搜索到
37
篇与
的结果
-

-
深入理解设计模式 - 精通面向对象编程 设计模式 介绍 面向对象编程里有 6 大原则和 24 种设计模式。 什么是设计模式 设计模式是一套被反复使用、容易被他人理解的、可靠的代码设计经验的总结。 设计模式的目的是为了更好的代码重用性,可读性,可靠性和可维护性。 设计模式的种类 23 种设计模式里,可以按照以下 3 种进行分类: 创建型:如何创建对象 结构型:如何实现类和对象的组合的 行为型:类或者对象怎样交互,以及怎样分配职责 有一个“简单工厂模式”不属于Gof23种设计模式,但是大部分设计模式的书籍里,都会对它进行专门的介绍,所以目前设计模式的种类可以分为: GoF的23种设计模式+简单工厂模式 = 24种设计模式 六大原则 单一职责原则 (Single Responsibility Principle) 指的是:类和方法的职能要单一。这样做好处非常多:可以降低复杂度,提高代码的重用性、可靠性、可读性、可维护性。所以这个原则很重要,一定要满足! 尽量避免方法功能的重复,不然不知道情况的人,就不知道调用哪个方法了,容易造成困扰。 对于php代码来说,就是class和method职责要单一 对于go语言来说,就是结构体和method职责要单一 但是,也要不能拆分的过细,不然类就会太多,耦合度就高,要追求高内聚,低耦合 package main import "fmt" type WorkerClothes struct { } func (w WorkerClothes) Style() { fmt.Println("穿工作服") } type ShopClothes struct { } func (s ShopClothes) Style() { fmt.Println("穿工作服") } func main() { // 每个类的职责单一,即使两个方法打印的结果都是一样,也不会歧义 // 只需要从类的职责上就可以发现,一个是工作服,一个是逛街衣服 wc := WorkerClothes{} wc.Style() sc := ShopClothes{} sc.Style() } 里是替换原则(Liskov Substitution Principle) 指的是:将一个基类对象替换成它的子类对象,程序将不会有任何问题,主要是对类继承的一种约束,这样做好处是不会破坏原来的职能,提升可靠性: 不能随便继承不合适的、有多余方法或属性的类。(例子 1) 子类可以扩展父类的功能(比如增加方法),但不能改变父类原有的功能 (比如覆盖父类非抽象方法)。(例子 2) package main import "fmt" // 抽象层 type Car interface { Run() } type Driver interface { Drive(car Car) } // 实现层,依赖抽象 type Benz struct { } func (b Benz) Run() { fmt.Println("benz is running...") } type Bwm struct { } func (b Bwm) Run() { fmt.Println("bwm is running....") } type ZhangSang struct { } func (z ZhangSang) Drive(car Car) { car.Run() } type LiSi struct { } func (l LiSi) Drive(car Car) { car.Run() } // 业务层,也要依赖抽象 func main() { var benz Car // 依赖抽象 benz = new(Benz) var zs Driver // 依赖抽象 zs = new(ZhangSang) zs.Drive(benz) var bwm Car // 依赖抽象 bwm = new(Bwm) var ls Driver // 依赖抽象 ls = new(LiSi) ls.Drive(bwm) } 依赖倒置原则 (Dependence Inversion Principle) 指的是:依赖于抽象接口,不要依赖具体实现类,也就是针对接口编程。 如果保证业务逻辑层向下依赖抽象层,实现层向上依赖抽象层,这样我们只需要关心抽象层有什么方法即可!!,如果依赖具体类,我们还得去看具体类有哪些方法。 package main import "fmt" // 抽象层 type Car interface { Run() } type Driver interface { Drive(car Car) } // 实现层,依赖抽象 type Benz struct { } func (b Benz) Run() { fmt.Println("benz is running...") } type Bwm struct { } func (b Bwm) Run() { fmt.Println("bwm is running....") } type ZhangSang struct { } func (z ZhangSang) Drive(car Car) { car.Run() } type LiSi struct { } func (l LiSi) Drive(car Car) { car.Run() } // 业务层,也要依赖抽象 func main() { var benz Car // 依赖抽象 benz = new(Benz) var zs Driver // 依赖抽象 zs = new(ZhangSang) zs.Drive(benz) var bwm Car // 依赖抽象 bwm = new(Bwm) var ls Driver // 依赖抽象 ls = new(LiSi) ls.Drive(bwm) } <?php interface IRead{ public function getConent(); } // 低层具体类 class Book extends IRead { public function getConent() { echo "很久很久以前"; }; } // 低层具体类 class Newspaper extends IRead { public function getConent() { echo "php的薪资很高"; }; } // 高层通用阅读类,可以阅读各种类型的文章内容 class YueDu { // 不应该直接依赖底层具体模块,例如Book、Newspaper类,而应该依他们的的接口 public read(IRead $iread) { $iread->getConent(); } } 接口隔离原则 (InterfaceSegregation Principles) 接口隔离和单一职责类似,只是接口隔离针对的是接口,接口里的方法都应该和该接口的职能强相关的。这样做的好处是,可以提升接口的重用性、可读性 但是需要注意的是:接口尽量小,但是也不能拆分的太小。 迪米特原则 (Law of Demeter) 又叫做最少知道原则,一个对象应该对其他对象保特最少的了解,要使用的时候只需要调用相应的方法即可。这样做可以提升代码的重用性、可读性、可维护性。 具体做法就是高内聚低耦合: 高内聚:将职能范围内的逻辑都封装在相应方法的里 (某一程度上说也算是单一职责原则) 低耦合:并且该方法要减少依赖,保持功能的独立性 开闭原则 (Open Close Principle) 很重要,写代码的时候,要注意啊自己的代码是否符合开闭原则。 指的是:对扩展开放,对修改关闭。这样做可以提升代码的可靠性。也就是对类的改动,是通过增加代码进行的,而不是修改源码 具体做法是:通过继承的方式,对原来的功能进行扩展,尽量不要去修改原来的功能,因为对旧代码进行修改,会容易出现问题,还要重新测试。 package main import "fmt" type AbstractBanker interface { DoBusi() } type SaveBanker struct { } func (s SaveBanker) DoBusi() { fmt.Println("进行了 存款业务") } // TranferBanker 新增转账业务,只需要增加代码即可,不需要修改原来的存款业务类 type TranferBanker struct { } func (s TranferBanker) DoBusi() { fmt.Println("进行了 转账业务") } func BankBusiness(banker AbstractBanker) { banker.DoBusi() } func main() { sb := SaveBanker{} sb.DoBusi() tb := TranferBanker{} tb.DoBusi() // 可以优化上面的代码 BankBusiness(&SaveBanker{}) BankBusiness(&TranferBanker{}) } 设计模式之-创建型模式 创建型模式的一个重要的思想其实就是封装,利用封装,把直接 new 获得一个对象,改为通过一个封装的类方法获得一个对象。 单例模式 (singleton) 我们把对象的生成从 new 改为通过静态方法的控制,使得我们总是返回同一个实例给调用者,确保了系统只有一个实例。 好处:使用单例模式,则可以避免大量的 new 操作消耗系统资源。 场景: 数据库连接实例使用单例模式,对数据库的操作很频繁,避免一直 new。 框架系统组件,可以设置为单例模式,保证整个框架都是只有一个对象 设计示例:3 私 1 公 class DbMysql { // 私有属性存储对象 private static $ins = null; // 私有化构造函数,避免被外部new private function __construct(){} // 公有静态方法,创建实例 public static function createIns() { if(self::$ins){ self::$ins = new self(); } return self::$ins; } // 私有化克隆方法,避免在类外克隆 private function __clone(){} } 工厂模式 工厂模式是我们最常用的实例化对象模式,是用静态工厂方法代替 new 操作的一种模式。 好处:如果你想要更改所实例化的类名等,则只需更改该工厂方法内容即可,不需逐一寻找代码中具体实例化的地方 (nw 处) 修改了。为系统结构提供灵活的动态扩展机制,减少了耦合。 简单工厂 一个工厂,创建多种对象。如果要创新新的对象,则需要修改工厂类的静态方法 // 简单工厂 class DbMysql { public function connect() { echo "连接mysql"; } } class DbSqlLite { public function connect() { echo "连接sqlLite"; } } class DbFactory { // 一个工厂,可以制造很多不同的商品 public static function createIns($type) { if ($type == 'mysql') { return new DbMysql(); } elseif ($type == 'sqlite') { return new DbSqlLite(); } } } $mysql = DbFactory::createIns('mysql'); $mysql->connect(); 工厂方法模式 每个对象都有专门的工厂类来创建。如果要新增一个类的对象,可以新增一个工厂类来创建,就不需要修改别的工厂,符合开闭原则 interface Db { public function connect(); } class DbMysql implements Db { public function connect() { echo "连接mysql"; } } class DbSqlLite implements Db { public function connect() { echo "连接sqlLite"; } } interface Factory { public static function createIns(); } class MysqlFactory implements Factory { public static function createIns() { return new DbMysql(); } } class SqliteFactory implements Factory { public static function createIns() { return new DbSqlLite(); } } $mysql = MysqlFactory::createIns(); 抽象工厂模式 一个工厂生产多种产品。例如百事公司的苹果汁、香蕉汁都放在百事工厂类里实现 //饮料接口 interface Fruit{ function getFruitName(); } class BaishiAppleFruit implements Fruit{ function getFruitName() { echo '百事苹果味饮料'; } } class BaishiBananaFruit implements Fruit{ function getFruitName() { echo '百事香蕉味饮料'; } } class ColeiAppleFruit implements Fruit{ function getFruitName() { echo '可口可乐苹果味饮料'; } } class ColeBananaFruit implements Fruit{ function getFruitName() { echo '可口可乐香蕉味饮料'; } } //工厂接口 interface FruITFactory{ //生产饮料方法 function makeAppleFruit(); function makeBananaFruit(); } //百事饮料工厂 class BaishiFruitFactory implements FruitFactory{ function makeAppleFruit() { //生产百事苹果饮料 return new BaishiAppleFruit(); } function makeBananaFruit() { //生产百事香蕉饮料 return new BaishiBananaFruit(); } } //可口可乐饮料工厂 class ColeFruitFactory implements FruitFactory{ function makeAppleFruit() { //生产可口可乐苹果饮料 return new ColeiAppleFruit(); } function makeBananaFruit() { //生产可口可乐香蕉味饮料 return new ColeBananaFruit(); } } $baishi_factory = new BaishiFruitFactory(); $baishi_factory->makeAppleFruit()->getFruitName(); $baishi_factory->makeBananaFruit()->getFruitName(); $cole_factory = new ColeFruitFactory(); $cole_factory->makeAppleFruit()->getFruitName(); $cole_factory->makeBananaFruit()->getFruitName(); 设计模式之-结构型模式 解析类和对象的内部结构和外部组合,通过优化程序结构解决模块之间的耦合问题。 适配器模式 比如 php 的返回的数据结构,java 不能解析,可以通过适配器,将返回结果转为 json,然后 java 就可以解析了。 interface Weather{ public function show(); } class PhpWeather implements Weather { public function show(){ $info = ['weather'=>'小雨','tep'=>'6']; // 不能直接改这个,不然违法开闭原则 return serialize($info); } } interface WeatherAdapter{ public function getWeather(); } class JavaWeather implements WeatherAdapter{ protected $weather; public function __construct(Weather $weather) { $this->weather = $weather; } public function getWeather(){ $info = unserialize($this->weather->show()); return json_encode($info); } } PHP 中的数据库操作有 MySQL, MySQLi, PDO 三种,可以用适配器模式统一成一致,使不同的数据库操作,统一成一样的 API。类似的场景还有 cache 适配器,可以将 memcache, redis, file, apc 等不同的缓存函数,统一成一致 装饰器模式 装饰器模式又叫装饰者模式。装饰模式是在不必改变原类文件(修改会违法开闭原则)和使用继承(继承会增加耦合)的情况下,动态地扩展一个对象的功能。它是通过创建一个包装对象,也就是装饰来包裹真实的对象。 interface IComponent { public function display(); } // 不对这个类进行修改和继承 class Person implements IComponent{ protected $name; public function __construct($name) { $this->name = $name; } public function display(){ echo "装饰的{$this->name}"; } } // 装饰类 class Clothes implements IComponent { protected $component; public function Decorate(IComponent $component) { $this->component = $component; } public function display() { if($this->component){ $this->component->display(); } } } class TShirt extends Clothes{ public function display() { echo "T恤"; parent::display(); } } class Shirt extends Clothes { public function display() { echo "衬衫"; parent::display(); } } $qd = new Person('乔丹'); $tShirt = new TShirt(); $tShirt->Decorate($qd); $tShirt->display(); $tShirt = new Shirt(); $tShirt->Decorate($qd); $tShirt->display(); 注册树模式 注册树模式也叫注册模式或注册器模式,顾名思义,注册树就是把对象实例注册到一棵全局的对象树上,需要对象的时候时候就从树上取下来,就好比树上涨的果子,需要的时候就摘一个下来,只是这个对象树果子是摘不完的。 注册树是控制反转(IOC)的思想: 控制:对象创建,属性赋值,对象生命周期管理【Bean 的生命周期】 反转:把管理对象的权限转移给了容器实现,由容器完成对象的管理 正转:使用 new 构造方法创建对象,开发人员掌握了对象的全部过程 <?php class DbMysql{ public function connect() { echo "连接mysql"; } } class DbSqlite { public function connect() { echo "连接mysql"; } } // 注册树(IOC控制反转的思想) class RegisterTree{ protected static $object = []; public static function set($alias,$object) { self::$object[$alias] = $object; } public static function get($alias) { return self::$object[$alias]; } } RegisterTree::set('DbMysql',new DbMysql()); RegisterTree::set('DbSqlite',new DbSqlLite()); $mysql = RegisterTree::get('DbMysql'); $mysql->connect(); 门面模式 门面模式 (Facade) 又称外观模式,用于为子系统中的一组接口提供一个一致的界面门面模式定义了一个高层接口,这个接口使得子系统更加容易使用:引入门面角色之后,用户只需要直接与门面角色交互,用户与子系统之间的复杂关系由门面角色来实现,从而降低了系统的耦合度。 有了门面之后,我们一般不通过注册树进行调用组件,可以通过门面统一来调用,隐藏内部复杂的逻辑,用起来比较方便。 <?php class Camera{ public function turnOn() { echo "打开相机"; } public function turnOff() { echo "关闭相机"; } } class CameraFacade{ public function __callStatic($name, $arguments) { $camera = new Camera(); $camera->$name($arguments); } } CameraFacade::turnOn(); 管道模式 管道 (Pipeline) 设计模式流水线模式,就是将会数据传递到一个任务序列中,管道扮演者流水线的角色,数据在这里被处理然后传递到下一个步骤。 管道需要三个角色:管道、阀门、载荷。 <?php class Pipeline { private $payload; private $pipes = [];// 阀门 public function __construct($payload) { $this->payload = $payload; } public function Pipe($stage) { $this->pipes[] = $stage; return $this; } public function process() { foreach($this->pipes as $pipe){ call_user_func([$pipe,'handle'],$this->payload); } } } class StageOne { public function handle($payload) { echo $payload."是个"; } } class StageTwo { public function handle($payload) { echo "帅哥"; } } $pipeLine = new Pipeline('Joke'); $pipeLine->Pipe(new StageOne())->Pipe(new StageTwo)->process(); 代理模式 代理模式 (Proxy Pattern):构建了透明置于两个不同对象之内的一个对象,从而能够截取或代理这两个对象间的通信或访问。 interface Subject{ public function request(); } class RealSubject implements Subject{ public function request(){ echo "真实操作"; } } class ProxySubject implements Subject{ public $real; public function __construct() { $this->real = new RealSubject(); } // 代理操作 public function request() { echo "代理"; $this->real->request(); } } $proxy = new ProxySubject(); $proxy->request(); 请注意代理模式与装饰器、适配器的区别: 装饰器,一般是对对象进行装饰,其中的方法行为会有增加,以修饰对象为主 适配器,一般会改变方法行为,目的是保持接口的统一但得到不同的实现 代理模式有几种形式:远程代理(例如:第三方接口 SDK)、虚代理(例如:异步加 载图片)、保护代理&智能指引(例如:权限保护),而我们代码实现的最普通的代理,其实就是达代理类来代替真实类的操作 设计模式之-行为型模式 行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。 策略模式 将一组特定的行为和算法封装起来,以适应某些特定的上下文环境,并让它们可以相互替换,这种模式就是策略模式。 多个类只区别在表现行为不同,可以使用 Strategy 模式,在运行时动态选择具体要执行的行为。比如上学,有多种策略:走路,公交,地铁… // 去学校 abstract class Strategy { abstract function goSchool(); } // 跑着去 class Run extends Strategy { public function goSchool() { // TODO: Implement goSchool() method. } } // 走路去 class Subway extends Strategy { public function goSchool() { // TODO: Implement goSchool() method. } } // 骑自行车去 class Bike extends Strategy { public function goSchool() { // TODO: Implement goSchool() method. } } // 上下文 class Context { protected $_stratege;//存储传过来的策略对象 public function goSchoole() { $this->_stratege->goSchoole(); } } //调用: $contenx = new Context(); $avil_stratery = new Subway(); $contenx->goSchoole($avil_stratery);// 选择走路去 观察者模式 观察者模式属于行为模式,是定义对象间的一种 一对多 的依赖关系,以便当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动刷新。 当一个对象状态发生改变后,会影响到其他几个对象的改变,这时候可以用观察者模式。 观察者模式符合接口隔离原则,实现了对象之间的松散耦合。 角色: 被观察对象:部门领导,可以有各个不同的部门领导 观察者:相当于公司前台的角色,当部门领导请假后,前台通知该部门的员工 主题对象:相当于部门员工,有很多部门的员工,每个部门的员工可以增加或减少,当被通知领导请假后,就可以玩手机了 // 主题接口 interface Subject{ public function register(Observer $observer); public function notify(); } // 观察者接口 interface Observer{ public function watch(); } // 主题 class Action implements Subject{ public $_observers=[]; public function register(Observer $observer){ $this->_observers[]=$observer; } public function notify(){ foreach ($this->_observers as $observer) { $observer->watch(); } } } // 观察者 class Cat1 implements Observer{ public function watch(){ echo "Cat1 watches TV<hr/>"; } } class Dog1 implements Observer{ public function watch(){ echo "Dog1 watches TV<hr/>"; } } class People implements Observer{ public function watch(){ echo "People watches TV<hr/>"; } } // 调用实例 $action=new Action(); $action->register(new Cat1()); $action->register(new People()); $action->register(new Dog1()); $action->notify(); 场景:一个事件发生后,要执行一连串更新操作。传统的编程方式,就是在事件的代码之后直接加入处理的逻辑。当更新的逻辑增多之后,代码会变得难以维护。 这种方式是耦合的,侵入式的 ,增加新的逻辑需要修改事件的主体代码。 具体例子,可以看 thinkphp6 的事件机制 命令模式 命令模式,也称为动作或者事务模式 如用餐厅举列,菜单是这个实际的命令,服务员是这个命令的发送者,而厨师是这个命令的接收者。 那么,这个模式解决了什么呢?当你要修改菜单的时候,只需要和服务员说就好了,她会转达给厨师,也就是说,我们实现了顾客和厨师的解耦。也就是调用者与实现者的解耦。 但是命令模式能够做到的是让一个命令接收者实现多个命令(服务员下单、拿酒水、上菜),或者把一条命令转达给多个实现者(热菜厨师、凉菜厨师、主食师傅)。 <?php class Invoker { // 命令发送者(服务员) private $command = []; public function setCommand(Command $command) { $this->command[] = $command; } public function exec() { // 创建 if (count($this->command) > 0) { foreach ($this->command as $command) { $command->execute(); } } } public function undo() { // 撤销 if (count($this->command) > 0) { foreach ($this->command as $command) { $command->undo(); } } } } abstract class Command { // 执行命令内容(菜单) protected $receiver; protected $state; protected $name; public function __construct(Receiver $receiver, $name) { $this->receiver = $receiver; $this->name = $name; } abstract public function execute(); } class ConcreteCommand extends Command { // 具体命令内容 public function execute() { // 具体创建方法 if (!$this->state || $this->state == 2) { $this->receiver->action(); $this->state = 1; } else { echo $this->name . '命令正在执行,无法再次执行了!', PHP_EOL; } } public function undo() { // 具体取消方法 if ($this->state == 1) { $this->receiver->undo(); $this->state = 2; } else { echo $this->name . '命令未执行,无法撤销了!', PHP_EOL; } } } class Receiver { // 命令接收者(厨师) public $name; public function __construct($name) { $this->name = $name; } public function action() { echo $this->name . '命令执行了', PHP_EOL; } public function undo() { echo $this->name . '命令撤销了', PHP_EOL; } } // 命令发送者(服务员) $invoker = new Invoker(); // 命令接收者(厨师) $receiverA = new Receiver('A'); // 具体执行的命令内容(菜单) $commandOne = new ConcreteCommand($receiverA, 'A'); // 执行命令 $invoker->setCommand($commandOne); $invoker->exec(); $invoker->undo(); // 新加一个单独的执行者,只执行一个命令 $invokerA = new Invoker(); $invokerA->setCommand($commandOne); $invokerA->exec(); // 命令A已经执行了,再次执行全部的命令执行者,A命令的state判断无法生效 $invoker->exec(); 迭代器模式 迭代器模式是遍历集合的成熟模式,迭代器模式的关键是将遍历集合的任务交给一个叫做迭代器的对象,它的工作时遍历并选择序列中的对象,而客户端程序员不必知道或关心该集合序列底层的结构。 迭代器模式 (lterator), 又叫做游标 (Cursor) 模式。提供一种方法访问一个容器 (Container) 对象中各个元素,而又不需暴露该对象的内部细节。 thinkphp6 里的模型集合,就是用迭代器进行遍历,实现 Iterrator 接口就好了。 参考 < https://www.bilibili.com/video/BV1vK4y1375m/?p=22&spm_id_from=pageDriver&vd_source=c38eab5c82d0c7cca57364b72f733942> https://www.bilibili.com/video/BV1cg411e7mJ/?spm_id_from=pageDriver&vd_source=c38eab5c82d0c7cca57364b72f733942
-
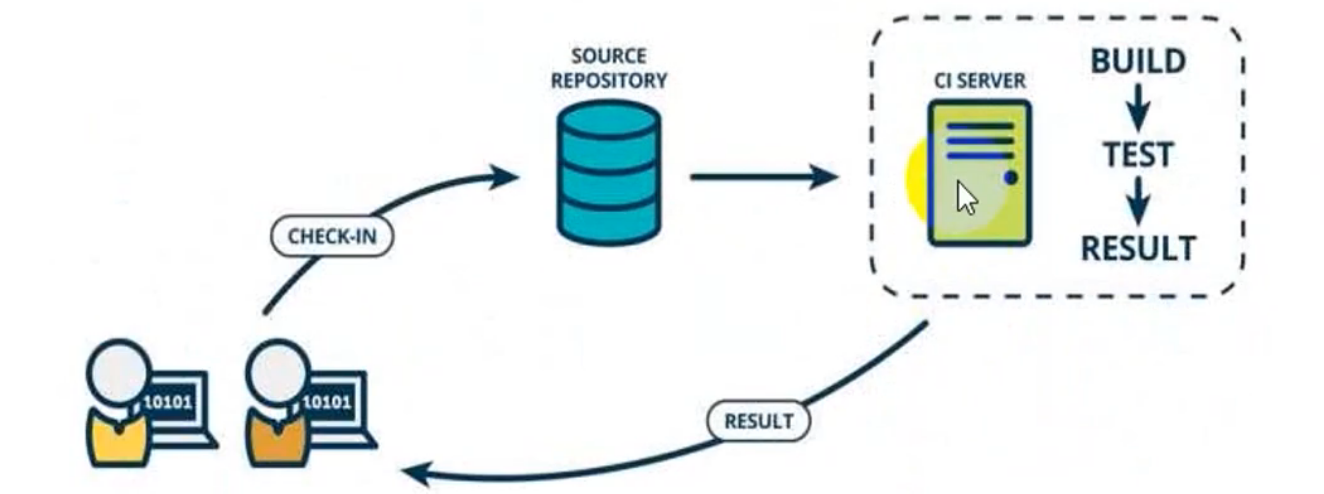
深入理解持续集成 | 进阶编程技巧 持续集成 持续集成(Continuous integration)指的是频繁地(一天多次)将代码集成到主干(也就是develop和master分支)。 它的好处主要有两个: 快速发现错误。每完成一点功能,就集成到主干,可以快速的让测试先测试,定位错误也比较容易。 防止分支大幅偏离主干master分支。如果不是经常集成,主干又在不断更新,会导致以后很难合并到master。 Martin Fowler说过,"持续集成并不能消除Bug,而是让它们非常容易发现和改正。" 开发人员提交了新代码到仓库,然后会立刻进行build、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起。 持续交付 持续交付(Continuous delivery)指的是频繁地将软件的新版本,交付给质量团队或者用户,以供评审。如果评审通过,代码就进入生产阶段。 持续交付可以看作持续集成的下一步。它强调的是,不管怎么更新,软件是随时随地可以交付的。 持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」(production:like environments)中。比如我们完成单元测试后,可以把代码部屠到连接数据库的Staging环境中更多的测试。如果代码没有问题,可以继续手动部署到生产环境中。 持续部署 持续部署(continuous deployment)是持续交付的下一步,指的是代码通过评审以后,自动部署到生产环境(持续交付是必须手工部署到生产环境)。 持续部署的目标是,代码在任何时刻都是可部署的,可以进入生产阶段。 持续部署的前提是能自动化完成测试、构建、部署等步骤。
-
PHP7的改进和新特性:全面解析 性能的提升 可以分别通过php5.6和php7,对源码下的zend目录下的bench.php文件和micro_bench.php文件进行测试,会发现php7的执行速度明细的提高。 太空船的操作符 操作符号<=>就很像太空船,该操作符可可以用于快速的比较大小,不过感觉平时用的很少 echo 1 <=> 0; // 1,左边大于右边1 echo 1 <=> 1; // 0,左边等于右边0 echo 1 <=> 2; // -1,左边 标量类型申明 在团队合作的时候,我们经常想要说我们写的方法,需要调用者严格按照我们的规范来调用,避免一些问题,所以就需要对参数进行严格的限制 // 这个必须写,不然如果传入其它类型还是不会报错 declare(strict_types=1); $page = isset($_GET['page']) ? $_GET['page'] : 1; $page = $_GET['page'] ?? 1; null合并运算符
-
Rabbit MQ 高级特性详解 - 深入了解并掌握Rabbit MQ的高级功能 ack 应答机制 ack就是生产者,通过设置回调函数,当rabbitmq接收到消息后,会执行这个回调函数,这样生产者就知道消息已经被接收到了。 保证消息100%投递成功 方案一 首先建立一张表,当推送消息的时候,先把消息插入表,并且状态设置为0,当rabbitmq接收到消息后,在生产者的回调函数里将这条消息状态设置为1。同时,有一个定时任务,每隔一段时间,将状态为0的消息再推送一遍即可。这样就可以保证所有消息都会被发送。 但是,由于对数据插入消息;而且这种模式,生产者需要回调。这两步操作都是在生产者端完成的,都会消耗生产者的性能。对于生产者而言,一般都是针对用户的,我们希望做的事情越少越好,以提高对用户的响应时间。 方案二 首先建立一张表,推送消息的时候,先把消息插入表A,当rabbitmq收到消息后,在消费者里,可以把结果插入表B。同时,可以通过定时任务进行比较这两张表,把表A中存在,但是表B中不存在的消息再推送一遍即可。 冥等性 在业务高峰期,容易产生消息重复消费的情况,当消费者消费完消息后,再给生产者返回ack后,由于网络中断,导致生产者还以为没有消费数据,重新推送了消息。又或者用户可能快速点击两下,发送了两条一样的消息。而con-冥等性就是保证消息不会被多次消费。 解决办法有很多,比如用mysql的唯一键对消息进行约束。 return机制 往rabbitmq里发送消息,如果交换机存在,路由键不存在,php不会报任何的错误,所以如果失败了我们就不知道失败的原因是什么。这个时候生产者需要有个return监听器,类似ack机制里的回调函数,这个函数里就知道返回状态。 限流机制 为何要限流:生产者突然往rabbitmq发送上万条消息,单个客户端突然处理这么多消息会导致服务器的负载较大,默认情况下会一次性发送很多消息。 消费者限流api设置:$channel->basic_qos();,可以限制一次性只处理多少条数据,等这些处理完成之后,再发送指定数量的消息过来处理。那么rabbitmq如何知道这些消息已经处理完成了呢,可以通过以下代码来告诉rabbitmq: // 如果没有执行这个的话,rabbitmq就不知道,就不会继续发送消息 $message->delivery_info['channel']->basic_ack([]); 需要注意的是,要把自动确认关闭掉,这样才能用上面的手工确认。 重回队列 有时候消费者拿到消息后,执行的时候会出问题,这个时候会有个容错机制,将消息重新再发送给rabbitmq,希望再下一次拿到消息的时候能够执行成功。 $message->nack(true); TTL 代表消息再队列里可以存在的时间,超过时间后,消息就消失了。 // 设置10秒 $args->set('x-message-ttl',10000); 死信队列 比如消息设置ttl,到期后消息消失了,但是我们有时候还是想要知道原来的消息的内容是什么,死信队列就好比回收站,我们可以设置一个死信队列存放这类消息,可以让消失的消息放到死新队列里。 当队列达到最大长度的时候,我们也可以设置死信队列,将消息放到这里。 $args->set('x-dead-letter-exchange','exchange.dlx'); $args->set('x-dead-routing-key','routingkey'); ...
-
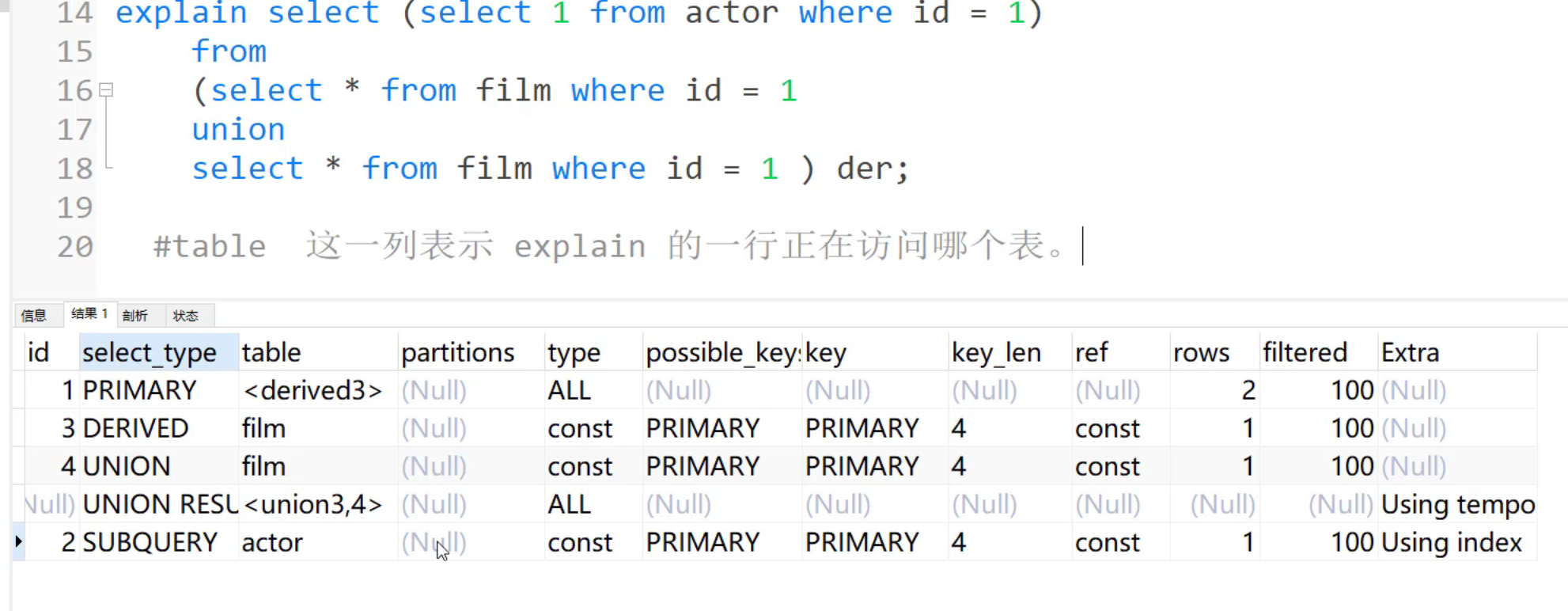
深入理解MySQL执行计划 - 实用指南 explain字段列说明 如果想要MySQL给一些提示的话,可以用explain extended 语句。 id id的编号是select的序列号,有几个select就有几个id,并且id的顺序是按select出现的顺序增长的,分析的时候,只要按这个id的顺序来对应sql语句的哪个部分就好了。需要注意的是,explian的多行记录,如果是一个select语句里完成的,那么id是一样的,即使id一样,也是按从上到下的顺序解析执行计划。 id为1的,在多表关联的时候是驱动表 如果没有id的话,代表的是中间的计算结果,例如union result select_type 查询类型,说明查询的种类,select_type有很多种类型 sample,最简单查询,查询不包含子查询和union联合查询,大多数sql都是这个 primary,复杂查询中最外层的select,通常这个是出现在第一行,一看到primary,就知道这肯定是个嵌套循环了,是驱动表 derived,派生查询,包含在from子句中的子查询,mysql会将结果存放在一个临时表中,也称派生表 union,是指向union关键字之后的查询 union result,因为union联合的话,会去重等操作,得到的结果union result,如果是union all操作,因为没有去重等操作,所以就不会有union result,需要注意的是union result越小越好,如果可能的话,最好不要有union result,因为会产生临时表,是没有索引的,对临时表进行操作,速度必然很慢,所以用union的时候要么就是用union all简单关联,要么union结果要很少 subquery,包含在select中的子查询,也就是select关键字之后的查询 table 表示select操作的是哪个表,如果没有表名的话,例如<union 3,4>,表示对前面id编号的数据进行操作 partitions 表示分区表的意思,如果对mysql设置分区的时候,这一列就会显示我们的表落在哪个分区上 type 这一列表示关联类型或者访问类型,即mysql决定如何查找表中的行,执行效率排序: system, const,代表是常量引用,一般主键或者唯一列筛选,因为只有一行,与参数进行比较,所以比较快 eq_ref,用于关联查询,两个表进行关联查询的时候,通过主键或者唯一值列,和另外一张表的外键进行连接 ref,用于非主键,或者非唯一性索引的检索 fulltext,用的很少 ref_or_null,包含null情况的索引检索 index_merge unique_subquery, index_subquery range,范围检索,通常出现在in,between,>,<,>=,like等操作中,使用一个索引来检索给的范围的行。 index,通过索引做的全表扫描 All,代表存储的全表扫描 possible_keys 这一列显示查询可能使用哪些索引来查找 key 显示最终使用哪个索引来优化,从possible_keys中选的索引。 key_len 这一列显示了mysql在索引里使用的字节数,通过这个值,可以算出具体使用了索引中的那些列,例如索引是int类型,int类型是4个字节,那么Key_len等于4 ref 这一列显示了,在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),func,NULL,字段名(例如:film.id) rows 这一列是mysql explain 记录里,该行估计要读取并检测的行数,注意这个不是结果集里的行数 filtered 代表过滤的意思,是百分比的值,(rows*filtered)/100,这个计算结果表示最终可能的结果,这个结果将于explain结果的上一行对应表产生交互,比如合并交互 Extra 扩展列,用于展示一些额外信息,例如distinc,表示mysql一旦找到了与行相匹配的行,就不再搜索了。 using index,也叫索引覆盖,不会去原始数据中查找数据行,直接返回索引上的值 using where,先读取整行数据,然后再利用where条件进行检查,符合就留下,不符合就丢弃,出现这个表示数据访问效率不是很高 using temporary,表示使用临时表,临时表在内存中计算很慢,如果出现这个,就要进行优化了 using filesort,表示采用文件扫描对结果进行计算排序,效率很低。对于排序,只有select的所有字段和order by字段都被索引覆盖时候,就会使用using index.-- 假设索引是idx_name_ut(name,update_time),这样就可以using index了 select name,update_time from actor order by name; -- 因为order by 的顺序和索引的顺序不一样,所以name用不到索引,会file sort select name,update_time from actor order by update_time,name;
-
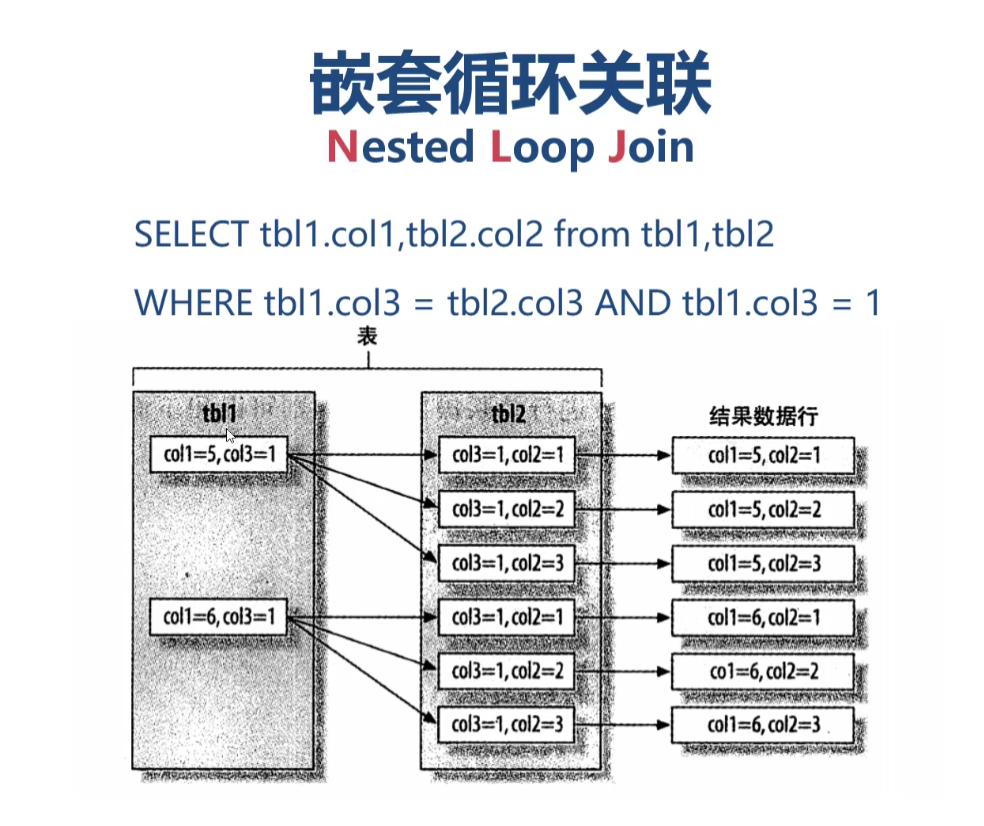
MySQL多表关联优化策略及技巧 嵌套循环关联 嵌套循环关联也叫,Nested Loop Join,简称NLJ。其执行过程大致如下所示: 首先根据条件tbl1.col3 = 1的条件,对左侧外层的表tbl进行筛选,得到两条数据 然后将得到的两条数据带到内层的表tbl2中,根据条件tbl1.col3 = tbl2.col3进行筛选 最后组合数据,输出结果 需要注意的是: 左侧外侧的表叫做驱动表,所以左侧的驱动表的数据越少越好,因为左侧表的数据很多的话,内层的循环数据也很多,查询优化器会优先选择查询结果少的表作为驱动表,确定驱动表的过程是mysql自动为我们进行分析得到的 explain语句,默认第一行出现的表就是驱动表,由查询优化器自动选择 explain语句结果的type字段,All是全表扫描,eq_ref是按主键或者唯一索引联合查询,ref是非主键或唯一索引的等值检索
-
MySQL索引的优化策略 - 如何提高数据库性能 无法使用索引的情况 索引的选择性太差的时候,不会用到索引,也就是重复的太多了,或者查询的范围太大了(个人经验结果大于总数的25%),导致mysql的查询优化器认为,直接对表进行全表扫描还更快,所以执行计划中干脆就不使用索引 <>或者not in,无法使用索引 is null会使用索引,is not null不会使用索引 联合索引要遵循左前缀原则 前缀索引要遵循左前缀原则 对索引列进行计算,或者使用函数进行加工 在WHERE子句中,如果在OR前的条件列是索引列,而在OR后的条件列不是索引列,那么索引会失效。 索引优化排序 单字段排序 假设idx_uid_sid(uid,source_id)复合索引 当排序出现了索引左侧列的时候,则可以使用索引进行排序 左侧字段单字段排序时候,索引可以升降序排序 explain select * from t_content where uid < 1000 order by uid desc; 当排序为索引右侧列的时候,就用到文件排序,using filesort,从排序的角度来看速度是比较慢的 explain select * from t_content where uid < 1000 order by source_id desc; 多字段排序 假设idx_uid_sid(uid,source_id)复合索引: 这个时候,左侧字段必须是升序,且字段的前后顺序不允许 -- 可以索引排序 explain select * from t_content where uid < 1000 order by uid,souce_id asc; -- 左侧字段不是升序排序,无法利用索引进行排序 explain select * from t_content where uid < 1000 order by uid desc,souce_id asc; -- 不可以索引排序,是file sort,因为uid顺序不是索引顺序 explain select * from t_content where uid < 1000 order by source_id,uid asc; 删除冗余索引 percona-toolkit工具 由于开发的时候,大家经常会各建个的索引,导致索引冗余,会占用磁盘空间,对表插入和更新操作的时候,会大量索引的重算, pt-duplicate-key-checker是percona-toolkit工具包中的实用组件,这个工具可以在语法层面上分析冗余索引 它可以帮助你检测表中重复的索引或者主键 首先下载:https://www.percona.com/downloads/percona-toolkit/LATEST/,然后选择对应的版本,直接解压到指定的目录即可 输入以下命令,就可以生成报表: /usr/local/bin/pt-duplicate-key-checker --host=192.168.1.106 --user='mysql' --password='123456' --databases=test --tables=curs sql查看索引运行情况 索引使用状况统计 SELECT object_type, -- 数据库名称 object_schema, -- 表的名称 object_name, -- 索引的名称,如果为null的话说明是进行全表扫描,要排查sql index_name, -- 索引在计算过程中读取了多少行 count_read, -- 查询得到的结果是多少行 count_fetch, -- 通过索引所操作的新增修改删除的数量 count_insert, count_update, count_delete FROM -- 从索引的角度,看下磁盘io的处理情况,相当于日志的统计表 performance_schema.table_io_waits_summary_by_index_usage ORDER BY -- 利用索引查询的总时间,可以看那个索引用的最多 sum_timer_wait DESC; 如果允许一段时间后,查询到的索引统计值都为0,说明索引没有被使用,可以删除 减少表和索引碎片 window系统中有一个碎片扫描和整理程序,它的作用是让我们的系统的文件更有效的组织在一起,让我们的io更加的流畅。在mysql中也存在这个问题,无论是表还是索引,在数据进行频繁的新增修改删除以后,往往都需要重新组织,但是在组织的过程中,必不可少的会有一些空间上的浪费,以及数据组织上的不合理的地方,如下两个命令就是用于解决这个问题的: analyze table 表名 这个是索引重新统计。mysql底层对数据状况的重新统计,这个很重要,查询优化器优化sql是基于这个统计信息,对于innodb这种存储引擎,这种统计信息是一个估算值,频繁修改数据后,可能会导致统计信息不准确,隔一段时间有必要重新计算这些统计信息 optimize table 表名 这个是优化表空间,释放表空间。innodb的聚集索引,数据在磁盘中是顺序排列的,但是当数删除等操作的是,就会导致数据数据之间有间隙,并且无法被利用,这个命令就可以重新组织数据,重新利用这些间隙,查询效率就会提高。 执行这条命令会锁表,所以执行这条命令,要在维护期间执行,否则造成io阻塞。而且数据量很大的是,执行时间会很长。
-
PHP的Yield用法详细教程 基础特性 一个函数中有yield出现的话,这个函数就是生成器 function &gen_reference() { $value = 3; while ($value > 0) { yield $value; } // 如果省略则函数返回null return true; } var_dump(gen_reference()); // object(Generator)#1 (0) {} 既然是生成器,执行顺序就和生成器的顺序是一样的,如下下所示: // 使用引用生成值 function gen_reference() { $value = 3; while ($value > 0) { yield $value; $value -= 1; echo 2; } return 1; } $gen = gen_reference();// 初始化 // 执行gen_reference函数,直到阻塞在yield,然后这里继续往下执行,输出1 // foreach刚开始相当于调用这个方法 // 一开始调用rewind,valid,current,key,next方法都会开始执行函数里的内容 $gen->rewind(); echo 1; $gen->valid(); // 获取yield的值,gen_reference方法还是阻塞在yield $val1 = $gen->current(); // 多次调用current还是得到当前值,也就是3,,gen_reference方法还是阻塞在yield $val2 = $gen->current(); // 获取yield的key,gen_reference方法还是阻塞在yield $key1 = $gen->key(); // 多次调用key还是得到当前值,也就是0,gen_reference方法还是阻塞在yield $key2 = $gen->key(); $gen->next(); 也可以用foreach自动执行上述流程,方法前面要加& function &gen_reference() { $value = 3; while ($value > 0) { yield $value; } } // 引用的方式,会自动修改函数了的value值 foreach (gen_reference() as &$number) { echo (--$number).'... '; } 应用 读取大文件 可以使用迭代器读取超过10个G的大文件 function readTxt() { $handle = fopen("./test.txt", 'rb'); while (feof($handle) === false) { yield fgets($handle); } fclose($handle); } foreach (readTxt() as $key => $value) { sleep(1); echo $value; } 协程 和go的协程不一样的是,这个协程需要自己调度,并且不能并行执行,可以通过共享变量的方式进行通信 class Coroutine { /** * @param callable $callback * @return Generator */ public static function create(callable $callback): Generator { // 调用含有yield的函数,是返回Generator实例 return (function () use ($callback) { // 把各自的逻辑封装在闭包里,等待调用执行 yield $callback; })(); } /** * 分配各个生成器的执行 * @param array $cos * @throws Exception */ public static function run(array $cos) { $cnt = count($cos); while ($cnt > 0) { $loc = random_int(0, $cnt - 1); // 用 random 模拟调度策略。 // 取出指定的闭包,并且执行,其实这个跟自己在数组里定义闭包,然后随机执行某个数组元素的闭包是一样的 // 所以这种实现的方式,优势在哪里呢? // 应该是在于,如果yield后还有值的话,可以实现逻辑可以执行到一半的时候,将控制器返给主程序 $cos[$loc]->current()(); array_splice($cos, $loc, 1); $cnt--; } } } $co = new Coroutine(); $cos = []; for ($i = 1; $i <= 10; $i++) { // 初始化生成器 $cos[] = $co::create(function () use ($i) { echo "Co.{$i}.", PHP_EOL; }); } $co::run($cos); 生成大数组 function xrange($start,$limit) { for($i = $start;$i<=$limit;$i++){ yield $i; } } // 使用生成器,可以用于迭代 foreach (xrange(0,10) as $number) { echo $number; } // 这个会报错,不支持这样的方式 echo count(xrange(0,1000));
-
MySQL Memory存储引擎 - 深入解析和应用实践 概述 不支持事务 内存读写,临时存储,重启后数据丢失,所以还是redis好 超高的读写效率 表级锁,并发性差,所以还是redis好 Memory存储引擎默认使用哈希索引 不支持TEXT和BLOB列类型 最重要的是,存储变长字段(varchar)时是按照定常字段(char)的方式进行的,因此会浪费内存(这个问题之前已经提到,eBay的工程师Igor Chernyshev已经给出了patch解决方案)。 此外有一点容易被忽视,MySQL数据库使用Memory存储引擎作为临时表来存放查询的中间结果集(intermediate result))。如果中间结果集大于Memory存储引擎表的容量设置,又或者中间结果含有TEXT或BLOB列类型字段,则MySQL数据库会把其转换到MyISAM存储引擎表而存放到磁盘中。之前提到MyISAM不缓存数据文件,因此这时产生的临时表的性能对于查询会有损失。 应用场景 读多写少的静态数据,例如省市区,不过重启会丢失数据 当缓存使用,有个redis不具备的优点是,可以使用sql语句 执行排序分组时候,自动创建的系统临时表,如果中间结果超过内存表的限制,就会以myisam格式存在磁盘上 关键参数 -- 最大存储设置2gb,数据量超过会报错,修改这个值,在新的连接中才会生效 set global max_heap_table_size = 2147483648 -- 临时表最大的值,<= 最大存储,如果超过的话会以myisam存在磁盘 set global tmp_table_size = 2147483648 存储文件 在数据目录下:数据目录/数据库名称的文件夹下/有一个文件 表名.frm,表的定义文件,不需要有数据文件,因为存储在了内存