搜索到
37
篇与
的结果
-
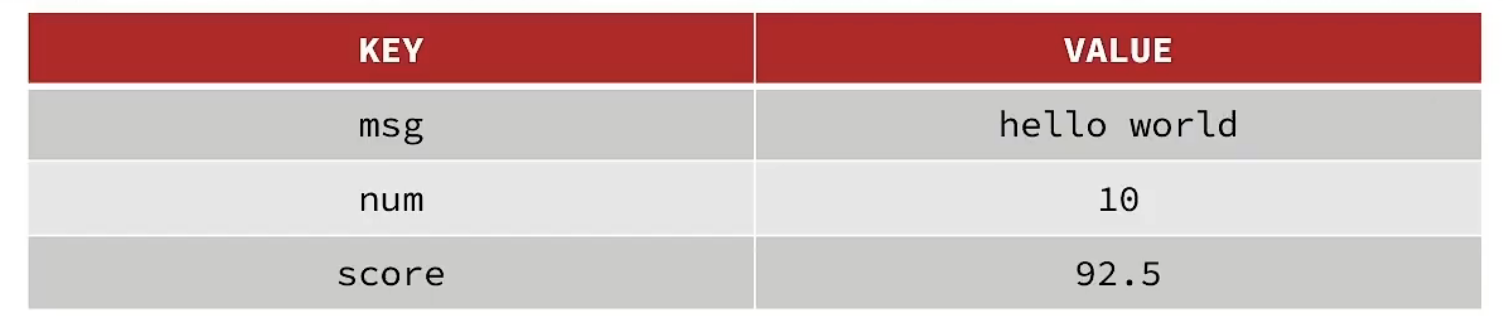
 redis 字符串string键值相关的命令 介绍 String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value其实不仅是 字符串 ,也可以是 数字(整数或浮点数) ,value 最多可以容纳的数据长度是 512M。 内部实现 String 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串)。 SDS 和我们认识的 C 字符串不太一样,之所以没有使用 C 语言的字符串表示,因为 SDS 相比于 C 的原生字符串: SDS 不仅可以保存文本数据,还可以保存二进制数据 。因为 SDS 使用 len 属性的值而不是空字符来判断字符串是否结束,并且 SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在 buf[] 数组里的数据。所以 SDS 不光能存放文本数据,而且能保存图片、音频、视频、压缩文件这样的二进制数据。 SDS 获取字符串长度的时间复杂度是 O(1) 。因为 C 语言的字符串并不记录自身长度,所以获取长度的复杂度为 O(n);而 SDS 结构里用 len 属性记录了字符串长度,所以复杂度为 O(1)。 Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出 。因为 SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题。 字符串对象的内部编码(encoding)有 3 种 :int、raw和 embstr 如果一个字符串对象保存的是整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成 long),并将字符串对象的编码设置为int。 如果字符串对象保存的是一个字符串,并且这个字符申的长度小于等于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为embstr, embstr编码是专门用于保存短字符串的一种优化编码方式: 如果字符串对象保存的是一个字符串,并且这个字符串的长度大于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为raw: 注意,embstr 编码和 raw 编码的边界在 redis 不同版本中是不一样的: 注意,embstr 编码和 raw 编码的边界在 redis 不同版本中是不一样的: redis 3.0-4.0 是 39 字节 redis 5.0 是 44 字节 可以看到embstr和raw编码都会使用SDS来保存值,但不同之处在于embstr会通过一次内存分配函数来分配一块连续的内存空间来保存redisObject和SDS,而raw编码会通过调用两次内存分配函数来分别分配两块空间来保存redisObject和SDS。Redis这样做会有很多好处: embstr编码将创建字符串对象所需的内存分配次数从 raw 编码的两次降低为一次; 释放 embstr编码的字符串对象同样只需要调用一次内存释放函数; 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用 CPU 缓存提升性能。 但是 embstr 也有缺点的: 如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,所以embstr编码的字符串对象实际上是只读的,redis没有为embstr编码的字符串对象编写任何相应的修改程序。当我们对embstr编码的字符串对象执行任何修改命令(例如append)时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。 SDS 字符串在 Redis 中是很常用的,键值对中的键是字符串类型,值有时也是字符串类型。 Redis 是用 C 语言实现的,但是它没有直接使用 C 语言的 char* 字符数组来实现字符串,而是自己封装了一个名为简单动态字符串(simple dynamic string,SDS) 的数据结构来表示字符串,也就是 Redis 的 String 数据类型的底层数据结构是 SDS。 既然 Redis 设计了 SDS 结构来表示字符串,肯定是 C 语言的 char* 字符数组存在一些缺陷。 要了解这一点,得先来看看 char* 字符数组的结构。 C 语言字符串的缺陷 C 语言的字符串其实就是一个字符数组,即数组中每个元素是字符串中的一个字符。 比如,下图就是字符串“xiaolin”的 char* 字符数组的结构: 没学过 C 语言的同学,可能会好奇为什么最后一个字符是“\0”? 在 C 语言里,对字符串操作时,char * 指针只是指向字符数组的起始位置,而字符数组的结尾位置就用“\0”表示,意思是指字符串的结束。 因此,C 语言标准库中的字符串操作函数就通过判断字符是不是 “\0” 来决定要不要停止操作,如果当前字符不是 “\0” ,说明字符串还没结束,可以继续操作,如果当前字符是 “\0” 是则说明字符串结束了,就要停止操作。 举个例子,C 语言获取字符串长度的函数 strlen,就是通过字符数组中的每一个字符,并进行计数,等遇到字符为 “\0” 后,就会停止遍历,然后返回已经统计到的字符个数,即为字符串长度。下图显示了 strlen 函数的执行流程: 很明显,C 语言获取字符串长度的时间复杂度是 O(N)(这是一个可以改进的地方) C 语言字符串用 “\0” 字符作为结尾标记有个缺陷。假设有个字符串中有个 “\0” 字符,这时在操作这个字符串时就会提早结束,比如 “xiao\0lin” 字符串,计算字符串长度的时候则会是 4,如下图: 因此,除了字符串的末尾之外,字符串里面不能含有 “\0” 字符,否则最先被程序读入的 “\0” 字符将被误认为是字符串结尾,这个限制使得 C 语言的字符串只能保存文本数据,不能保存像图片、音频、视频文化这样的二进制数据(这也是一个可以改进的地方) 另外, C 语言标准库中字符串的操作函数是很不安全的,对程序员很不友好,稍微一不注意,就会导致缓冲区溢出。 举个例子,strcat 函数是可以将两个字符串拼接在一起。 //将 src 字符串拼接到 dest 字符串后面 char *strcat(char *dest, const char* src); C 语言的字符串是不会记录自身的缓冲区大小的,所以 strcat 函数假定程序员在执行这个函数时,已经为 dest 分配了足够多的内存,可以容纳 src 字符串中的所有内容,而一旦这个假定不成立,就会发生缓冲区溢出将可能会造成程序运行终止,(这是一个可以改进的地方)。 而且,strcat 函数和 strlen 函数类似,时间复杂度也很高,也都需要先通过遍历字符串才能得到目标字符串的末尾。然后对于 strcat 函数来说,还要再遍历源字符串才能完成追加,对字符串的操作效率不高。 好了, 通过以上的分析,我们可以得知 C 语言的字符串不足之处以及可以改进的地方: 获取字符串长度的时间复杂度为 O(N); 字符串的结尾是以 “\0” 字符标识,字符串里面不能包含有 “\0” 字符,因此不能保存二进制数据; 字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止; Redis 实现的 SDS 的结构就把上面这些问题解决了,接下来我们一起看看 Redis 是如何解决的。 SDS 结构设计 下图就是 Redis 5.0 的 SDS 的数据结构: 结构中的每个成员变量分别介绍下: len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。 alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。 flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。 buf[],字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。 总的来说,Redis 的 SDS 结构在原本字符数组之上,增加了三个元数据:len、alloc、flags,用来解决 C 语言字符串的缺陷。 O(1)复杂度获取字符串长度 C 语言的字符串长度获取 strlen 函数,需要通过遍历的方式来统计字符串长度,时间复杂度是 O(N)。 而 Redis 的 SDS 结构因为加入了 len 成员变量,那么获取字符串长度的时候,直接返回这个成员变量的值就行,所以复杂度只有 O(1)。 二进制安全 因为 SDS 不需要用 “\0” 字符来标识字符串结尾了,而是有个专门的 len 成员变量来记录长度,所以可存储包含 “\0” 的数据。但是 SDS 为了兼容部分 C 语言标准库的函数, SDS 字符串结尾还是会加上 “\0” 字符。 因此, SDS 的 API 都是以处理二进制的方式来处理 SDS 存放在 buf[] 里的数据,程序不会对其中的数据做任何限制,数据写入的时候时什么样的,它被读取时就是什么样的。 通过使用二进制安全的 SDS,而不是 C 字符串,使得 Redis 不仅可以保存文本数据,也可以保存任意格式的二进制数据。 不会发生缓冲区溢出 C 语言的字符串标准库提供的字符串操作函数,大多数(比如 strcat 追加字符串函数)都是不安全的,因为这些函数把缓冲区大小是否满足操作需求的工作交由开发者来保证,程序内部并不会判断缓冲区大小是否足够用,当发生了缓冲区溢出就有可能造成程序异常结束。 所以,Redis 的 SDS 结构里引入了 alloc 和 len 成员变量,这样 SDS API 通过 alloc - len 计算,可以算出剩余可用的空间大小,这样在对字符串做修改操作的时候,就可以由程序内部判断缓冲区大小是否足够用。 而且,当判断出缓冲区大小不够用时,Redis 会自动将扩大 SDS 的空间大小(小于 1MB 翻倍扩容,大于 1MB 按 1MB 扩容),以满足修改所需的大小。 在扩展 SDS 空间之前,SDS API 会优先检查未使用空间是否足够,如果不够的话,API 不仅会为 SDS 分配修改所必须要的空间,还会给 SDS 分配额外的「未使用空间」。 这样的好处是,下次在操作 SDS 时,如果 SDS 空间够的话,API 就会直接使用「未使用空间」,而无须执行内存分配,有效的减少内存分配次数。 所以,使用 SDS 即不需要手动修改 SDS 的空间大小,也不会出现缓冲区溢出的问题。 节省内存空间 SDS 结构中有个 flags 成员变量,表示的是 SDS 类型。 Redis 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。 这 5 种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同。 比如 sdshdr16 和 sdshdr32 这两个类型,它们的定义分别如下: struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; uint16_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; uint32_t alloc; unsigned char flags; char buf[]; }; 可以看到: sdshdr16 类型的 len 和 alloc 的数据类型都是 uint16_t,表示字符数组长度和分配空间大小不能超过 2 的 16 次方。 sdshdr32 则都是 uint32_t,表示表示字符数组长度和分配空间大小不能超过 2 的 32 次方。 之所以 SDS 设计不同类型的结构体,是为了能灵活保存不同大小的字符串,从而有效节省内存空间。比如,在保存小字符串时,结构头占用空间也比较少。 除了设计不同类型的结构体,Redis 在编程上还使用了专门的编译优化来节省内存空间,即在 struct 声明了 __attribute__ ((packed)) ,它的作用是:告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐。 比如,sdshdr16 类型的 SDS,默认情况下,编译器会按照 2 字节对齐的方式给变量分配内存,这意味着,即使一个变量的大小不到 2 个字节,编译器也会给它分配 2 个字节。 举个例子,假设下面这个结构体,它有两个成员变量,类型分别是 char 和 int,如下所示: #include <stdio.h> struct test1 { char a; int b; } test1; int main() { printf("%lu\n", sizeof(test1)); return 0; } 大家猜猜这个结构体大小是多少?我先直接说答案,这个结构体大小计算出来是 8。 这是因为默认情况下,编译器是使用「字节对齐」的方式分配内存,虽然 char 类型只占一个字节,但是由于成员变量里有 int 类型,它占用了 4 个字节,所以在成员变量为 char 类型分配内存时,会分配 4 个字节,其中这多余的 3 个字节是为了字节对齐而分配的,相当于有 3 个字节被浪费掉了。 如果不想编译器使用字节对齐的方式进行分配内存,可以采用了 __attribute__ ((packed)) 属性定义结构体,这样一来,结构体实际占用多少内存空间,编译器就分配多少空间。 比如,我用 __attribute__ ((packed)) 属性定义下面的结构体 ,同样包含 char 和 int 两个类型的成员变量,代码如下所示: #include <stdio.h> struct __attribute__((packed)) test2 { char a; int b; } test2; int main() { printf("%lu\n", sizeof(test2)); return 0; } 这时打印的结果是 5(1 个字节 char + 4 字节 int)。 可以看得出,这是按照实际占用字节数进行分配内存的,这样可以节省内存空间。 命令 普通字符串的基本操作 # 设置 key-value 类型的值 > SET name lin OK # 根据 key 获得对应的 value > GET name "lin" # 判断某个 key 是否存在 > EXISTS name (integer) 1 # 返回 key 所储存的字符串值的长度 > STRLEN name (integer) 3 # 删除某个 key 对应的值 > DEL name (integer) 1 批量设置 只能简单的设置,没有set命令的哪些高级参数。 # 批量设置 key-value 类型的值 > MSET key1 value1 key2 value2 OK # 批量获取多个 key 对应的 value > MGET key1 key2 1) "value1" 2) "value2" 计数器 整数计数,字符串的内容为整数的时候可以使用 # 设置 key-value 类型的值 > SET number 0 OK # 将 key 中储存的数字值增一 > INCR number (integer) 1 # 将key中存储的数字值加 10 > INCRBY number 10 (integer) 11 # 将 key 中储存的数字值减一 > DECR number (integer) 10 # 将key中存储的数字值键 10 > DECRBY number 10 (integer) 0 浮点数计数,字符串的内容为浮点数的时候可以使用 INCRBYFLOAT num 0.5 INCRBYFLOAT num -0.5 过期 默认为永不过期 # 设置 key 在 60 秒后过期(该方法是针对已经存在的key设置过期时间) > EXPIRE name 60 (integer) 1 # 查看数据还有多久过期 > TTL name (integer) 51 #设置 key-value 类型的值,并设置该key的过期时间为 60 秒 # 还可以设置毫秒失效,时间戳失效啥的,具体看文档 > SET key value EX 60 OK > SETEX key 60 value OK 不存在就插入 # 不存在就插入(not exists) >SETNX key value (integer) 1 # 上面的命令,是这个命令的简写 > SET name lin NX OK 应用场景 缓存对象 使用 String 来缓存对象有两种方式: 直接缓存整个对象的 JSON,命令例子: SET user:1 '{"name":"xiaolin", "age":18}' 采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值,命令例子: MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20 key的 层级结构 设计,多个单词用:隔开,如下: 这个格式并非固定,也可以根据自己的需求来删除或添加词条。 然后我们可以把表记录存为json字段 常规计数 因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。 比如计算文章的阅读量: # 初始化文章的阅读量 > SET aritcle:readcount:1001 0 OK #阅读量+1 > INCR aritcle:readcount:1001 (integer) 1 #阅读量+1 > INCR aritcle:readcount:1001 (integer) 2 #阅读量+1 > INCR aritcle:readcount:1001 (integer) 3 # 获取对应文章的阅读量 > GET aritcle:readcount:1001 "3" 分布式锁 主要是利用:SET 命令有个 NX 参数可以实现「key不存在才插入」,可以用它来实现分布式锁 详见:https://www.xiaoqiuyinboke.cn/archives/530.html 共享 session 信息 通常我们在开发后台管理系统时,会使用 Session 来保存用户的会话(登录)状态,这些 Session 信息会被保存在服务器端,但这只适用于单系统应用,如果是分布式系统此模式将不再适用。 因此,我们需要借助 Redis 对这些 Session 信息进行统一的存储和管理,这样无论请求发送到那台服务器,服务器都会去同一个 Redis 获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题。
redis 字符串string键值相关的命令 介绍 String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value其实不仅是 字符串 ,也可以是 数字(整数或浮点数) ,value 最多可以容纳的数据长度是 512M。 内部实现 String 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串)。 SDS 和我们认识的 C 字符串不太一样,之所以没有使用 C 语言的字符串表示,因为 SDS 相比于 C 的原生字符串: SDS 不仅可以保存文本数据,还可以保存二进制数据 。因为 SDS 使用 len 属性的值而不是空字符来判断字符串是否结束,并且 SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在 buf[] 数组里的数据。所以 SDS 不光能存放文本数据,而且能保存图片、音频、视频、压缩文件这样的二进制数据。 SDS 获取字符串长度的时间复杂度是 O(1) 。因为 C 语言的字符串并不记录自身长度,所以获取长度的复杂度为 O(n);而 SDS 结构里用 len 属性记录了字符串长度,所以复杂度为 O(1)。 Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出 。因为 SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题。 字符串对象的内部编码(encoding)有 3 种 :int、raw和 embstr 如果一个字符串对象保存的是整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成 long),并将字符串对象的编码设置为int。 如果字符串对象保存的是一个字符串,并且这个字符申的长度小于等于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为embstr, embstr编码是专门用于保存短字符串的一种优化编码方式: 如果字符串对象保存的是一个字符串,并且这个字符串的长度大于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为raw: 注意,embstr 编码和 raw 编码的边界在 redis 不同版本中是不一样的: 注意,embstr 编码和 raw 编码的边界在 redis 不同版本中是不一样的: redis 3.0-4.0 是 39 字节 redis 5.0 是 44 字节 可以看到embstr和raw编码都会使用SDS来保存值,但不同之处在于embstr会通过一次内存分配函数来分配一块连续的内存空间来保存redisObject和SDS,而raw编码会通过调用两次内存分配函数来分别分配两块空间来保存redisObject和SDS。Redis这样做会有很多好处: embstr编码将创建字符串对象所需的内存分配次数从 raw 编码的两次降低为一次; 释放 embstr编码的字符串对象同样只需要调用一次内存释放函数; 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用 CPU 缓存提升性能。 但是 embstr 也有缺点的: 如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,所以embstr编码的字符串对象实际上是只读的,redis没有为embstr编码的字符串对象编写任何相应的修改程序。当我们对embstr编码的字符串对象执行任何修改命令(例如append)时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。 SDS 字符串在 Redis 中是很常用的,键值对中的键是字符串类型,值有时也是字符串类型。 Redis 是用 C 语言实现的,但是它没有直接使用 C 语言的 char* 字符数组来实现字符串,而是自己封装了一个名为简单动态字符串(simple dynamic string,SDS) 的数据结构来表示字符串,也就是 Redis 的 String 数据类型的底层数据结构是 SDS。 既然 Redis 设计了 SDS 结构来表示字符串,肯定是 C 语言的 char* 字符数组存在一些缺陷。 要了解这一点,得先来看看 char* 字符数组的结构。 C 语言字符串的缺陷 C 语言的字符串其实就是一个字符数组,即数组中每个元素是字符串中的一个字符。 比如,下图就是字符串“xiaolin”的 char* 字符数组的结构: 没学过 C 语言的同学,可能会好奇为什么最后一个字符是“\0”? 在 C 语言里,对字符串操作时,char * 指针只是指向字符数组的起始位置,而字符数组的结尾位置就用“\0”表示,意思是指字符串的结束。 因此,C 语言标准库中的字符串操作函数就通过判断字符是不是 “\0” 来决定要不要停止操作,如果当前字符不是 “\0” ,说明字符串还没结束,可以继续操作,如果当前字符是 “\0” 是则说明字符串结束了,就要停止操作。 举个例子,C 语言获取字符串长度的函数 strlen,就是通过字符数组中的每一个字符,并进行计数,等遇到字符为 “\0” 后,就会停止遍历,然后返回已经统计到的字符个数,即为字符串长度。下图显示了 strlen 函数的执行流程: 很明显,C 语言获取字符串长度的时间复杂度是 O(N)(这是一个可以改进的地方) C 语言字符串用 “\0” 字符作为结尾标记有个缺陷。假设有个字符串中有个 “\0” 字符,这时在操作这个字符串时就会提早结束,比如 “xiao\0lin” 字符串,计算字符串长度的时候则会是 4,如下图: 因此,除了字符串的末尾之外,字符串里面不能含有 “\0” 字符,否则最先被程序读入的 “\0” 字符将被误认为是字符串结尾,这个限制使得 C 语言的字符串只能保存文本数据,不能保存像图片、音频、视频文化这样的二进制数据(这也是一个可以改进的地方) 另外, C 语言标准库中字符串的操作函数是很不安全的,对程序员很不友好,稍微一不注意,就会导致缓冲区溢出。 举个例子,strcat 函数是可以将两个字符串拼接在一起。 //将 src 字符串拼接到 dest 字符串后面 char *strcat(char *dest, const char* src); C 语言的字符串是不会记录自身的缓冲区大小的,所以 strcat 函数假定程序员在执行这个函数时,已经为 dest 分配了足够多的内存,可以容纳 src 字符串中的所有内容,而一旦这个假定不成立,就会发生缓冲区溢出将可能会造成程序运行终止,(这是一个可以改进的地方)。 而且,strcat 函数和 strlen 函数类似,时间复杂度也很高,也都需要先通过遍历字符串才能得到目标字符串的末尾。然后对于 strcat 函数来说,还要再遍历源字符串才能完成追加,对字符串的操作效率不高。 好了, 通过以上的分析,我们可以得知 C 语言的字符串不足之处以及可以改进的地方: 获取字符串长度的时间复杂度为 O(N); 字符串的结尾是以 “\0” 字符标识,字符串里面不能包含有 “\0” 字符,因此不能保存二进制数据; 字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止; Redis 实现的 SDS 的结构就把上面这些问题解决了,接下来我们一起看看 Redis 是如何解决的。 SDS 结构设计 下图就是 Redis 5.0 的 SDS 的数据结构: 结构中的每个成员变量分别介绍下: len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。 alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。 flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。 buf[],字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。 总的来说,Redis 的 SDS 结构在原本字符数组之上,增加了三个元数据:len、alloc、flags,用来解决 C 语言字符串的缺陷。 O(1)复杂度获取字符串长度 C 语言的字符串长度获取 strlen 函数,需要通过遍历的方式来统计字符串长度,时间复杂度是 O(N)。 而 Redis 的 SDS 结构因为加入了 len 成员变量,那么获取字符串长度的时候,直接返回这个成员变量的值就行,所以复杂度只有 O(1)。 二进制安全 因为 SDS 不需要用 “\0” 字符来标识字符串结尾了,而是有个专门的 len 成员变量来记录长度,所以可存储包含 “\0” 的数据。但是 SDS 为了兼容部分 C 语言标准库的函数, SDS 字符串结尾还是会加上 “\0” 字符。 因此, SDS 的 API 都是以处理二进制的方式来处理 SDS 存放在 buf[] 里的数据,程序不会对其中的数据做任何限制,数据写入的时候时什么样的,它被读取时就是什么样的。 通过使用二进制安全的 SDS,而不是 C 字符串,使得 Redis 不仅可以保存文本数据,也可以保存任意格式的二进制数据。 不会发生缓冲区溢出 C 语言的字符串标准库提供的字符串操作函数,大多数(比如 strcat 追加字符串函数)都是不安全的,因为这些函数把缓冲区大小是否满足操作需求的工作交由开发者来保证,程序内部并不会判断缓冲区大小是否足够用,当发生了缓冲区溢出就有可能造成程序异常结束。 所以,Redis 的 SDS 结构里引入了 alloc 和 len 成员变量,这样 SDS API 通过 alloc - len 计算,可以算出剩余可用的空间大小,这样在对字符串做修改操作的时候,就可以由程序内部判断缓冲区大小是否足够用。 而且,当判断出缓冲区大小不够用时,Redis 会自动将扩大 SDS 的空间大小(小于 1MB 翻倍扩容,大于 1MB 按 1MB 扩容),以满足修改所需的大小。 在扩展 SDS 空间之前,SDS API 会优先检查未使用空间是否足够,如果不够的话,API 不仅会为 SDS 分配修改所必须要的空间,还会给 SDS 分配额外的「未使用空间」。 这样的好处是,下次在操作 SDS 时,如果 SDS 空间够的话,API 就会直接使用「未使用空间」,而无须执行内存分配,有效的减少内存分配次数。 所以,使用 SDS 即不需要手动修改 SDS 的空间大小,也不会出现缓冲区溢出的问题。 节省内存空间 SDS 结构中有个 flags 成员变量,表示的是 SDS 类型。 Redis 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。 这 5 种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同。 比如 sdshdr16 和 sdshdr32 这两个类型,它们的定义分别如下: struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; uint16_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; uint32_t alloc; unsigned char flags; char buf[]; }; 可以看到: sdshdr16 类型的 len 和 alloc 的数据类型都是 uint16_t,表示字符数组长度和分配空间大小不能超过 2 的 16 次方。 sdshdr32 则都是 uint32_t,表示表示字符数组长度和分配空间大小不能超过 2 的 32 次方。 之所以 SDS 设计不同类型的结构体,是为了能灵活保存不同大小的字符串,从而有效节省内存空间。比如,在保存小字符串时,结构头占用空间也比较少。 除了设计不同类型的结构体,Redis 在编程上还使用了专门的编译优化来节省内存空间,即在 struct 声明了 __attribute__ ((packed)) ,它的作用是:告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐。 比如,sdshdr16 类型的 SDS,默认情况下,编译器会按照 2 字节对齐的方式给变量分配内存,这意味着,即使一个变量的大小不到 2 个字节,编译器也会给它分配 2 个字节。 举个例子,假设下面这个结构体,它有两个成员变量,类型分别是 char 和 int,如下所示: #include <stdio.h> struct test1 { char a; int b; } test1; int main() { printf("%lu\n", sizeof(test1)); return 0; } 大家猜猜这个结构体大小是多少?我先直接说答案,这个结构体大小计算出来是 8。 这是因为默认情况下,编译器是使用「字节对齐」的方式分配内存,虽然 char 类型只占一个字节,但是由于成员变量里有 int 类型,它占用了 4 个字节,所以在成员变量为 char 类型分配内存时,会分配 4 个字节,其中这多余的 3 个字节是为了字节对齐而分配的,相当于有 3 个字节被浪费掉了。 如果不想编译器使用字节对齐的方式进行分配内存,可以采用了 __attribute__ ((packed)) 属性定义结构体,这样一来,结构体实际占用多少内存空间,编译器就分配多少空间。 比如,我用 __attribute__ ((packed)) 属性定义下面的结构体 ,同样包含 char 和 int 两个类型的成员变量,代码如下所示: #include <stdio.h> struct __attribute__((packed)) test2 { char a; int b; } test2; int main() { printf("%lu\n", sizeof(test2)); return 0; } 这时打印的结果是 5(1 个字节 char + 4 字节 int)。 可以看得出,这是按照实际占用字节数进行分配内存的,这样可以节省内存空间。 命令 普通字符串的基本操作 # 设置 key-value 类型的值 > SET name lin OK # 根据 key 获得对应的 value > GET name "lin" # 判断某个 key 是否存在 > EXISTS name (integer) 1 # 返回 key 所储存的字符串值的长度 > STRLEN name (integer) 3 # 删除某个 key 对应的值 > DEL name (integer) 1 批量设置 只能简单的设置,没有set命令的哪些高级参数。 # 批量设置 key-value 类型的值 > MSET key1 value1 key2 value2 OK # 批量获取多个 key 对应的 value > MGET key1 key2 1) "value1" 2) "value2" 计数器 整数计数,字符串的内容为整数的时候可以使用 # 设置 key-value 类型的值 > SET number 0 OK # 将 key 中储存的数字值增一 > INCR number (integer) 1 # 将key中存储的数字值加 10 > INCRBY number 10 (integer) 11 # 将 key 中储存的数字值减一 > DECR number (integer) 10 # 将key中存储的数字值键 10 > DECRBY number 10 (integer) 0 浮点数计数,字符串的内容为浮点数的时候可以使用 INCRBYFLOAT num 0.5 INCRBYFLOAT num -0.5 过期 默认为永不过期 # 设置 key 在 60 秒后过期(该方法是针对已经存在的key设置过期时间) > EXPIRE name 60 (integer) 1 # 查看数据还有多久过期 > TTL name (integer) 51 #设置 key-value 类型的值,并设置该key的过期时间为 60 秒 # 还可以设置毫秒失效,时间戳失效啥的,具体看文档 > SET key value EX 60 OK > SETEX key 60 value OK 不存在就插入 # 不存在就插入(not exists) >SETNX key value (integer) 1 # 上面的命令,是这个命令的简写 > SET name lin NX OK 应用场景 缓存对象 使用 String 来缓存对象有两种方式: 直接缓存整个对象的 JSON,命令例子: SET user:1 '{"name":"xiaolin", "age":18}' 采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值,命令例子: MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20 key的 层级结构 设计,多个单词用:隔开,如下: 这个格式并非固定,也可以根据自己的需求来删除或添加词条。 然后我们可以把表记录存为json字段 常规计数 因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。 比如计算文章的阅读量: # 初始化文章的阅读量 > SET aritcle:readcount:1001 0 OK #阅读量+1 > INCR aritcle:readcount:1001 (integer) 1 #阅读量+1 > INCR aritcle:readcount:1001 (integer) 2 #阅读量+1 > INCR aritcle:readcount:1001 (integer) 3 # 获取对应文章的阅读量 > GET aritcle:readcount:1001 "3" 分布式锁 主要是利用:SET 命令有个 NX 参数可以实现「key不存在才插入」,可以用它来实现分布式锁 详见:https://www.xiaoqiuyinboke.cn/archives/530.html 共享 session 信息 通常我们在开发后台管理系统时,会使用 Session 来保存用户的会话(登录)状态,这些 Session 信息会被保存在服务器端,但这只适用于单系统应用,如果是分布式系统此模式将不再适用。 因此,我们需要借助 Redis 对这些 Session 信息进行统一的存储和管理,这样无论请求发送到那台服务器,服务器都会去同一个 Redis 获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题。 -
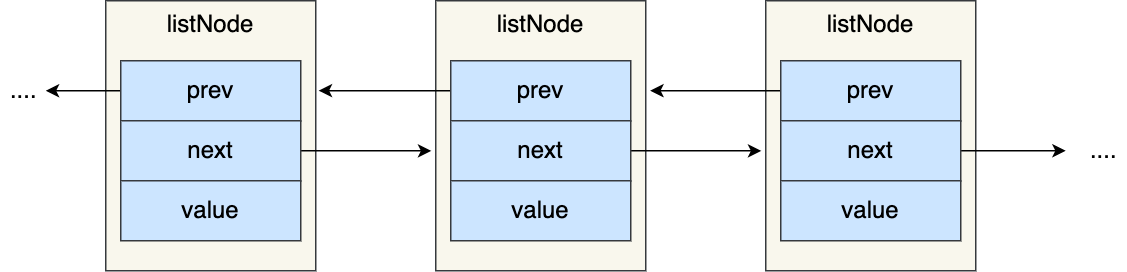
Redis 链表List命令教程和优化策略 介绍 List 列表是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 列表添加元素。列表的最大长度为 2^32 - 1,也即每个列表支持超过 40 亿个元素 内部实现 List 类型的底层数据结构是由双向链表或压缩列表实现的: 如果列表的元素个数小于 512 个(默认值,可由 list-max-ziplist-entries 配置),列表每个元素的值都小于 64 字节(默认值,可由 list-max-ziplist-value 配置),Redis 会使用压缩列表作为 List 类型的底层数据结构; 如果列表的元素不满足上面的条件,Redis 会使用双向链表作为 List 类型的底层数据结构; 但是在 Redis 3.2 版本之后,List 数据类型底层数据结构就只由 quicklist 实现了,替代了双向链表和压缩列表 链表 大家最熟悉的数据结构除了数组之外,我相信就是链表了。 Redis 的 List 对象的底层实现之一就是链表。C 语言本身没有链表这个数据结构的,所以 Redis 自己设计了一个链表数据结构。 链表节点结构设计是什么样呢? 先来看看「链表节点」结构的样子: typedef struct listNode { //前置节点 struct listNode *prev; //后置节点 struct listNode *next; //节点的值 void *value; } listNode; 有前置节点和后置节点,可以看的出,这个是一个双向链表。 那链表结构设计是什么样呢 不过,Redis 在 listNode 结构体基础上又封装了 list 这个数据结构,这样操作起来会更方便,链表结构如下: typedef struct list { //链表头节点 listNode *head; //链表尾节点 listNode *tail; //节点值复制函数 void *(*dup)(void *ptr); //节点值释放函数 void (*free)(void *ptr); //节点值比较函数 int (*match)(void *ptr, void *key); //链表节点数量 unsigned long len; } list; list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。 举个例子,下面是由 list 结构和 3 个 listNode 结构组成的链表。 链表有什么优势和缺陷? Redis 的链表实现优点如下: listNode 链表节点的结构里带有 prev 和 next 指针,获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表; list 结构因为提供了表头指针 head 和表尾节点 tail,所以获取链表的表头节点和表尾节点的时间复杂度只需O(1); list 结构因为提供了链表节点数量 len,所以获取链表中的节点数量的时间复杂度只需O(1); listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值; 链表的缺陷也是有的: 链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存。能很好利用 CPU 缓存的数据结构就是数组,因为数组的内存是连续的,这样就可以充分利用 CPU 缓存来加速访问。 还有一点,保存一个链表节点的值都需要一个链表节点结构头的分配,内存开销较大。 因此,Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。 不过,压缩列表存在性能问题(具体什么问题,下面会说),所以 Redis 在 3.2 版本设计了新的数据结构 quicklist,并将 List 对象的底层数据结构改由 quicklist 实现。 然后在 Redis 5.0 设计了新的数据结构 listpack,沿用了压缩列表紧凑型的内存布局,最终在最新的 Redis 版本,将 Hash 对象和 Zset 对象的底层数据结构实现之一的压缩列表,替换成由 listpack 实现。 压缩列表结构设计 压缩列表是 Redis 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组。 压缩列表在表头有三个字段: zlbytes,记录整个压缩列表占用对内存字节数; zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量; zllen,记录压缩列表包含的节点数量; zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。 在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段(zllen)的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素。 另外,压缩列表节点(entry)的构成如下: 压缩列表节点包含三部分内容: prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历; encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。 data,记录了当前节点的实际数据,类型和长度都由 encoding 决定; 当我们往压缩列表中插入数据时,压缩列表就会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。 分别说下,prevlen 和 encoding 是如何根据数据的大小和类型来进行不同的空间大小分配。 压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如: 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值; 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值; encoding 属性的空间大小跟数据是字符串还是整数,以及字符串的长度有关,如下图(下图中的 content 表示的是实际数据,即本文的 data 字段): 如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码,也就是 encoding 长度为 1 字节。通过 encoding 确认了整数类型,就可以确认整数数据的实际大小了,比如如果 encoding 编码确认了数据是 int16 整数,那么 data 的长度就是 int16 的大小。 如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码,encoding 编码的前两个 bit 表示数据的类型,后续的其他 bit 标识字符串数据的实际长度,即 data 的长度。 连锁更新 压缩列表除了查找复杂度高的问题,还有一个问题。 压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。 前面提到,压缩列表节点的 prevlen 属性会根据前一个节点的长度进行不同的空间大小分配: 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值; 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值; 现在假设一个压缩列表中有多个连续的、长度在 250~253 之间的节点,如下图: 因为这些节点长度值小于 254 字节,所以 prevlen 属性需要用 1 字节的空间来保存这个长度值。 这时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,即新节点将成为 e1 的前置节点,如下图: 因为 e1 节点的 prevlen 属性只有 1 个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作,并将 e1 节点的 prevlen 属性从原来的 1 字节大小扩展为 5 字节大小。 多米诺牌的效应就此开始。 e1 原本的长度在 250~253 之间,因为刚才的扩展空间,此时 e1 的长度就大于等于 254 了,因此原本 e2 保存 e1 的 prevlen 属性也必须从 1 字节扩展至 5 字节大小。 正如扩展 e1 引发了对 e2 扩展一样,扩展 e2 也会引发对 e3 的扩展,而扩展 e3 又会引发对 e4 的扩展.... 一直持续到结尾。 这种在特殊情况下产生的连续多次空间扩展操作就叫做「连锁更新」,就像多米诺牌的效应一样,第一张牌倒下了,推动了第二张牌倒下;第二张牌倒下,又推动了第三张牌倒下...., 压缩列表的缺陷 空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。 所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。 因此,压缩列表只会用于保存的节点数量不多的场景,只要节点数量足够小,即使发生连锁更新,也是能接受的。 虽说如此,Redis 针对压缩列表在设计上的不足,在后来的版本中,新增设计了两种数据结构:quicklist(Redis 3.2 引入) 和 listpack(Redis 5.0 引入)。这两种数据结构的设计目标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题。 quicklist 在 Redis 3.0 之前,List 对象的底层数据结构是双向链表或者压缩列表。然后在 Redis 3.2 的时候,List 对象的底层改由 quicklist 数据结构实现。 其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。 在前面讲压缩列表的时候,我也提到了压缩列表的不足,虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变大了,压缩列表会有「连锁更新」的风险,一旦发生,会造成性能下降。 quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。 quicklist 结构设计 quicklist 的结构体跟链表的结构体类似,都包含了表头和表尾,区别在于 quicklist 的节点是 quicklistNode。 typedef struct quicklist { //quicklist的链表头 quicklistNode *head; //quicklist的链表头 //quicklist的链表尾 quicklistNode *tail; //所有压缩列表中的总元素个数 unsigned long count; //quicklistNodes的个数 unsigned long len; ... } quicklist; 接下来看看,quicklistNode 的结构定义: typedef struct quicklistNode { //前一个quicklistNode struct quicklistNode *prev; //前一个quicklistNode //下一个quicklistNode struct quicklistNode *next; //后一个quicklistNode //quicklistNode指向的压缩列表 unsigned char *zl; //压缩列表的的字节大小 unsigned int sz; //压缩列表的元素个数 unsigned int count : 16; //ziplist中的元素个数 .... } quicklistNode; 可以看到,quicklistNode 结构体里包含了前一个节点和下一个节点指针,这样每个 quicklistNode 形成了一个双向链表。但是链表节点的元素不再是单纯保存元素值,而是保存了一个压缩列表,所以 quicklistNode 结构体里有个指向压缩列表的指针 *zl。 我画了一张图,方便你理解 quicklist 数据结构。 在向 quicklist 添加一个元素的时候,不会像普通的链表那样,直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到 quicklistNode 结构里的压缩列表,如果不能容纳,才会新建一个新的 quicklistNode 结构。 quicklist 会控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来规避潜在的连锁更新的风险,但是这并没有完全解决连锁更新的问题。 常用命令 左边是队首,右边是队尾: # 将一个或多个值value插入到key列表的表头(最左边),最后的值在最前面 LPUSH key value [value ...] # 将一个或多个值value插入到key列表的表尾(最右边) RPUSH key value [value ...] # 移除并返回key列表的头元素 LPOP key # 移除并返回key列表的尾元素 RPOP key # 返回列表key中指定区间内的元素,区间以偏移量start和stop指定,从0开始 LRANGE key start stop # 从key列表表头弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞 # B是block阻塞的意思 BLPOP key [key ...] timeout # 从key列表表尾弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞 BRPOP key [key ...] timeout 应用场景 常用来存储一个有序数据,例如:朋友圈点赞列表列表等不需要分页的有序列表。 消息队列 消息队列在存取消息时,必须要满足三个需求,分别是 消息保序 、 处理重复的消息 和 保证消息可靠性 。 Redis 的 List 和 Stream 两种数据类型,就可以满足消息队列的这三个需求。我们先来了解下基于 List 的消息队列实现方法,后面在介绍 Stream 数据类型时候,在详细说说 Stream。 1、如何满足消息保序需求? List 本身就是按先进先出的顺序对数据进行存取的,所以,如果使用 List 作为消息队列保存消息的话,就已经能满足消息保序的需求了。使用lpush和rpop就可以了。 不过,在消费者读取数据时,有一个潜在的性能问题!! 在生产者往 List 中写入数据时,List 并不会主动地通知消费者有新消息写入,如果消费者想要及时处理消息,就需要在程序中不停地调用 RPOP 命令(比如使用一个while(1)循环)。如果有新消息写入,RPOP命令就会返回结果,否则,RPOP命令返回空值,再继续循环。所以,即使没有新消息写入List,消费者也要不停地调用 RPOP 命令,这就会导致消费者程序的 CPU 一直消耗在执行 RPOP 命令上,带来不必要的性能损失。 为了解决这个问题,Redis提供了 BRPOP 命令。BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。和消费者程序自己不停地调用RPOP命令相比,这种方式能节省CPU开销。 2、如何处理重复的消息? 消费者要实现重复消息的判断,需要 2 个方面的要求: 每个消息都有一个全局的 ID 消费者要记录已经处理过的消息的 ID。当收到一条消息后,消费者程序就可以对比收到的消息 ID 和记录的已处理过的消息 ID,来判断当前收到的消息有没有经过处理。如果已经处理过,那么,消费者程序就不再进行处理了。 但是 List 并不会为每个消息生成 ID 号,所以我们需要自行为每个消息生成一个全局唯一ID,生成之后,我们在用 LPUSH 命令把消息插入 List 时,需要在消息中包含这个全局唯一 ID。 例如,我们执行以下命令,就把一条全局 ID 为 111000102、库存量为 99 的消息插入了消息队列: > LPUSH mq "111000102:stock:99" (integer) 1 3、如何保证消息可靠性? 当消费者程序从 List 中读取一条消息后,List 就不会再留存这条消息了。所以,如果消费者程序在处理消息的过程出现了故障或宕机,就会导致消息没有处理完成,那么,消费者程序再次启动后,就没法再次从 List 中读取消息了。 为了留存消息,List 类型提供了 BRPOPLPUSH 命令,这个命令的作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存。 这样一来,如果消费者程序读了消息但没能正常处理,等它重启后,就可以从备份 List 中重新读取消息并进行处理了。 总结: 好了,到这里可以知道基于 List 类型的消息队列,满足消息队列的三大需求(消息保序、处理重复的消息和保证消息可靠性)。 消息保序:使用 LPUSH + RPOP; 阻塞读取:使用 BRPOP; 重复消息处理:生产者自行实现全局唯一 ID; 消息的可靠性:使用 BRPOPLPUSH List 作为消息队列有什么缺陷? List 不支持多个消费者消费同一条消息,因为一旦消费者拉取一条消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费。 要实现一条消息可以被多个消费者消费,那么就要将多个消费者组成一个消费组,使得多个消费者可以消费同一条消息,但是 List 类型并不支持消费组的实现。 这就要说起 Redis 从 5.0 版本开始提供的 Stream 数据类型了,Stream 同样能够满足消息队列的三大需求,而且它还支持「消费组」形式的消息读取。
-
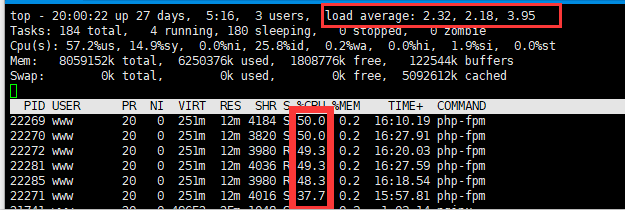
顶级指南:深度理解和使用Linux top命令 查看平均负载 load average 从下图面可以看出,6个php-fpm进程占用的cpu空间都很高,平均负载(load average)情况如下: 1分钟平均负载:2.32; 5分钟平均负载:2.18; 15分钟平均负载:3.95; 可以说它现在的平均负载接近了它的cpu总核数:4;需要考虑服务器配置升级! task TASK几个参数代表的意思是: 184 total :184个总进程数 4 running:4个正在运行的进程数 143 sleeping:180个睡眠的进程数 0 stoppe:0个停止的进程数 0 zombie:0个冻结进程数 cpu(s) CPU(s),上次更新到现在的CPU时间占用百分比 %Cpu(s): 0.4 us, 0.2 sy, 0.0 ni, 99.2 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st 0.4us 是用户空间占用CPU百分比 0.2sy 是系统空间占用CPU百分比 默认情况下是多个cpu的平均值,如果想要看各个cpu的分别占用多少,可以按1 有时候会发现CPU(s)使用率才15.5%,而某个进程%CPU 达到了278%,也就是说进程的cpu占用超过了百分百 这是因为该进程启用了多线程占用了多个核心,所以有时候我们看该值得时候会超过100%,但不会超过总核数*100 相关的命令 输入top命令之后: M:按照内存使用率进行排序。 按下小写的m,切换头部内存显示方式,可以是数值显示,也可以是进度条占比显示 按下小写的e,进程列表的内存将切换单位显示 按下大写的E,切换头部的内存单位显示 按下1,按cpu展开显示 P:按照CPU使用率(%CPU)进行排序。 N:按照进程ID进行排序。 T:按照运行时间进行排序。 按照特定字段进行排序 如果你想按照特定的字段进行排序,可以使用Top命令的命令行参数来指定排序方式。以下是一些常用的命令行参数: top -o %CPU:按照CPU使用率进行排序。 top -o %MEM:按照内存使用率进行排序。 top -o PID:按照进程ID进行排序。 top -o TIME+:按照运行时间进行排序。 使用这些命令行参数,你可以在运行Top命令时直接指定排序方式,而无需在交互界面中手动操作。 退出 Top 命令 当你完成对CPU使用率的检查和排序后,可以通过按下键盘上的q键来退出Top命令。
-
Linux中的ps查看进程命令详解 | Linux管理员必备 常用的用法 # 显示所有进程信息,连同命令行,不会显示内存 ps -ef # 列出目前所有的正在内存当中的程序,会显示内存大小kb,cpu占用百分比,内存占用百分比 ps -aux ps -aux --sort:rss # 按内存升序排序,rss是一个列的字段 ps -aux --sort:-rss # 按内存降序排序 ps -aux --sort:-%CPU # 按cpu百分比降序 # 列出类似程序树的程序显示,可以清晰的看出父子进程 ps -axjf # 查看php-fpm的内存,C代表过滤php-fpm进程,l类似ls命令,C必须和l参数共用 # y代表输出rss列,如果没有这个参数,则是输出ADDR列 ps -ylC php-fpm --sort:rss 输出结果字段的有意思 F 代表这个程序的旗标 (flag), 4 代表使用者为 super user S 代表这个程序的状态 (STAT),关于各 STAT 的意义将在内文介绍 UID 程序被该 UID 所拥有 PID 就是这个程序的 ID ! PPID 则是其上级父程序的ID C CPU 使用的资源百分比 PRI 这个是 Priority (优先执行序) 的缩写,详细后面介绍 NI 这个是 Nice 值,在下一小节我们会持续介绍 ADDR 这个是 kernel function,指出该程序在内存的那个部分。如果是个 running的程序,一般就是 "-" SZ 使用掉的内存大小 WCHAN 目前这个程序是否正在运作当中,若为 - 表示正在运作 TTY 登入者的终端机位置 TIME 使用掉的 CPU 时间。 CMD 所下达的指令为何在预设的情况下, ps 仅会列出与目前所在的 bash shell 有关的 PID 而已,所以, 当我使用 ps -l 的时候,只有三个 PID。 USER:该 process 属于那个使用者账号的 PID :该 process 的号码 %CPU:该 process 使用掉的 CPU 资源百分比 %MEM:该 process 所占用的物理内存百分比 VSZ :该 process 使用掉的虚拟内存量 (Kbytes) RSS :该 process 占用的固定的内存量 (Kbytes) TTY :该 process 是在那个终端机上面运作,若与终端机无关,则显示 ?,另外, tty1-tty6 是本机上面的登入者程序,若为 pts/0 等等的,则表示为由网络连接进主机的程序。 STAT:该程序目前的状态,主要的状态有 R :该程序目前正在运作,或者是可被运作 S :该程序目前正在睡眠当中 (可说是 idle 状态),但可被某些讯号 (signal) 唤醒。 T :该程序目前正在侦测或者是停止了 Z :该程序应该已经终止,但是其父程序却无法正常的终止他,造成 zombie (疆尸) 程序的状态 START:该 process 被触发启动的时间 TIME :该 process 实际使用 CPU 运作的时间 COMMAND:该程序的实际指令
-
PHP-FPM 进程管理器专家 - 了解更多 概述 FPM(FastCGI Process Manager)是PHP FastCGI运行模式的一个进程管理器,从它的定义可以看出,FPM的核心功能是进程管理。 FastCGI是Web服务器(如:Nginx、Apache)和处理程序之间的一种通信协议,它是与Http类似的一种应用层通信协议,注意:它只是一种协议! 首先,PHP只是一个脚本解析器,没有实现http协议,只有实现了FastCGI协议。所以为了能接收http请求,就需要第三方实现http协议的软件,例如nginx。工作原理如下: nginx接收http请求,然后通过fastcgi协议发送给php,php解析请求,结果通过fastcgi协议返回给nginx,然后nginx将响应结果通过http协议返回给客户端。 基本实现 fpm的实现就是创建一个master进程,在master进程中创建并监听socket,然后fork出多个子进程,这些子进程各自accept请求。 子进程的处理非常简单,它在启动后阻塞在accept上(通过这些kqueue、epoll、poll、select技术来监听),有请求到达后开始读取请求数据,读取完成后开始处理然后再返回,在这期间是不会接收其它请求的,也就是说fpm的子进程同时只能响应一个请求,只有把这个请求处理完成后才会accept下一个请求。 fpm的master进程与worker进程之间不会直接进行通信,master通过共享内存获取worker进程的信息,比如worker进程当前状态、已处理请求数等,当master进程要杀掉一个worker进程时则通过发送信号的方式通知worker进程。 配置 子进程监听多个端口 fpm可以同时监听多个端口,每个端口对应一个worker pool,而每个pool下对应多个worker进程,类似nginx中server概念。在php-fpm.conf中通过[pool name]声明一个worker pool [web1] listen = 127.0.0.1:9000 ... [web2] listen = 127.0.0.1:9001 ... fpm子进程数量配置 pm有三个值,分别代表3种进程管理方式: dynamic 表示php-fpm进程数是动态的,如果请求较多,则会自动增加,内存小的建议用这个。 动态进程管理,首先在fpm启动时按照pm.start_servers初始化一定数量的worker,运行期间如果master发现空闲worker数低于pm.min_spare_servers配置数(表示请求比较多,worker处理不过来了)则会fork worker进程,但总的worker数不能超过pm.max_children,如果master发现空闲worker数超过了pm.max_spare_servers(表示闲着的worker太多了)则会杀掉一些worker(通过定时器实现,一定时间后触发某个事件),避免占用过多资源,master通过这4个值来控制worker数。 pm.start_servers = 8 #dynamic模式下开机的进程数量。 pm.max_children = 15 #最大的数量 pm.min_spare_servers = 6 #dynamic模式下最小php-fpm进程数量。 pm.max_spare_servers = 15 #dynamic模式下最大php-fpm进程数量。 static 表示php-fpm的进程数自始至终都是pm.max_children指定的数量,不再增加或减少,这个值原则上是越大越好,php-cgi的进程多了就会处理的很快,排队的请求就会很少,不过也需要根据服务器的性能来配置,正常情况下,一个php-fpm进程内存在30M左右,不过也不好说,最好留给60%的内存给php-fpm进程就好了。内存大的建议用这个。 这种方式比较简单,在启动时master按照pm.max_children配置fork出相应数量的worker进程,即worker进程数是固定不变的 pm.max_children = 15 #static模式下生效,dynamic不生效。 ondemand 每个闲置进程在持续闲置了pm.process_idle_timeout秒后就会被杀掉,如果服务器长时间没有请求,就只会有一个php-fpm主进程。适用于微小内存,例如512MB或者256MB内存,以及对可用性要求不高的环境。 这种方式一般很少用,在启动时不分配worker进程,等到有请求了后再通知master进程fork worker进程,总的worker数不超过pm.max_children,处理完成后worker进程不会立即退出,当空闲时间超过pm.process_idle_timeout后再退出 pm.process_idle_timeout = 900 # 900s之后不管是否执行完成,直接杀死进程,这个要注意 最大连接时长 pm.request_terminate_timeout 表示将执行时间太长的进程直接终止的时间,单位是秒。如果是设置为0表示不超时,一直保持连接,直到返回结果。可以设置个15分钟,也就是900秒。 慢日志配置 request_slowlog_timeout 这参数设置多长时间开始记录日志,一般设置为:request_slowlog_timeout = 10s slowlog 这个参数用于配置慢日志文件记录的位置。slowlog = log/$pool.log.slow,log是相对路径。 打开的最大的文件数量 rlimit_files 配置php-fpm可以打开的最大的文件数量,默认1024,此值可以不需要配置,rlimit_files = 1024。 缺点 假设我们使用 Nginx 提供 HTTP 服务(Apache 同理),所有客户端发起的请求最先抵达的都是 Nginx,然后 Nginx 通过 FastCGI 协议将请求转发给 PHP-FPM 处理,PHP-FPM 的 Worker 进程 会 抢占式 的获得 CGI 请求进行处理,这个处理指的就是,等待 PHP 脚本的解析,等待业务处理的结果返回,完成后回收子进程,这整个的过程是 阻塞等待 的,也就意味着 PHP-FPM 的进程数有多少能处理的请求也就是多少,假设 PHP-FPM 有 200 个 Worker 进程,一个请求将耗费 1 秒的时间,那么简单的来说整个服务器理论上最多可以处理的请求也就是 200 个,QPS 即为 200/s,在高并发的场景下,这样的性能往往是不够的,尽管可以利用 Nginx 作为负载均衡配合多台 PHP-FPM 服务器来提供服务,但由于 PHP-FPM 的阻塞等待的工作模型,一个请求会占用至少一个 MySQL 连接,多节点高并发下会产生大量的 MySQL 连接,而 MySQL 的最大连接数默认值为 100,尽管可以修改,但显而易见该模式没法很好的应对高并发的场景。 参考 https://github.com/pangudashu/php7-internal/blob/master/1/fpm.md
-
Go依赖管理 - 解决方案和优化技术 概述 go 的依赖查找和其它语言一样,都是 绝对路径(当前项目目录、vendor目录、gopath、goroot)+ 相对路径(import 关键词后的路径) 进行查找的方式。 查找规则大致如下: 从当前项目目录开查找依赖包 从 vendor 目录开查找依赖包 (项目目录必须在 src 目录下) 从 gopath/pkg/mod 目录查找依赖包(GO111MODULE=on 或者 auto,并且项目目录有 go.mod 文件,项目目录可以在任意位置) 再从 gopath 目录查找依赖包(必须在项目目录必须在 src 下,并且项目目录下不能有 go·mod 文件) 最后从 goroot 目录查找依赖包 goPath 模式 该模式下,项目文件必须放在 gopath/src 目录下,并且项目目录下不能有 go·mod 文件,通常会有三个目录: ./bin 存放编译后的二进制 ./pkg 存放编译后的库文件 ./src 源码文件 └── go_code 因为go get 也会下载到这个目录,所以最好另外启一个目录用于存放自己的代码 ├── project1 │ └── main.go └── project2 缺点是: go get 命令 会下载的所有依赖都会放在 src 目录下。这就会导致只能安装最新版本(如果在老项目中执行这个命令,可能会导致依赖不兼容,无法实现多版本管理) 源代码必须放在 src 下。这就会导致,依赖和源码放在一个目录,很混乱 vendoring 模式 只要版本大于 v1.5,项目目录必须在 src 目录下,就会去 vendor 目录下找。首先会在当前包下的 vendor 目录查找,如果找不到再向上级目录的 vendor 目录下查找,直到找到 src 下的 vendor 目录,如果还是找不到再从 GOPATH 目录找,如果还是找不到,最后从 goroot 目录查找。 通常目录结构如下所示,会有 vendor 目录: ./bin 存放编译后的二进制 ./pkg 存放编译后的库文件 ./src 源码文件 └── go_code ├── project1 │ └── main.go │ └── vendor 第三方包的目录 └── project2 ./vendor 第三方包的目录 优缺点: 通过复制一份依赖到 vendor 目录来实现项目的多版本 由于 vendor 目录需要加入版本控制,导致仓库会很大 源码可以不放在 src 目录下 这期间出现了多种 vendor 依赖包管理工具,都是非官方的: Godep:解决包依赖的管理工具,Docker、Kubernetes、CoreOS 等 Go 项目都曾用过 godep 来管理其依赖。 Govendor:它的功能比 Godep 多一些,通过 vendor 目录下的 vendor. json 文件来记录依赖包的版本。 Glide:相对完善的包管理工具,通过 glide. yaml 记录依赖信息,通过 glide. lock 追踪每个包的具体修改。 GoModule 模式 当 GO111MODULE=on 或者 auto,并且项目目录有 go.mod 文件,这个时候会去 gopath/pkg 目录下查找依赖包。 GO111MODULE 有三个值: auto:在 $GOPATH/src 下,且没有包含 go.mod时则关闭 Go Modules,其他情况下都开启 Go Modules。 on:启用 Go Modules off:关闭 Go Modules,不推荐。 可以使用以下命令修改 go env -w GO111MODULE=on go mod 文件 go.mod 文件用于声明一个模块,并且指明该模块下所依赖的包,可以使用以下命令生成 # 如果在gopath/src目录下,可以省略包名称,会自动生成 go mod init # 如果不是在gopath/src目录下的话,需要带有包的名称 go mod init github.com/wuqiyin/helloWorld mod 文件的大致内容如下所示 module github.com/silver/moduleTest // 用来定义当前项目的模块路径 go 1.17 // 用来设置预期的 Go 版本,目前只是起标识作用。 所以 没有约束、检查 等实际作用。 // 用来设置一个特定的模块版本,格式为<导入包路径> <版本> [// indirect]。 // indirect 代表是间接依赖的意思,如果没有 indirect 的话则是直接依赖包 require github.com/aceld/zinx v1.0.0 // indirect // 代表的是如果下载zinx v1.0.0包的话,就替换成zinx v1.0.1包 // 可以使用命令:`go mod edit --replace=zinx@v1.0.0=zinx@v1.0.1` 生成 // 要替换的包可以事先下载到pkg目录下 // 这个时候,虽然代码的包就会依赖新的版本 replace zinx v1.0.0 => zinx v1.0.1 // 用来从使用中排除一个特定的模块版本,如果我们知道模块的某个版本有严重的问题,就可以使用 exclude 将该版本排除掉。 exclude ( github.com/google/uuid v1.1.0 ) 如果需要修改,可以直接编辑 mod 文件,不过还是建议使用 go mod edit 命令 go mod edit -fmt # go.mod 格式化 go mod edit -require="golang.org/x/text@v0.3.3" # 添加一个依赖 go mod edit -droprequire="golang.org/x/text" # require的反向操作,移除一个依赖 go mod edit -replace="github.com/gin-gonic/gin=/home/colin/gin" # 替换模块版本 go mod edit -dropreplace="github.com/gin-gonic/gin" # replace的反向操作 go mod edit -exclude="golang.org/x/text@v0.3.1" # 排除一个特定的模块版本 go mod edit -dropexclude="golang.org/x/text@v0.3.1" # exclude的反向操作 需要注意的是,当在项目中执行 go get ... 命令的时候,会自动往 mod 文件写入 require 内容。 随着项目的依赖文件的增多,可能很多依赖是冗余的,这个时候需要整理依赖,可以使用以下命令: go mod tidy 其他相关命令 # 获取所有的指令 go mod help # 初始化项目。项目名称,一般是和包名称是一样的 go mod init 项目名称 # 添加丢失的模块,并移除无用的模块 # 默认情况下,Go 不会移除 go.mod 文件中的无用依赖。当依赖包不再使用了,可以使用go mod tidy命令来清除它 # go 在运行的时候,好像会自动下载依赖,并不一定要执行这个来下载到本地 go mod tidy # 下载 go.mod 文件中记录的所有依赖包。而go get是下载单个包。go get暂时还不支持拉取指定分支的指定commit id # 下载到$GOPATH/pkg/mod目录) go mod download # 编辑go.mod文件 go mod edit # 将所有依赖包存到当前目录下的 vendor 目录下。 go mod vendor # 检查当前模块的依赖是否已经存储在本地下载的源代码缓存中,以及检查下载后是否有修改 go mod verify # 查看为什么需要依赖某模块。 go mod why # 查看现有的依赖结构。 go mod graph go sum 文件 go.sum 文件主要为了保证一致性,避免包是被篡改过的,构建的时候,会比较 hash 值,大致内容: # 第一种h1哈希,代表的是对zinx包的所有文件进行hash # 如果没有哈希值,可能代表包用不上 github.com/aceld/zinx v1.0.0 h1:w1rfb84AsiR/5NRKL8HDBpOB3nJwzwzZyouUjS825q0= # 第二种.mod h1哈希,代表的是只对对mod文件进行hash github.com/aceld/zinx v1.0.0/go.mod h1:bMiERrPdR8FzpBOo86nhWWmeHJ1cCaqVvWKCGcDVJ5M= 包和依赖的关系 在使用之前,我们先了解下包和模块的关系,他们像是集合和元素的关系: Go 包是:同一目录中一起编译的 Go 源文件的集合。在一个源文件中定义的函数、类型、变量和常量,对于同一包中的所有其他源文件可见。 模块是:存储在文件树中的 Go 包的集合,并且文件树根目录有 go. mod 文件。go. mod 文件定义了模块的名称及其依赖包,每个依赖包都需要指定导入路径和语义化版本(Semantic Versioning),通过导入路径和语义化版本准确地描述一个依赖。
-
解决php foreach值引用问题 - 为什么php foreach值引用导致值不正确 示例一 使用引用,可以方便快速的修改数组元素,但是,当 foreach 的元素变量名称一样的时候,例如下例变量名称都是引用类型的话,将引发一些问题。 $array1 = [1, 2, 3]; // 执行完这个语句后,$value始终指向$array[2]这个元素 foreach ($array1 as &$value) {} // $array = [1,2,3] $array2 = $array1;// 就连$value的引用也复制了过来,详细见示例二 foreach ($array2 as $value) {//array1和array2的第3个元素都会被修改 // 第1次循环之后$array=[1,2,1] // 第2次循环之后$array=[1,2,2],此时数组的第三个元素变成了倒数第二个元素,然后作为下一次循环 // 第3次循环之后$array=[1,2,2] } var_dump($array1);// [1,2,2] var_dump($array2);// [1,2,2] 所以针对这个问题,同一个作用域里,foreach的变量不能一样。 示例二 如果先对数组元素进行引用,然后再赋值给另外一个变量,那么两个数组的的这个元素,再内存中是共用一块地址的,对引用变量的修改,会影响到多个数组 $array1 = [1, 2, 3]; $value = &$array1[2]; $array2 = $array1; $value = 33; print_r($array1); // [1,2,33] print_r($array2);// [1,2,33] 如果先复制然后在引用,就不会有这个问题,也就是说,数组复制的时候,要注意数组的元素有没被引用 $array1 = [1, 2, 3]; $array2 = $array1; $value = &$array1[2]; $value = 33; print_r($array1); // [1,2,33] print_r($array2);// [1,2,3] 示例三 如下代码 $arr = array('a1', 'a2', 'a3'); foreach ($arr as $key => $value) { // $value是$arr[$key]的引用,修改$value的值会修改$arr[$key]的值 $value = &$arr[$key]; print_r($arr); } print_r($arr); 输出结果是 Array ( [0] => a1 [1] => a2 [2] => a3 ) Array ( [0] => a2 [1] => a2 [2] => a3 ) Array ( [0] => a2 [1] => a3 [2] => a3 ) Array ( [0] => a2 [1] => a3 [2] => a3 ) 如果不想受到影响,可以在$value上加个&,这样每次foreach的时候,会断开原来的引用,重新对新的数组元素进行引用 $arr = array('a1', 'a2', 'a3'); foreach ($arr as $key => &$value) { // $value是$arr[$key]的引用,修改$value的值会修改$arr[$key]的值 $value = &$arr[$key]; print_r($arr); } print_r($arr);