时才会将已删除的元素全部移除,重新构建哈希表,所以nNumUsed>=nNumOfElements。 哈希碰撞 哈希碰撞是指 不同的key 可能计算得到相同的哈希值(数值索引的哈希值直接就是数值本身),但是这些值又需要插入同一个散列表。一般解决方法是将Bucket串成链表,查找时遍历链表比较key。 最理想的链表是 从上往下,或者从下往上的结构,现在因为有hash冲突 那么整个链表应该是从上往下,或者从下往上 而相同hashcode又在同一行像又拓展,所以key的hash表变成了以下这种方式。 扩容 散列表可存储的value数是固定的,当空间不够用时就要进行扩容了。 PHP散列表的大小为2^n,插入时如果容量不够则首先检查已删除元素所占比例,如果达到阈值,则将已删除元素移除,重建索引,如果未到阈值则进行扩容操作,扩大为当前大小的2倍,将当前Bucket数组复制到新的空间,然后重建索引。 参考 https://github.com/pangudashu/php7-internal/blob/master/2/zend_ht.md
-
深入了解PHP的Zval - PHP内核的关键概念 概述 变量是一个语言实现的基础,变量有两个组成部分:变量名、变量值,PHP中可以将其对应为:zval、zend_value,这两个概念一定要区分开,PHP中变量的内存是通过引用计数进行管理的,而且PHP7中引用计数是在zend_value而不是zval上,变量之间的传递、赋值通常也是针对zend_value。 php7的变量的基础结构: // zend_value结构体,保存具体变量类型的值或指针 typedef union _zend_value { zend_long lval; //int整形 double dval; //浮点型 zend_refcounted *counted; zend_string *str; //string字符串 zend_array *arr; //array数组 zend_object *obj; //object对象 zend_resource *res; //resource资源类型 zend_reference *ref; //引用类型,通过&$var_name定义的 zend_ast_ref *ast; //下面几个都是内核使用的value zval *zv; void *ptr; zend_class_entry *ce; zend_function *func; struct { uint32_t w1; uint32_t w2; } ww; } zend_value; //zend_types.h zval结构体 typedef struct _zval_struct zval; struct _zval_struct { zend_value value; //变量实际的value // u1 主要是用于保存变量的类型 union { struct { ZEND_ENDIAN_LOHI_4( //这个是为了兼容大小字节序,小字节序就是下面的顺序,大字节序则下面4个顺序翻转 zend_uchar type, //变量类型 zend_uchar type_flags, //类型掩码,不同的类型会有不同的几种属性,内存管理会用到 zend_uchar const_flags, zend_uchar reserved) //call info,zend执行流程会用到 } v; uint32_t type_info; //上面4个值的组合值,可以直接根据type_info取到4个对应位置的值 } u1; // 这个值纯粹是个辅助值 union { uint32_t var_flags; uint32_t next; //哈希表中解决哈希冲突时用到 uint32_t cache_slot; /* literal cache slot */ uint32_t lineno; /* line number (for ast nodes) */ uint32_t num_args; /* arguments number for EX(This) */ uint32_t fe_pos; /* foreach position */ uint32_t fe_iter_idx; /* foreach iterator index */ } u2; //一些辅助值 }; 重点:zval的结构体由,一个union类型的zend_value和两个union:u1、u2组成,他们的大小为16个字节。 zend_value根据类型存储各自的值或者指针,对于整型和浮点型这种简单的数值字节存储,否则存的是值的指针,占用8个字节; u1是用于存储变量的类型,变量的类型就通过u1.v.type区分,其它几个应该都是变量的类型,只是不同场景用不同的值。 u2是一个扩展的值。 zvalue结构体 这里举例几个了解下就好。 zvalue标量类型存储 最简单的类型是true、false、long、double、null,其中true、false、null没有value,直接根据type区分,而long、double的值则直接存在value中:zend_long、double,也就是标量类型不需要额外的value指针。 zvalue字符串类型存储 通过指针指向字符串结构体 struct _zend_string { zend_refcounted_h gc;// 变量引用信息,比如当前value的引用数,所有用到引用计数的变量类型都会有这个结构 zend_ulong h; // 哈希值,数组中计算索引时会用到 size_t len; //字符串长度,通过这个值保证二进制安全 char val[1];//字符串内容,变长struct,分配时按len长度申请内存 }; 引用类型 &首先会创建一个zend_reference结构,其内嵌了一个zval,这个zval的value指向原来zval的value(如果是布尔、整形、浮点则直接复制原来的值),然后将原zval的类型修改为IS_REFERENCE,原zval的value指向新创建的zend_reference结构。 struct _zend_reference { zend_refcounted_h gc;// 引用计数 zval val;// }; 例如: $a = "time:" . time(); //$a -> zend_string_1(refcount=1) $b = &$a; //$a,$b -> zend_reference_1(refcount=2) -> zend_string_1(refcount=1) // 通过以下函数可以调试 xdebug_debug_zval('a'); xdebug_debug_zval('b'); 最终的结果如图: 注意:引用只能通过&产生,无法通过赋值传递,比如: $a = "time:" . time(); //$a -> zend_string_1(refcount=1) $b = &$a; //$a,$b -> zend_reference_1(refcount=2) -> zend_string_1(refcount=1) $c = $b; //$a,$b -> zend_reference_1(refcount=2) -> zend_string_1(refcount=2) //$c -> $b = &$a这时候$a、$b的类型是引用,但是$c = $b并不会直接将$b赋值给$c,而是把$b实际指向的zval赋值给$c。 这个也表示PHP中的 引用只可能有一层 ,不会出现一个引用指向另外一个引用的情况 ,也就是没有C语言中指针的指针的概念 内存管理 因为如果对变量都是做拷贝的话,对于字符串、数组、对象等结构,对性能的开销很大,所以php里的方案是:引用计数+写时复制。 引用计数 引用计数是指在value中增加一个字段refcount记录指向当前value的数量,变量复制、函数传参时并不直接硬拷贝一份value数据,而是将refcount++,变量销毁时将refcount--,等到refcount减为0时表示已经没有变量引用这个value,将它销毁即可。 $a = "time:" . time(); //$a -> zend_string_1(refcount=1) $b = $a; //$a,$b -> zend_string_1(refcount=2) $c = $b; //$a,$b,$c -> zend_string_1(refcount=3) unset($b); //$b = IS_UNDEF $a,$c -> zend_string_1(refcount=2) 例外: $a = "hi~"; $b = $a; // $a,$b -> zend_string_1(refcount=0,val="hi~"),引用计数却是0 事实上并不是所有的PHP变量都会用到引用计数,标量:true/false/double/long/null是硬拷贝自然不需要这种机制,但是除了这几个还有两个特殊的类型也不会用到: interned string,内部字符串,我们在PHP中写的所有字符都可以认为是这种类型,比如function name、class name、variable name、静态字符串等等,我们这样定义:$a = "hi~";后面的字符串内容是唯一不变的,这些字符串等同于C语言中定义在静态变量区的字符串:char *a = "hi~";,这些字符串的生命周期为request期间,request完成后会统一销毁释放,自然也就无需在运行期间通过引用计数管理内存。 immutable array,只有在用opcache的时候才会用到这种类型,不清楚具体实现,暂时忽略。 写时复制 多个变量可能指向同一个value,然后通过refcount统计引用数,这时候如果其中一个变量试图更改value的内容则会重新拷贝一份value修改,同时断开旧的指向,写时复制的机制在计算机系统中有非常广的应用,它只有在必要的时候(写)才会发生硬拷贝,可以很好的提高效率,下面从示例看下: $a = array(1,2); $b = &$a; $c = $a; //发生分离 $b[] = 3; 最终的结果: 不是所有类型都可以copy的,比如对象、资源,事实上只有string、array两种支持,与引用计数相同,也是通过zval.u1.type_flag标识value是否可复制的,也就是说变量有个copyable的属性。 变量回收 PHP变量的回收主要有两种:主动销毁、自动销毁。 主动销毁指的就是 unset 而自动销毁就是PHP的自动管理机制,在return时减掉局部变量的refcount,即使没有显式的return,PHP也会自动给加上这个操作,另外一个就是写时复制时会断开原来value的指向,这时候也会检查断开后旧value的refcount。 垃圾回收 PHP变量的回收是根据refcount实现的,当unset、return时会将变量的引用计数减掉,如果refcount减到0则直接释放value,这是变量的简单gc过程,但是实际过程中出现gc无法回收导致内存泄漏的bug,先看下一个例子: $a = [1]; $a[] = &$a; unset($a); unset($a)之前引用关系: 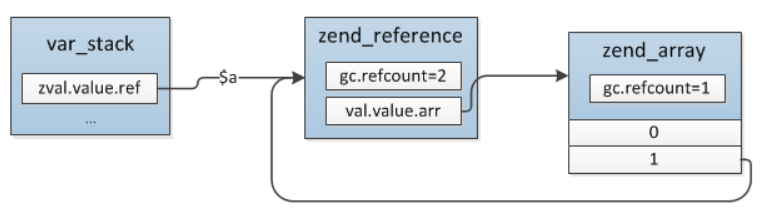 unset($a)之后 可以看到,unset($a)之后由于数组中有子元素指向$a,所以refcount > 0,无法通过简单的gc机制回收,这种变量就是垃圾,垃圾回收器要处理的就是这种情况,目前垃圾只会出现在array、object两种类型中,所以只会针对这两种情况作特殊处理:当销毁一个变量时,如果发现减掉refcount后仍然大于0,且类型是IS_ARRAY、IS_OBJECT则将此value放入gc可能垃圾双向链表中,等这个链表达到一定数量后启动检查程序将所有变量检查一遍,如果确定是垃圾则销毁释放。 参考 https://github.com/pangudashu/php7-internal/blob/master/2/zval.md