搜索到
62
篇与
的结果
-
 Sonic - 高性能JSON库 介绍 我们在日常开发中,常常会对JSON进行序列化和反序列化。Golang提供了encoding/json包对JSON进行Marshal/Unmarshal操作。但是在大规模数据场景下,该包的性能和开销确实会有点不够看。在生产环境下,JSON 序列化和反序列化会被频繁的使用到。在测试中,CPU使用率接近 10%,其中极端情况下超过 40%。因此,JSON 库的性能是提高机器利用率的关键问题。 Sonic是一款由字节跳动开发的一个全新的高性能、适用广泛的 JSON 库。在设计上借鉴了多款JSON库,同时为了实现对标准库的真正插拔式替换,Sonic使用了 JIT** (即时编译)**。 Sonic的特色 我们可以看出:Sonic是一个主打快的JSON库。 运行时对象绑定,无需代码生成 完备的 JSON 操作 API 快,更快,还要更快! Sonic的设计 针对编解码动态汇编的函数调用开销,使用 JIT 技术在运行时组装与模式对应的字节码(汇编指令),最终将其以 Golang 函数的形式缓存在堆外内存上。 针对大数据和小数据共存的实际场景,使用预处理判断(字符串大小、浮点数精度等)将 SIMD 与标量指令相结合,从而实现对实际情况的最佳适应。 对于 Golang 语言编译优化的不足,使用 C/Clang 编写和编译核心计算函数,并且开发了一套 asm2asm 工具,将经过充分优化的 x86 汇编代码转换为 Plan9 格式,最终加载到 Golang 运行时中。 考虑到解析和跳过解析之间的速度差异很大, 惰性加载机制当然也在 AST 解析器中使用了,但以一种更具适应性和高效性的方式来降低多键查询的开销。 在细节上,Sonic进行了一些进一步的优化: 由于 Golang 中的原生汇编函数不能被内联,发现其成本甚至超过了 C 编译器的优化所带来的改善。所以在 JIT 中重新实现了一组轻量级的函数调用: 全局函数表+静态偏移量,用于调用指令 使用寄存器传递参数 Sync.Map 一开始被用来缓存编解码器,但是对于准静态(读远多于写),元素较少(通常不足几十个)的场景,它的性能并不理想,所以使用开放寻址哈希和 RCU 技术重新实现了一个高性能且并发安全的缓存。 详细设计文档可查阅introduction 安装使用 当前我使用的go version是1.21。 官方建议的版本: Go 1.16~1.21 Linux / MacOS / Windows(需要 Go1.17 以上) Amd64 架构 # 下载sonic依赖 $ go get github.com/bytedance/sonic 基本使用 sonic提供了许多功能。本文仅列举其中较为有特色的功能。感兴趣的同学可以去看一下官方的examples 序列化/反序列化 sonic的使用类似于标准包encoding/json包的使用. func base() { m := map[string]interface{}{ "name": "z3", "age": 20, } // sonic序列化 byt, err := sonic.Marshal(&m) if err != nil { log.Println(err) } fmt.Printf("json: %+v\n", string(byt)) // sonic反序列化 um := make(map[string]interface{}) err = sonic.Unmarshal(byt, &um) if err != nil { log.Println(err) } fmt.Printf("unjson: %+v\n", um) } // print // json: {"name":"z3","age":20} // unjson: map[age:20 name:z3] sonic还支持流式的输入输出 Sonic 支持解码 io.Reader 中输入的 json,或将对象编码为 json 后输出至 io.Writer,以处理多个值并减少内存消耗 func base() { m := map[string]interface{}{ "name": "z3", "age": 20, } // 流式io编解码 // 编码 var encbuf bytes.Buffer enc := sonic.ConfigDefault.NewEncoder(&encbuf) if err := enc.Encode(m); err != nil { log.Fatal(err) } else { fmt.Printf("cutomize encoder: %+v", encbuf.String()) } // 解码 var decbuf bytes.Buffer decbuf.WriteString(encbuf.String()) clear(m) dec := sonic.ConfigDefault.NewDecoder(&decbuf) if err := dec.Decode(&m); err != nil { log.Fatal(err) } else { fmt.Printf("cutomize decoder: %+v\n", m) } } // print // cutomize encoder: {"name":"z3","age":20} // cutomize decoder: map[age:20 name:z3] 配置 在上面的自定义流式编码解码器,细心的朋友可能看到我们创建编码器和解码器的时候,是通过sonic.ConfigDefault.NewEncoder() / sonic.ConfigDefault.NewDecoder()这两个函数进行调用的。那么sonic.ConfigDefault是什么? 我们可以通过查看源码: var ( // ConfigDefault is the default config of APIs, aiming at efficiency and safty. // ConfigDefault api的默认配置,针对效率和安全。 ConfigDefault = Config{}.Froze() // ConfigStd is the standard config of APIs, aiming at being compatible with encoding/json. // ConfigStd是api的标准配置,旨在与encoding/json兼容。 ConfigStd = Config{ EscapeHTML : true, SortMapKeys: true, CompactMarshaler: true, CopyString : true, ValidateString : true, }.Froze() // ConfigFastest is the fastest config of APIs, aiming at speed. // ConfigFastest是api的最快配置,旨在提高速度。 ConfigFastest = Config{ NoQuoteTextMarshaler: true, }.Froze() ) sonic提供了三种常用的Config配置。这些配置中对一些场景已经预定义好了对应的Config。 其实我们使用的sonic.Marshal()函数就是调用了默认的ConfigDefault // Marshal returns the JSON encoding bytes of v. func Marshal(val interface{}) ([]byte, error) { return ConfigDefault.Marshal(val) } // Unmarshal parses the JSON-encoded data and stores the result in the value pointed to by v. // NOTICE: This API copies given buffer by default, // if you want to pass JSON more efficiently, use UnmarshalString instead. func Unmarshal(buf []byte, val interface{}) error { return ConfigDefault.Unmarshal(buf, val) } 但是在一些场景下我们不满足于sonic预定义的三个Config。此时我们可以定义自己的Config进行个性化的编码和解码。 首先先看一下Config的结构。 // Config is a combination of sonic/encoder.Options and sonic/decoder.Options type Config struct { // EscapeHTML indicates encoder to escape all HTML characters // after serializing into JSON (see https://pkg.go.dev/encoding/json#HTMLEscape). // WARNING: This hurts performance A LOT, USE WITH CARE. EscapeHTML bool // SortMapKeys indicates encoder that the keys of a map needs to be sorted // before serializing into JSON. // WARNING: This hurts performance A LOT, USE WITH CARE. SortMapKeys bool // CompactMarshaler indicates encoder that the output JSON from json.Marshaler // is always compact and needs no validation CompactMarshaler bool // NoQuoteTextMarshaler indicates encoder that the output text from encoding.TextMarshaler // is always escaped string and needs no quoting NoQuoteTextMarshaler bool // NoNullSliceOrMap indicates encoder that all empty Array or Object are encoded as '[]' or '{}', // instead of 'null' NoNullSliceOrMap bool // UseInt64 indicates decoder to unmarshal an integer into an interface{} as an // int64 instead of as a float64. UseInt64 bool // UseNumber indicates decoder to unmarshal a number into an interface{} as a // json.Number instead of as a float64. UseNumber bool // UseUnicodeErrors indicates decoder to return an error when encounter invalid // UTF-8 escape sequences. UseUnicodeErrors bool // DisallowUnknownFields indicates decoder to return an error when the destination // is a struct and the input contains object keys which do not match any // non-ignored, exported fields in the destination. DisallowUnknownFields bool // CopyString indicates decoder to decode string values by copying instead of referring. CopyString bool // ValidateString indicates decoder and encoder to valid string values: decoder will return errors // when unescaped control chars(\u0000-\u001f) in the string value of JSON. ValidateString bool } 由于字段较多。笔者就选择几个字段进行演示,其他字段使用方式都是一致。 假设我们希望对JSON序列化按照key进行排序以及将JSON编码成紧凑的格式。我们可以配置Config进行Marshal操作 func base() { snc := sonic.Config{ CompactMarshaler: true, SortMapKeys: true, }.Froze() snc.Marshal(obj) } 考虑到排序带来的性能损失(约 10% ), sonic 默认不会启用这个功能。 Sonic 默认将基本类型( struct , map 等)编码为紧凑格式的 JSON ,除非使用 json.RawMessage or json.Marshaler 进行编码: sonic 确保输出的 JSON 合法,但出于性能考虑,不会加工成紧凑格式。我们提供选项 encoder.CompactMarshaler 来添加此过程, Ast.Node sonic提供了Ast.Node的功能。Sonic/ast.Node 是完全独立的 JSON 抽象语法树库。它实现了序列化和反序列化,并提供了获取和修改通用数据的鲁棒的 API。 先来简单介绍一下Ast.Node:ast.Node 通常指的是编程语言中的抽象语法树(Abstract Syntax Tree)节点。抽象语法树是编程语言代码在编译器中的内部表示,它以树状结构展现代码的语法结构,便于编译器进行语法分析、语义分析、优化等操作。 在很多编程语言的编译器或解释器实现中,抽象语法树中的每个元素(节点)都会有对应的数据结构表示,通常这些数据结构会被称为 ast.Node 或类似的名字。每个 ast.Node 表示源代码中的一个语法结构,如表达式、语句、函数声明等。 抽象语法树的节点可以包含以下信息: 节点的类型:例如表达式、语句、函数调用等。 节点的内容:节点所代表的源代码的内容。 子节点:一些节点可能包含子节点,这些子节点也是抽象语法树的节点,用于构建更复杂的语法结构。 属性:一些节点可能会包含附加的属性,如变量名、操作符类型等。 我们通过几个案例理解一下Ast.Node的使用。 准备数据 data := `{"name": "z3","info":{"num": [11,22,33]}}` 将数据转换为Ast.Node 通过传入bytes或者string返回一个Ast.Node。其中你可以指定path获取JSON中的子路径元素。 每个路径参数必须是整数或者字符串 整数是目标索引(>=0),表示以数组形式搜索当前节点。 字符串为目标key,表示搜索当前节点为对象。 // 函数签名: func Get(src []byte, path ...interface{}) (ast.Node, error) { return GetFromString(string(src), path...) } // GetFromString与Get相同,只是src是字符串,这样可以减少不必要的内存拷贝。 func GetFromString(src string, path ...interface{}) (ast.Node, error) { return ast.NewSearcher(src).GetByPath(path...) } 获取当前节点的完整数据 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // no path return all json string root, err := sonic.GetFromString(data) if err != nil { log.Panic(err) } if raw, err := root.Raw(); err != nil { log.Panic(err) } else { log.Println(raw) } } // print // 2023/08/26 17:15:52 {"name": "z3","info":{"num": [11,22,33]}} 根据path或者索引获取数据 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // no path return all json string root, err := sonic.GetFromString(data) if err != nil { log.Panic(err) } // according to path(根据key,查询当前node下的元素) if path, err := root.GetByPath("name").Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // indexOrget (同时提供index和key进行索引和key的匹配) if path, err := root.IndexOrGet(1, "info").Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // index (按照index进行查找当前node下的元素) // root.Index(1).Index(0).Raw()意味着 // root.Index(1) == "info" // root.Index(1).Index(0) == "num" // root.Index(1).Index(0).Raw() == "[11,22,33]" if path, err := root.Index(1).Index(0).Raw(); err != nil { log.Panic(err) } else { log.Println(path) } } // print // 2023/08/26 17:17:49 "z3" // 2023/08/26 17:17:49 {"num": [11,22,33]} // 2023/08/26 17:17:49 [11,22,33] Ast.Node支持链式调用。故我们可以从root node节点,根据path路径向下搜索指定的元素。 index和key混用 user := root.GetByPath("statuses", 3, "user") // === root.Get("status").Index(3).Get("user") 根据path进行修改数据 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // no path return all json string root, err := sonic.GetFromString(data) if err != nil { log.Panic(err) } // according to path if path, err := root.GetByPath("name").Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // indexOrget (同时提供index和key进行索引和key的匹配) if path, err := root.IndexOrGet(1, "info").Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // index if path, err := root.Index(1).Index(0).Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // set // ast提供了很多go类型转换node的函数 if _, err := root.Index(1).SetByIndex(0, ast.NewArray([]ast.Node{ ast.NewNumber("101"), ast.NewNumber("202"), })); err != nil { log.Panic(err) } raw, _ := root.Raw() log.Println(raw) } // print // 2023/08/26 17:23:55 "z3" // 2023/08/26 17:23:55 {"num": [11,22,33]} // 2023/08/26 17:23:55 [11,22,33] // 2023/08/26 17:23:55 {"name":"z3","info":{"num":[101,202]}} 序列化 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // no path return all json string root, err := sonic.GetFromString(data) if err != nil { log.Panic(err) } bts, _ := root.MarshalJSON() log.Println("Ast.Node(Marshal): ", string(bts)) btes, _ := json.Marshal(&root) log.Println("encoding/json (Marshal): ", string(btes)) } // print // 2023/08/26 17:39:06 Ast.Node(Marshal): {"name": "z3","info":{"num": [11,22,33]}} // 2023/08/26 17:39:06 encoding/json (Marshal): {"name":"z3","info":{"num":[11,22,33]}} ⚠: 使用json.Marshal() (必须传递指向节点的指针) API Ast.Node提供了许多有特色的API,感兴趣的朋友可以去试一下。 合法性检查: Check(), Error(), Valid(), Exist() 索引: Index(), Get(), IndexPair(), IndexOrGet(), GetByPath() 转换至 go 内置类型: Int64(), Float64(), String(), Number(), Bool(), Map[UseNumber|UseNode](), Array[UseNumber|UseNode](), Interface[UseNumber|UseNode]() go 类型打包: NewRaw(), NewNumber(), NewNull(), NewBool(), NewString(), NewObject(), NewArray() 迭代: Values(), Properties(), ForEach(), SortKeys() 修改: Set(), SetByIndex(), Add() 最佳实践 预热 由于 Sonic 使用 golang-asm 作为 JIT 汇编器,这个库并不适用于运行时编译,第一次运行一个大型模式可能会导致请求超时甚至进程内存溢出。为了更好地稳定性,我们建议在运行大型模式或在内存有限的应用中,在使用 Marshal()/Unmarshal() 前运行 Pretouch()。 拷贝字符串 当解码 没有转义字符的字符串时, sonic 会从原始的 JSON 缓冲区内引用而不是复制到新的一个缓冲区中。这对 CPU 的性能方面很有帮助,但是可能因此在解码后对象仍在使用的时候将整个 JSON 缓冲区保留在内存中。实践中我们发现,通过引用 JSON 缓冲区引入的额外内存通常是解码后对象的 20% 至 80% ,一旦应用长期保留这些对象(如缓存以备重用),服务器所使用的内存可能会增加。我们提供了选项 decoder.CopyString() 供用户选择,不引用 JSON 缓冲区。这可能在一定程度上降低 CPU 性能 func base() { // 在sonic.Config中进行配置 snc := sonic.Config{ CopyString: true, }.Froze() } 传递字符串还是字节数组 为了和 encoding/json 保持一致,我们提供了传递 []byte 作为参数的 API ,但考虑到安全性,字符串到字节的复制是同时进行的,这在原始 JSON 非常大时可能会导致性能损失。因此,你可以使用 UnmarshalString() 和 GetFromString() 来传递字符串,只要你的原始数据是字符串,或零拷贝类型转换对于你的字节数组是安全的。我们也提供了 MarshalString() 的 API ,以便对编码的 JSON 字节数组进行零拷贝类型转换,因为 sonic 输出的字节始终是重复并且唯一的,所以这样是安全的。 零拷贝类型转换是一种技术,它允许你在不进行实际数据复制的情况下,将一种数据类型转换为另一种数据类型。这种转换通过操作原始内存块的指针和切片来实现,避免了额外的数据复制,从而提高性能并减少内存开销. 需要注意的是,零拷贝类型转换虽然可以提高性能,但也可能引入一些安全和可维护性的问题,特别是当直接操作指针或内存映射时。 性能优化 在 完全解析的场景下, Unmarshal() 表现得比 Get()+Node.Interface() 更好。 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // complete parsing m := map[string]interface{}{} sonic.Unmarshal([]byte(data), &m) } 但是如果你只有特定 JSON的部分模式,你可以将 Get() 和 Unmarshal() 结合使用: func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // complete parsing m := map[string]interface{}{} sonic.Unmarshal([]byte(data), &m) // partial parsing clear(m) node, err := sonic.GetFromString(data, "info", "num", 1) if err != nil { panic(err) } log.Println(node.Raw()) } 参考 github.com/sonic
Sonic - 高性能JSON库 介绍 我们在日常开发中,常常会对JSON进行序列化和反序列化。Golang提供了encoding/json包对JSON进行Marshal/Unmarshal操作。但是在大规模数据场景下,该包的性能和开销确实会有点不够看。在生产环境下,JSON 序列化和反序列化会被频繁的使用到。在测试中,CPU使用率接近 10%,其中极端情况下超过 40%。因此,JSON 库的性能是提高机器利用率的关键问题。 Sonic是一款由字节跳动开发的一个全新的高性能、适用广泛的 JSON 库。在设计上借鉴了多款JSON库,同时为了实现对标准库的真正插拔式替换,Sonic使用了 JIT** (即时编译)**。 Sonic的特色 我们可以看出:Sonic是一个主打快的JSON库。 运行时对象绑定,无需代码生成 完备的 JSON 操作 API 快,更快,还要更快! Sonic的设计 针对编解码动态汇编的函数调用开销,使用 JIT 技术在运行时组装与模式对应的字节码(汇编指令),最终将其以 Golang 函数的形式缓存在堆外内存上。 针对大数据和小数据共存的实际场景,使用预处理判断(字符串大小、浮点数精度等)将 SIMD 与标量指令相结合,从而实现对实际情况的最佳适应。 对于 Golang 语言编译优化的不足,使用 C/Clang 编写和编译核心计算函数,并且开发了一套 asm2asm 工具,将经过充分优化的 x86 汇编代码转换为 Plan9 格式,最终加载到 Golang 运行时中。 考虑到解析和跳过解析之间的速度差异很大, 惰性加载机制当然也在 AST 解析器中使用了,但以一种更具适应性和高效性的方式来降低多键查询的开销。 在细节上,Sonic进行了一些进一步的优化: 由于 Golang 中的原生汇编函数不能被内联,发现其成本甚至超过了 C 编译器的优化所带来的改善。所以在 JIT 中重新实现了一组轻量级的函数调用: 全局函数表+静态偏移量,用于调用指令 使用寄存器传递参数 Sync.Map 一开始被用来缓存编解码器,但是对于准静态(读远多于写),元素较少(通常不足几十个)的场景,它的性能并不理想,所以使用开放寻址哈希和 RCU 技术重新实现了一个高性能且并发安全的缓存。 详细设计文档可查阅introduction 安装使用 当前我使用的go version是1.21。 官方建议的版本: Go 1.16~1.21 Linux / MacOS / Windows(需要 Go1.17 以上) Amd64 架构 # 下载sonic依赖 $ go get github.com/bytedance/sonic 基本使用 sonic提供了许多功能。本文仅列举其中较为有特色的功能。感兴趣的同学可以去看一下官方的examples 序列化/反序列化 sonic的使用类似于标准包encoding/json包的使用. func base() { m := map[string]interface{}{ "name": "z3", "age": 20, } // sonic序列化 byt, err := sonic.Marshal(&m) if err != nil { log.Println(err) } fmt.Printf("json: %+v\n", string(byt)) // sonic反序列化 um := make(map[string]interface{}) err = sonic.Unmarshal(byt, &um) if err != nil { log.Println(err) } fmt.Printf("unjson: %+v\n", um) } // print // json: {"name":"z3","age":20} // unjson: map[age:20 name:z3] sonic还支持流式的输入输出 Sonic 支持解码 io.Reader 中输入的 json,或将对象编码为 json 后输出至 io.Writer,以处理多个值并减少内存消耗 func base() { m := map[string]interface{}{ "name": "z3", "age": 20, } // 流式io编解码 // 编码 var encbuf bytes.Buffer enc := sonic.ConfigDefault.NewEncoder(&encbuf) if err := enc.Encode(m); err != nil { log.Fatal(err) } else { fmt.Printf("cutomize encoder: %+v", encbuf.String()) } // 解码 var decbuf bytes.Buffer decbuf.WriteString(encbuf.String()) clear(m) dec := sonic.ConfigDefault.NewDecoder(&decbuf) if err := dec.Decode(&m); err != nil { log.Fatal(err) } else { fmt.Printf("cutomize decoder: %+v\n", m) } } // print // cutomize encoder: {"name":"z3","age":20} // cutomize decoder: map[age:20 name:z3] 配置 在上面的自定义流式编码解码器,细心的朋友可能看到我们创建编码器和解码器的时候,是通过sonic.ConfigDefault.NewEncoder() / sonic.ConfigDefault.NewDecoder()这两个函数进行调用的。那么sonic.ConfigDefault是什么? 我们可以通过查看源码: var ( // ConfigDefault is the default config of APIs, aiming at efficiency and safty. // ConfigDefault api的默认配置,针对效率和安全。 ConfigDefault = Config{}.Froze() // ConfigStd is the standard config of APIs, aiming at being compatible with encoding/json. // ConfigStd是api的标准配置,旨在与encoding/json兼容。 ConfigStd = Config{ EscapeHTML : true, SortMapKeys: true, CompactMarshaler: true, CopyString : true, ValidateString : true, }.Froze() // ConfigFastest is the fastest config of APIs, aiming at speed. // ConfigFastest是api的最快配置,旨在提高速度。 ConfigFastest = Config{ NoQuoteTextMarshaler: true, }.Froze() ) sonic提供了三种常用的Config配置。这些配置中对一些场景已经预定义好了对应的Config。 其实我们使用的sonic.Marshal()函数就是调用了默认的ConfigDefault // Marshal returns the JSON encoding bytes of v. func Marshal(val interface{}) ([]byte, error) { return ConfigDefault.Marshal(val) } // Unmarshal parses the JSON-encoded data and stores the result in the value pointed to by v. // NOTICE: This API copies given buffer by default, // if you want to pass JSON more efficiently, use UnmarshalString instead. func Unmarshal(buf []byte, val interface{}) error { return ConfigDefault.Unmarshal(buf, val) } 但是在一些场景下我们不满足于sonic预定义的三个Config。此时我们可以定义自己的Config进行个性化的编码和解码。 首先先看一下Config的结构。 // Config is a combination of sonic/encoder.Options and sonic/decoder.Options type Config struct { // EscapeHTML indicates encoder to escape all HTML characters // after serializing into JSON (see https://pkg.go.dev/encoding/json#HTMLEscape). // WARNING: This hurts performance A LOT, USE WITH CARE. EscapeHTML bool // SortMapKeys indicates encoder that the keys of a map needs to be sorted // before serializing into JSON. // WARNING: This hurts performance A LOT, USE WITH CARE. SortMapKeys bool // CompactMarshaler indicates encoder that the output JSON from json.Marshaler // is always compact and needs no validation CompactMarshaler bool // NoQuoteTextMarshaler indicates encoder that the output text from encoding.TextMarshaler // is always escaped string and needs no quoting NoQuoteTextMarshaler bool // NoNullSliceOrMap indicates encoder that all empty Array or Object are encoded as '[]' or '{}', // instead of 'null' NoNullSliceOrMap bool // UseInt64 indicates decoder to unmarshal an integer into an interface{} as an // int64 instead of as a float64. UseInt64 bool // UseNumber indicates decoder to unmarshal a number into an interface{} as a // json.Number instead of as a float64. UseNumber bool // UseUnicodeErrors indicates decoder to return an error when encounter invalid // UTF-8 escape sequences. UseUnicodeErrors bool // DisallowUnknownFields indicates decoder to return an error when the destination // is a struct and the input contains object keys which do not match any // non-ignored, exported fields in the destination. DisallowUnknownFields bool // CopyString indicates decoder to decode string values by copying instead of referring. CopyString bool // ValidateString indicates decoder and encoder to valid string values: decoder will return errors // when unescaped control chars(\u0000-\u001f) in the string value of JSON. ValidateString bool } 由于字段较多。笔者就选择几个字段进行演示,其他字段使用方式都是一致。 假设我们希望对JSON序列化按照key进行排序以及将JSON编码成紧凑的格式。我们可以配置Config进行Marshal操作 func base() { snc := sonic.Config{ CompactMarshaler: true, SortMapKeys: true, }.Froze() snc.Marshal(obj) } 考虑到排序带来的性能损失(约 10% ), sonic 默认不会启用这个功能。 Sonic 默认将基本类型( struct , map 等)编码为紧凑格式的 JSON ,除非使用 json.RawMessage or json.Marshaler 进行编码: sonic 确保输出的 JSON 合法,但出于性能考虑,不会加工成紧凑格式。我们提供选项 encoder.CompactMarshaler 来添加此过程, Ast.Node sonic提供了Ast.Node的功能。Sonic/ast.Node 是完全独立的 JSON 抽象语法树库。它实现了序列化和反序列化,并提供了获取和修改通用数据的鲁棒的 API。 先来简单介绍一下Ast.Node:ast.Node 通常指的是编程语言中的抽象语法树(Abstract Syntax Tree)节点。抽象语法树是编程语言代码在编译器中的内部表示,它以树状结构展现代码的语法结构,便于编译器进行语法分析、语义分析、优化等操作。 在很多编程语言的编译器或解释器实现中,抽象语法树中的每个元素(节点)都会有对应的数据结构表示,通常这些数据结构会被称为 ast.Node 或类似的名字。每个 ast.Node 表示源代码中的一个语法结构,如表达式、语句、函数声明等。 抽象语法树的节点可以包含以下信息: 节点的类型:例如表达式、语句、函数调用等。 节点的内容:节点所代表的源代码的内容。 子节点:一些节点可能包含子节点,这些子节点也是抽象语法树的节点,用于构建更复杂的语法结构。 属性:一些节点可能会包含附加的属性,如变量名、操作符类型等。 我们通过几个案例理解一下Ast.Node的使用。 准备数据 data := `{"name": "z3","info":{"num": [11,22,33]}}` 将数据转换为Ast.Node 通过传入bytes或者string返回一个Ast.Node。其中你可以指定path获取JSON中的子路径元素。 每个路径参数必须是整数或者字符串 整数是目标索引(>=0),表示以数组形式搜索当前节点。 字符串为目标key,表示搜索当前节点为对象。 // 函数签名: func Get(src []byte, path ...interface{}) (ast.Node, error) { return GetFromString(string(src), path...) } // GetFromString与Get相同,只是src是字符串,这样可以减少不必要的内存拷贝。 func GetFromString(src string, path ...interface{}) (ast.Node, error) { return ast.NewSearcher(src).GetByPath(path...) } 获取当前节点的完整数据 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // no path return all json string root, err := sonic.GetFromString(data) if err != nil { log.Panic(err) } if raw, err := root.Raw(); err != nil { log.Panic(err) } else { log.Println(raw) } } // print // 2023/08/26 17:15:52 {"name": "z3","info":{"num": [11,22,33]}} 根据path或者索引获取数据 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // no path return all json string root, err := sonic.GetFromString(data) if err != nil { log.Panic(err) } // according to path(根据key,查询当前node下的元素) if path, err := root.GetByPath("name").Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // indexOrget (同时提供index和key进行索引和key的匹配) if path, err := root.IndexOrGet(1, "info").Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // index (按照index进行查找当前node下的元素) // root.Index(1).Index(0).Raw()意味着 // root.Index(1) == "info" // root.Index(1).Index(0) == "num" // root.Index(1).Index(0).Raw() == "[11,22,33]" if path, err := root.Index(1).Index(0).Raw(); err != nil { log.Panic(err) } else { log.Println(path) } } // print // 2023/08/26 17:17:49 "z3" // 2023/08/26 17:17:49 {"num": [11,22,33]} // 2023/08/26 17:17:49 [11,22,33] Ast.Node支持链式调用。故我们可以从root node节点,根据path路径向下搜索指定的元素。 index和key混用 user := root.GetByPath("statuses", 3, "user") // === root.Get("status").Index(3).Get("user") 根据path进行修改数据 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // no path return all json string root, err := sonic.GetFromString(data) if err != nil { log.Panic(err) } // according to path if path, err := root.GetByPath("name").Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // indexOrget (同时提供index和key进行索引和key的匹配) if path, err := root.IndexOrGet(1, "info").Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // index if path, err := root.Index(1).Index(0).Raw(); err != nil { log.Panic(err) } else { log.Println(path) } // set // ast提供了很多go类型转换node的函数 if _, err := root.Index(1).SetByIndex(0, ast.NewArray([]ast.Node{ ast.NewNumber("101"), ast.NewNumber("202"), })); err != nil { log.Panic(err) } raw, _ := root.Raw() log.Println(raw) } // print // 2023/08/26 17:23:55 "z3" // 2023/08/26 17:23:55 {"num": [11,22,33]} // 2023/08/26 17:23:55 [11,22,33] // 2023/08/26 17:23:55 {"name":"z3","info":{"num":[101,202]}} 序列化 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // no path return all json string root, err := sonic.GetFromString(data) if err != nil { log.Panic(err) } bts, _ := root.MarshalJSON() log.Println("Ast.Node(Marshal): ", string(bts)) btes, _ := json.Marshal(&root) log.Println("encoding/json (Marshal): ", string(btes)) } // print // 2023/08/26 17:39:06 Ast.Node(Marshal): {"name": "z3","info":{"num": [11,22,33]}} // 2023/08/26 17:39:06 encoding/json (Marshal): {"name":"z3","info":{"num":[11,22,33]}} ⚠: 使用json.Marshal() (必须传递指向节点的指针) API Ast.Node提供了许多有特色的API,感兴趣的朋友可以去试一下。 合法性检查: Check(), Error(), Valid(), Exist() 索引: Index(), Get(), IndexPair(), IndexOrGet(), GetByPath() 转换至 go 内置类型: Int64(), Float64(), String(), Number(), Bool(), Map[UseNumber|UseNode](), Array[UseNumber|UseNode](), Interface[UseNumber|UseNode]() go 类型打包: NewRaw(), NewNumber(), NewNull(), NewBool(), NewString(), NewObject(), NewArray() 迭代: Values(), Properties(), ForEach(), SortKeys() 修改: Set(), SetByIndex(), Add() 最佳实践 预热 由于 Sonic 使用 golang-asm 作为 JIT 汇编器,这个库并不适用于运行时编译,第一次运行一个大型模式可能会导致请求超时甚至进程内存溢出。为了更好地稳定性,我们建议在运行大型模式或在内存有限的应用中,在使用 Marshal()/Unmarshal() 前运行 Pretouch()。 拷贝字符串 当解码 没有转义字符的字符串时, sonic 会从原始的 JSON 缓冲区内引用而不是复制到新的一个缓冲区中。这对 CPU 的性能方面很有帮助,但是可能因此在解码后对象仍在使用的时候将整个 JSON 缓冲区保留在内存中。实践中我们发现,通过引用 JSON 缓冲区引入的额外内存通常是解码后对象的 20% 至 80% ,一旦应用长期保留这些对象(如缓存以备重用),服务器所使用的内存可能会增加。我们提供了选项 decoder.CopyString() 供用户选择,不引用 JSON 缓冲区。这可能在一定程度上降低 CPU 性能 func base() { // 在sonic.Config中进行配置 snc := sonic.Config{ CopyString: true, }.Froze() } 传递字符串还是字节数组 为了和 encoding/json 保持一致,我们提供了传递 []byte 作为参数的 API ,但考虑到安全性,字符串到字节的复制是同时进行的,这在原始 JSON 非常大时可能会导致性能损失。因此,你可以使用 UnmarshalString() 和 GetFromString() 来传递字符串,只要你的原始数据是字符串,或零拷贝类型转换对于你的字节数组是安全的。我们也提供了 MarshalString() 的 API ,以便对编码的 JSON 字节数组进行零拷贝类型转换,因为 sonic 输出的字节始终是重复并且唯一的,所以这样是安全的。 零拷贝类型转换是一种技术,它允许你在不进行实际数据复制的情况下,将一种数据类型转换为另一种数据类型。这种转换通过操作原始内存块的指针和切片来实现,避免了额外的数据复制,从而提高性能并减少内存开销. 需要注意的是,零拷贝类型转换虽然可以提高性能,但也可能引入一些安全和可维护性的问题,特别是当直接操作指针或内存映射时。 性能优化 在 完全解析的场景下, Unmarshal() 表现得比 Get()+Node.Interface() 更好。 func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // complete parsing m := map[string]interface{}{} sonic.Unmarshal([]byte(data), &m) } 但是如果你只有特定 JSON的部分模式,你可以将 Get() 和 Unmarshal() 结合使用: func base() { data := `{"name": "z3","info":{"num": [11,22,33]}}` // complete parsing m := map[string]interface{}{} sonic.Unmarshal([]byte(data), &m) // partial parsing clear(m) node, err := sonic.GetFromString(data, "info", "num", 1) if err != nil { panic(err) } log.Println(node.Raw()) } 参考 github.com/sonic -
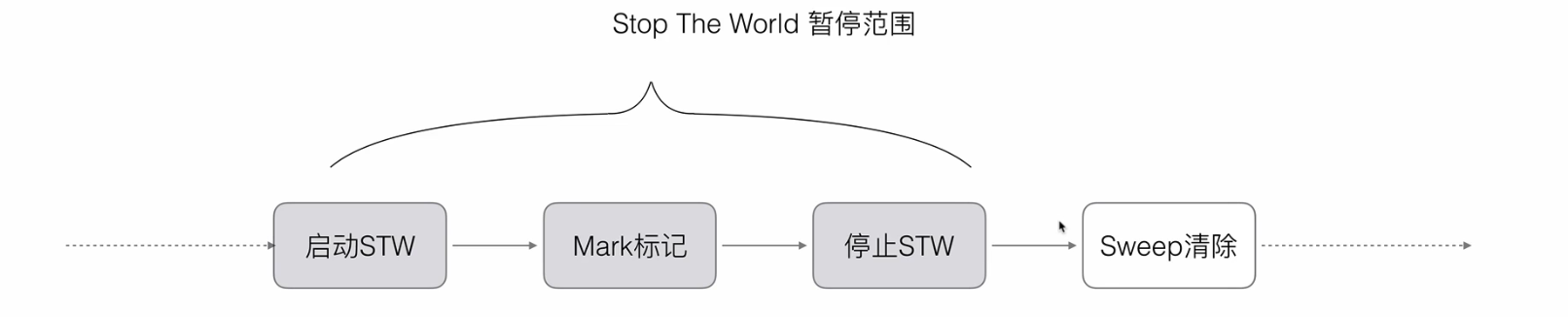
go 垃圾回收 gc 概述 垃圾回收(Garbage Collection),简称 GC,对于高级语言是有必需的,因为高级语言要更加关注的是业务,不能花太多精力去关注底层内存释放的问题。 v 1.3 的标记清除算法 标记清除算法,可以概括为以下 4 步骤,循环重复,直到 process 程序生命周期结束: 暂停程序(不然期间会产生新的对象),从 main 根函数出发,找到可达对象和不可达对象。 然后将可达对象变标记上。 然后,清除未标记的对象。 恢复程序运行。 缺点: stw(stop the world)让程序暂停,会表现出卡顿现象,这个是最重要的问题 标记步骤,需要扫描整个 heap(堆),耗费时间多 清除数据,会产生 heap 碎片 在 go V1.3 之前使用的是这个算法。不过 go 做了点优化,为了缩短了 stw 的时间范围,将第三步和第四步骤做了替换。mark 标记完成后,就恢复程序的运行,清除工作和业务程序并行运行。 v 1.5 的三色标记算法 三色标记法有白、灰、黑三个颜色的列表。 白色的列表代表没有被遍历到的, 灰色代表正在被遍历的临时状态, 黑色代表是遍历过的。 经过遍历后,最终只会剩下白色和黑色的两种,把白色的不可达对象给清除掉即可。 工作过程如下所示: 第一步,只要是新创建的对象,默认的颜色都是标记为"白色"。所以,以下的这些对象都会在白色列表中。 第二步,每次 GC 回收开始,首先遍历根节点,非递归,只遍历一次。把遍历到的对象从白色集合放入"灰色"集合。 如下图中,根结点遍历会操作,会遍历到对象 1 和对象 4。然后把着两个对象放到灰色标记表里。 第三步,开始遍历灰色集合,将灰色对象引用的对象从白色集合放入灰色集合中,之后将已经遍历完成的灰色对象放入黑色集合。 如上图所示,遍历灰色 对象 1 和灰色 对象 4,得到他们的引用 对象 2 和 对象 7,然后把 对象 2 和 对象 7 放到灰色列表里,对象 1 和对象 4 放到黑色列表里。 第四步,重复第三步,直到灰色中无任何对象。遍历灰色列表里的对象 2 和对象 7,把对象 2 的引用对象 3 变成灰色,然后对象 2 和对象 7 已经遍历完就变成黑色。 重复几次后,最终会得到如下所示的表 第五步:回收所有的白色标记表的对象 5 和对象 6. 也就是回收垃圾。 和普通标记清除算法比有什么不同点 三色标记法是一层层的开始标记,不是一次性全部标记 三色标记法,没有 stw,什么情况下会出现对象丢失? 如果此时 gc 执行到下图这个环节的时候,因为没有 stw,程序还在运行,如果发生以下两个动作 白色对象被黑色对象 4引用 灰色 对象 2 丢失了和该 白色对象3 的关系 此时因为灰色 对象 2 已经没有引用 对象 3 了,所以遍历 对象 2 的时候,没法找到 对象 3,对象 3 就会被当做垃圾误清除 强弱三色不变式,确保对象不丢失 强三色不变式:允许黑色引用灰色(已经遍历了灰色,不会丢失灰色),不允许黑色引用白色(白色如果是上述的这个两个条件就会丢失,所以直接不允许),这样就会破坏上述中的条件 1 弱三色不变式:允许黑色引用白色,但是,该白色的上游链中必须有一个灰色引用到,这样该灰色最终会遍历到这个白色。 屏障机制,确保不被误删除 插入屏障: 对象被引用的时候触发的机制,在 a 对象引用 b 对象的时候,b 对象被标记成灰色,满足了强三色不变式,这样就不存在黑色引用白色的了。 不足点是:因为这个插入屏障只有在写的堆上才有,栈(用于函数调用啥的)上的空间比较少,要求效率要高,出于效率的考虑,栈上没有这个机制。所以三色标记结束的时候,要 stw 来重新扫描栈,大约 10-100ms。 删除屏障: 被删除的对象,如果自身是灰色或者白色,那么被标记成灰色,满足弱三色不变公式。如下图中,对象 5 和对象 1 之间的引用关系被删除的话,这个时候对象 5 设置成灰色就好。 但是这操作的话有个问题,这个对象 5 其实已经是垃圾了,却还存在,只能等到下一轮 gc 的时候,才会被清除。虽然会有删除精度不高的问题,但是能确保不会被错删除 v 1.8 三色标记法+混合写屏障 混合写屏障,就是把删除和插入屏障放在一起,加上一个栈上的默认全部黑操作,整个过程不会有stw,具体操作: GC 开始将栈上的对象可达结点全部扫描并标记为黑色 (之后不再进行第二次重复扫描,无需 STW) GC 期间,任何在栈上创建的新对象,均为黑色,下一轮 gc 删除 堆上被删除的对象标记为灰色 堆上被添加的对象标记为灰色
-
Go 语言接口语法指南 | 进阶接口语法学习 概述 接口主要是用于实现多态的效果,接口是一个类型,一个抽象的类型,既然是类型,就可以定义接口类型的变量。 定义 接口好像用于定义方法的,写上方法签名列表即可 type 接口类型名 interface{ 方法名1( 参数列表1 ) 返回值列表1 // 签名 方法名2( 参数列表2 ) 返回值列表2 … } 接口名称:我们一般会在接口名称后面添加 er。 方法签名: 当方法名首字母是大写且这个接口类型名首字母也是大写时,这个方法可以被接口所在的包(package)之外的代码访问,也就是说可以被其它包所实现; 参数列表和返回值列表中的参数 变量名可以省略 type sayer interface { Say() string } 结构体变量赋值 如果一个变量定义为接口类型的变量,那么如果一个结构体实现了这个接口,并且方法的接收者都是值类型的,那么这个结构体的值类型和指针类型都可以赋予给这个接口变量。 例如下例中,结构体 dog,实现了 Mover 接口的 move 和 eat 方法,并且这个两个方法的接受者都是值类型,所以 dog{} 可以赋值给这个 Mover 接口变量,&dog{} 也可以赋值给这个 Mover 接口变量 package main import "fmt" type Mover interface { move() eat() } // dog 类型的方法的接受者都是值类型 type dog struct{} func (d dog) move() { fmt.Println("狗会动") } func (d dog) eat() { fmt.Println("吃") } func main() { var x Mover x = &dog{} // 指针类型可以赋值 x.move() var y Mover y = dog{} // 值类型可以赋值 y.move() } 但是,如果结构体方法的接收者存在指针类型,那么只能这个结构体的指针类型都可以赋予给这个接口变量,值类型不行,会报错。 如下所示 move 方法是指针类型,所以只能 &dog{} 赋予给 Mover 接口变量,用 dog{} 值类型赋予接口变量的话,将会报错 package main import "fmt" type Mover interface { move() eat() } type dog struct{} // move 方法的接受者是指针类型*dog func (d *dog) move() { fmt.Println("狗会动") } func (d dog) eat() { fmt.Println("吃") } func main() { var x Mover x = &dog{} // 指针类型可以赋值 x.move() var y Mover y = dog{} // 值类型不可以赋值了,会报错!!! y.move() } 空接口 接口是行为规范的集合,空接口没有任务行为规范,也就是接口方法为空。因为没有任何行为规范,所以任何类型都可以属于空接口类型。所以空接口可以接收任何参数。 package main import "fmt" // Mover 自定义空接口 type Mover interface { } // dog 空接口参数arg func dog(arg Mover) { } func main() { // 空接口可以接受任何参数 dog(10) dog("10") // 空接口可以接受任何参数 var a Mover a = 10 a = "10" // Println 参数类型就是空接口 fmt.Println(a) } go 里其实已经自带了一个空接口类型 interface{},不需要我们自定义(上例的 Mover 空接口) package main import "fmt" func main() { // go里自带的空接口类型interface{} var a interface{} a = 10 a = "10" // Println 参数类型就是空接口 fmt.Println(a) } 在 go1.18 之后,官方更加建议使用 any 来替代 interface{},这样可以少写几个字母,没有别的差别。 package main import "fmt" func main() { // go1.18之后,官方推荐用any替代interface{} var a any a = 10 a = "10" // Println 参数类型就是空接口 fmt.Println(a) } 断言 由于空接口可以存任何类型的值,有时候我们想要知道,空接口类型的值到底是什么类型,这个时候就需要对值进行断言。 package main import "fmt" func main() { // 定义一个空接口x var x interface{} x = "Hello 沙河" v, ok := x.(string) // 断言是否是字符串,ok为true或false,v为变量的值 fmt.Println(v, ok) } 断言配合switch使用 anyVal.(type)的形式必须配合switch使用 var anyVal interface{} anyVal = "123" switch specificTypeVal := anyVal.(type) { case string: fmt.Println(specificTypeVal) // 输出字符串3 } 有时候我们希望结构体必须实现某个接口,如果没有实现的话,就编译报错,启动不起来,可以这样写 package main import ( "io" ) type MyStruct struct{} func (m *MyStruct) Read(p []byte) (n int, err error) { return 0, nil } // Impl 或者写个方法,返回这个接口类型也可以 func (m *MyStruct) Impl() io.Reader { return (*MyStruct)(nil) } // 这个两种方式,方法的接受者可以是指针,也可以是值类型 var _ io.Reader = (*MyStruct)(nil) // 把nil转成*MyStruct类型 var _ io.Reader = &MyStruct{} type MyStructCaseTwo struct{} func (m MyStructCaseTwo) Read(p []byte) (n int, err error) { return 0, nil } // 方法的接受这必须是指针类型 var _ io.Reader = MyStructCaseTwo{} func main() { } 接口的嵌套 接口与接口间可以通过嵌套创造出新的接口,嵌套得到的接口的使用与普通接口一样 // Sayer 接口 type Sayer interface { say() } // Mover 接口 type Mover interface { move() } // 接口嵌套 type animal interface { Sayer Mover } 接口的实现 接口是隐式实现的,一个对象只要全部实现了接口中的方法,那么就实现了这个接口;换句话说,接口就是一个 需要实现的方法列表。 type sayer interface { Say() string } type Cat struct{} // 实现了sayer接口 func (c Cat) Say() string { return "喵喵喵" } 一个类型可以实现多个接口,只需要实现每个接口里的方法即可 type Sayer interface { say() } type Mover interface { move() } type dog struct { name string } func (d dog) say() { fmt.Printf("%s会叫汪汪汪\n", d.name) } func (d dog) move() { fmt.Printf("%s会动\n", d.name) } func main() { var x Sayer var y Mover a := dog{name: "旺财"} x = a y = a x.say() y.move() } 还可以多个类型实现同一个接口,这就是多态的实现,同一个接口类型,不同对象有不同的表现,如下所示,同一个 move 方法,dog 结构体实例和 car 结构体实例,执行的结果是不一样的 type Mover interface { move() } type dog struct { name string } type car struct { brand string } func (d dog) move() { fmt.Printf("%s会跑\n", d.name) } func (c car) move() { fmt.Printf("%s速度70迈\n", c.brand) } func main() { var x Mover x = dog{name: "旺财"} x.move() x = car{brand: "保时捷"} x.move() }
-
Go语言泛型指南| Go语言泛型教程 从语法的角度来讲,泛型是从接口层面演化而来的。 下面例子中,f1 是依赖于接口类型 Man,f2 是依赖于 T 类型,T 类型等价于 Man 类型。 package main type Man interface { Say() } type Student struct { } func (s Student) Say() { } // 面向接口编程,a必须是Man接口类型 func f1(a Man) { } // 泛型,中括号里可以理解为T是Man的别名 // 既然T等Man,所以f1和f2就等价了 func f2[T Man](a T) { } func main() { f1(Student{}) f2(Student{}) } 应用在函数里 跟接口的语法有点类似,就是里面的内容是数据类型,而不是方法签名,如下所示 Happy 就是联合类型,将来要使用到 Happy 的时候,只需要用到任意一个类型传递进去就可以。 // 联合类型 type Happy interface { // ~T,是go1.18新增的符号,~t表示底层是T的所有类型 int | ~int32 | int8 | string | ~bool } // a,b必须同时为int、~int32、int8、string、 ~bool // 不可以一个是int,一个是string func f3[T Happy](a, b T, c float64) { } func main() { // a,b都是int f3(1, 2, 3.1) f3(true, false, 3.1) f3("a", "b", 3.1) } 如果不想要定义个结构体,可以如下所示,当然,a, b 两个参数每次调用的时候,也要是同一个类型。 package main func f4[T int | string | bool](a, b T, c float64) { } func main() { // a,b都是int f4(1, 1, 3.1) f4(true, false, 3.1) f4("a", "b", 3.1) } 应用在结构体 在接口体名称后面新增一个中括号,在中括号里设置好别名 package main import "fmt" type Happy interface { // ~T,是go1.18新增的符号,~t表示底层是T的所有类型 int | ~int32 | int8 | string | ~bool } type Bird[T Happy, S int | string] struct { Head T Hair S } func (b *Bird[T, S]) SetHead(h T) { b.Head = h } func main() { // [int, string],定下来[T, S]是什么 bird := Bird[int, string]{ Head: 3, Hair: "lang", } fmt.Println(bird.Head, bird.Head) }
-
Go语言错误处理:Go Errors包的最佳实践 errors. Is 用于判断该错误是否是某个类型,1.18 后,官方推荐使用 Is 来判断错误是否相等。 package main import ( "errors" "fmt" ) var ( ErrDivideByZero = errors.New("divide by zero") ErrNegativeSquareRoot = errors.New("square root is negative") ) func mathFunc(a, b int) error { if b == 0 { return ErrDivideByZero } else { return nil } } func main() { var a, b int err := mathFunc(a, b) if err != nil { // 此处等价于 err == ErrDivideByZero if errors.Is(err, ErrDivideByZero) { fmt.Println("除数为0异常") } else if errors.Is(err, ErrNegativeSquareRoot) { fmt.Println("对于负数开方异常") } } } 和等号判断 err 是否相等相比,Is 判断还有个好处,就是如果是该错误的包装的话,Is 判断依据相等 package main import ( "errors" "fmt" ) var ( ErrDivideByZero = errors.New("divide by zero") ErrNegativeSquareRoot = errors.New("square root is negative") ) func mathFunc(a, b int) error { if b == 0 { // %w,可以对一个错误进行包装,应该是wrap的缩写 return fmt.Errorf("mathFunc %w", ErrDivideByZero) } else { return nil } } func main() { var a, b int err := mathFunc(a, b) if err != nil { // fmt.Errorf("mathFunc %w", ErrDivideByZero),包装后,是不同的类型,不相等了 if err == ErrDivideByZero { fmt.Println("除数为0异常,通过等号方式") } // 但是这个Is判断依旧相等 if errors.Is(err, ErrDivideByZero) { fmt.Println("除数为0异常") } else if errors.Is(err, ErrNegativeSquareRoot) { fmt.Println("对于负数开方异常") } } } errors. As 这个方法除了可以判读类型是否是同一种,如果是的话,还会赋值初始化。 package main import ( "errors" "fmt" ) type DivisionError struct { IntA int IntB int Msg string } func (e DivisionError) Error() string { return e.Msg } type SquareError struct { IntA int IntB int Msg string } func (e SquareError) Error() string { return e.Msg } func mathFunc(a, b int) error { if b == 0 { err := DivisionError{IntA: a, IntB: b, Msg: "除数为0"} return err } else { return nil } } func main() { var a, b int err := mathFunc(a, b) var de DivisionError var se SquareError if err != nil { // 判断err是否是DivisionError错误 // 如果是的话,将err初始化到de,所以需要传指针 if errors.As(err, &de) { // 所以这边可以直接取err的具体信息 fmt.Printf("除数为0异常,a=%d,b=%d,msg=%s\n", de.IntA, de.IntB, de.Msg) } else if errors.Is(err, &se) { fmt.Printf("对负数开方异常,a=%d,b=%d,msg=%s\n", de.IntA, de.IntB, de.Msg) } } } 同样,如果对错误进行包装,erros.As 判断依据成立 package main import ( "errors" "fmt" ) type DivisionError struct { IntA int IntB int Msg string } func (e DivisionError) Error() string { return e.Msg } type SquareError struct { IntA int IntB int Msg string } func (e SquareError) Error() string { return e.Msg } func mathFunc(a, b int) error { if b == 0 { err := DivisionError{IntA: a, IntB: b, Msg: "除数为0"} // 对错误进行包装 return fmt.Errorf("mathFunc %w", err) } else { return nil } } func main() { var a, b int err := mathFunc(a, b) var de DivisionError var se SquareError if err != nil { // 判断err是否是DivisionError错误 // 如果是的话,将err初始化到de,所以需要传指针 if errors.As(err, &de) { // 所以这边可以直接取err的具体信息 fmt.Printf("除数为0异常,a=%d,b=%d,msg=%s\n", de.IntA, de.IntB, de.Msg) } else if errors.Is(err, &se) { fmt.Printf("对负数开方异常,a=%d,b=%d,msg=%s\n", de.IntA, de.IntB, de.Msg) } } }
-
Go并发同步的实现策略与技巧 - 详解与实例 业务模型介绍。 上游:M 个协程接收用户注册,把用户添加到集合 users 中。 下游:N个协程监听users,当发现它里面攒够100个用户时,给前3(常量H)个注册的用户发放积分,然后协程终止。(这部分逻辑上游不关心,相关代码不能放到上游协程里实现) 实现代码 package main import ( "math/rand" "sort" "sync" "sync/atomic" "time" ) type User struct { RegTime time.Time //注册时间 Score int //积分 } var ( users []*User //用户集合 mu sync.Mutex //读写users之前先加锁,保证它的并发安全性 listenNumber int32 //监听全局变量users的次数 prized bool //是否已经执行过积分奖励 ) const ( H = 3 // 达到100个用户后,给前3个用户积分增加1 M = 8 // 8个协程并发注册 N = 5 // 5个协程并发检查 ) func InitGlobalVar() { users = make([]*User, 0, 500) mu = sync.Mutex{} listenNumber = 0 prized = false } // 给前H个用户积分奖励 func prize() { //按注册时间排序 sort.Slice(users, func(i, j int) bool { return users[i].RegTime.Before(users[j].RegTime) }) //把前H个用户的Score加1 for _, user := range users[:H] { user.Score += 1 } } // 业务模型介绍。 // 上游:M个协程接收用户注册,把用户添加到集合users中。 // 下游:N个协程监听users,当发现它里面攒够100个用户时,给前3(常量H)个注册的用户发放积分,然后协程终止。(这部分逻辑上游不关心,相关代码不能放到上游协程里实现) /* 方式一:通过for轮询的方式,会消耗很多cpu性能 */ func BusinessModel() { InitGlobalVar() downstreamOver := false //上游 for i := 0; i < M; i++ { go func() { for { //不停地注册新用户 if downstreamOver { break } mu.Lock() users = append(users, &User{RegTime: time.Now()}) //注册用户 mu.Unlock() time.Sleep(time.Millisecond * time.Duration(rand.Intn(100))) //随机休息一段时间,再注册下一个用户 } }() } //下游 wg := sync.WaitGroup{} wg.Add(N) for i := 0; i < N; i++ { go func() { defer wg.Done() for { mu.Lock() if !prized { atomic.AddInt32(&listenNumber, 1) if len(users) >= 100 { prize() // 达到100,发放奖励 prized = true } } mu.Unlock() if prized { break } } }() } wg.Wait() downstreamOver = true } // 减少对全局变量users的监听次数。上游每次改变users时向一个channel里发送一条数据 /* 方式二:通过channel的方式 */ func SignalWithChannel() { InitGlobalVar() ch := make(chan struct{}, 10*N) downstreamOver := false //上游 for i := 0; i < M; i++ { go func() { for { //不停地注册新用户 if downstreamOver { break } mu.Lock() users = append(users, &User{RegTime: time.Now()}) //注册用户 mu.Unlock() ch <- struct{}{} // 每次新增一个user的时候,向channel里添加一个用户 time.Sleep(time.Millisecond * time.Duration(rand.Intn(100))) //随机休息一段时间,再注册下一个用户 } }() } //下游 wg := sync.WaitGroup{} wg.Add(N) for i := 0; i < N; i++ { go func() { defer wg.Done() for { <-ch //阻塞,直到users有改变 mu.Lock() if !prized { atomic.AddInt32(&listenNumber, 1) if len(users) >= 100 { prize() prized = true } } mu.Unlock() if prized { break } } }() } wg.Wait() downstreamOver = true } /* 方式三:通过sync.Cond的方式 */ func SignalWithCond() { InitGlobalVar() cond := sync.NewCond(&mu) //cond.L等价于mu downstreamOver := false //上游 for i := 0; i < M; i++ { go func() { for { //不停地注册新用户 if downstreamOver { break } mu.Lock() users = append(users, &User{RegTime: time.Now()}) //注册用户 mu.Unlock() //通知别人users有变化。Signal只能通知到一个协程 cond.Signal() time.Sleep(time.Millisecond * time.Duration(rand.Intn(100))) //随机休息一段时间,再注册下一个用户 } }() } //下游 wg := sync.WaitGroup{} wg.Add(N) for i := 0; i < N; i++ { go func() { defer wg.Done() for { mu.Lock() //等价于cond.L.Lock() cond.Wait() //阻塞,直到接收到通知。Wait内部会先执行mu.Unlock(),等接收到信号后再执行mu.Lock(),所以在调Wait()之前需要先上锁 if !prized { atomic.AddInt32(&listenNumber, 1) if len(users) >= 100 { prize() prized = true } } mu.Unlock() //等价于cond.L.Unlock() if prized { break } } }() } wg.Wait() downstreamOver = true } /* channel 广播的方式,一下子通过所有子协程 */ func BroadcastWithChannel() { InitGlobalVar() ch := make(chan struct{}, 10*N) downstreamOver := false //上游 for i := 0; i < M; i++ { go func() { for { //不停地注册新用户 if downstreamOver { break } mu.Lock() users = append(users, &User{RegTime: time.Now()}) //注册用户 mu.Unlock() //把n个下游协程全部通知一遍。 //close channel也能实现通知的功能,但是一个channl只能close一次,本业务中我们需要多次通知。实际中上游一般不知道下游协程的数目,这种情况下只能用cond.Broadcast() for j := 0; j < N; j++ { ch <- struct{}{} } time.Sleep(time.Millisecond * time.Duration(rand.Intn(100))) //随机休息一段时间,再注册下一个用户 } }() } //下游 wg := sync.WaitGroup{} wg.Add(N) for i := 0; i < N; i++ { go func() { defer wg.Done() for { <-ch //阻塞,直到users有改变 atomic.AddInt32(&listenNumber, 1) mu.Lock() done := false if len(users) >= 100 { prize() done = true } mu.Unlock() if done { break } } }() } wg.Wait() downstreamOver = true } /* * cond.Broadcast广播的方式 */ func BroadcastWithCond() { InitGlobalVar() cond := sync.NewCond(&mu) //cond.L等价于mu downstreamOver := false //上游 for i := 0; i < M; i++ { go func() { for { //不停地注册新用户 if downstreamOver { break } mu.Lock() users = append(users, &User{RegTime: time.Now()}) //注册用户 mu.Unlock() // 通知所有下游协程 cond.Broadcast() time.Sleep(time.Millisecond * time.Duration(rand.Intn(100))) //随机休息一段时间,再注册下一个用户 } }() } //下游 wg := sync.WaitGroup{} wg.Add(N) for i := 0; i < N; i++ { go func() { defer wg.Done() for { mu.Lock() cond.Wait() atomic.AddInt32(&listenNumber, 1) done := false if len(users) >= 100 { prize() done = true } mu.Unlock() if done { break } } }() } wg.Wait() downstreamOver = true }
-
Go语言接口超时管理及优化 服务端在调用第三方接口有可能会超时,如果超时了,一般不会让客户端一直等,要设置最大响应时间,如果超过这个时间的话,就返回。 代码如下所示: package main import ( "net/http" "time" ) func readDb() string { // 200 ms time.Sleep(200 * time.Millisecond) return "OK" } func home(w http.ResponseWriter, req *http.Request) { var resp string // 容量设置1,类型直接设置空结构体即可 done := make(chan struct{}, 1) go func() { resp = readDb() done <- struct{}{} }() // 阻塞在这里,哪个先返回,就那个解除阻塞 select { case <-done: case <-time.After(300 * time.Millisecond): // 100ms 超时 resp = "timeout" } _, _ = w.Write([]byte(resp)) } func main() { http.HandleFunc("/", home) _ = http.ListenAndServe("127.0.0.1:5678", nil) }
-
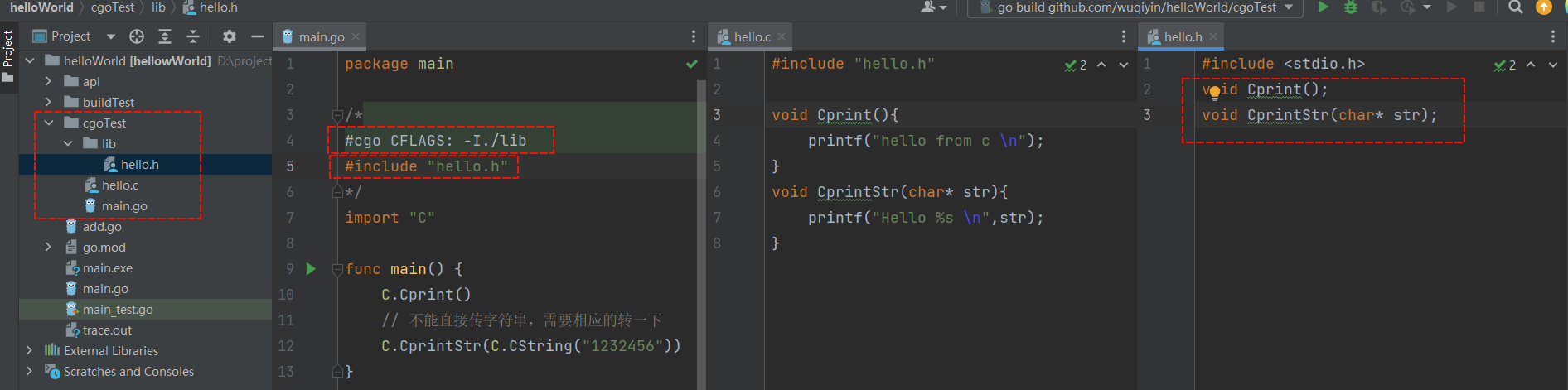
Go语言中CGO的使用指南 概述 在使用 cgo 的时候,首先要开启 cgo 的配置 CGO_ENABLED=1 使用 C 代码 然后如下所示,既可以开始简单的使用 C 代码。 package main /* #include <stdio.h> void Cprint(){ printf("hello from c \n"); } void CprintStr(char* str){ printf("Hello %s \n",str); } */ import "C" func main() { C.Cprint() // 不能直接传字符串,需要相应的转一下 // 有些比较简单的,比如int类型,底层会自动转,也可以不手动转类型 C.CprintStr(C.CString("1232456")) } 但是在项目中,不大可能所有的 C 代码都写在头部,需要做一下拆分。 头部 hello.h 文件, 需要放到 lib 文件夹,此时 go 里需要用 cgo 需要指定头文件位置 头文件的实现放到 hello.c 文件里 main.go 代码如下所示: package main /* #cgo CFLAGS: -I./lib #include "hello.h" */ import "C" func main() { C.Cprint() // 不能直接传字符串,需要相应的转一下 C.CprintStr(C.CString("1232456")) } hello.h 代码如下所示 #include <stdio.h> void Cprint(); void CprintStr(char* str); hello.c 代码如下所示 #include "hello.h" void Cprint(){ printf("hello from c \n"); } void CprintStr(char* str){ printf("Hello %s \n",str); } 代码结构如下: 使用 C++ 代码 和使用 C 嵌入差不多,不过 C++代码不会,如果后续用到的话再学吧。
-
go build 编译详解 go build 参数 -o 参数 假设代码内容如下 package main import "fmt" func main() { fmt.Println("hello world") } 编译之后的可执行文件名称,例如 go build -o hello.exe 这样生成的二进制文件的名称就是 hello.exe -a 参数 强制重新编译所有包(包含标准库) go build -a -p 参数 编译时使用的 cpu 数量,如下所示,指定编译使用 2 个cpu go build -p 2 -v 参数 显示待编译包的名称,这个见 -x,这个和 -x 参数一起用,不然没有显示任何内容 -x 参数 显示正在执行的编译命令。go build 添加 -x -v 选项,可以输出构建的执行细节。-v 用于输出当前正在编译的包,而-x 则用于输出 go build 执行的每一个命令。 go build -x -v -n 参数 仅显示编译的命令,但是不执行 go build -n ![[go build 编译详解-20231224172831941.webp|800]] -work 参数 显示临时的工作目录,编译后不删 go build -work 输出 WORK=D:\project\go\goTempDir\go-build3416180188,编译后这个目录还会保存 -race 参数 启用数据竞争检查(仅amd64)。-race 命令行选项可以在构建时开启竞态检查。在程序运行时,如果发现对数据的并发竞态访问,就会给出警告。 go build -race -gcflags 参数 编译器参数。go build 实质上是通过调用 go 自带的 compile 工具对 go 代码进行编译的。 在 linux 下的位置为 $GOROOT/pkg/tool/linux_amd64/compile。 在 windows 下的位置为 $GOROOT/pkg/tool/windows_amd64/compile.exe。 go build 可以经过 -gcflags 向 compile 工具传递编译所需的命令标志选项集合。这些命令行标志选项是传递给 go 编译器的,因此可以使用下面的命令查看编译器支持的选项集合: go tool compile -help 下面是一些常用的命令行标志选项: -l:关闭内敛。 -N:关闭代码优化 -m:输出逃逸分析的分析决策过程(哪些变量在栈上分配,哪些变量在堆上分配)。 -S:输出汇编代码。 在运行调试器对程序进行调试之前,我们通常使用 -N -l 两个选项关闭对代码的内联和优化,这样能得到更多的调试信息。这个在使用 gdp 调试的是就要 go build -gcflags="-N -l" -ldflags 参数 链接器参数。go build 实质上是通过调用 go 自带的 link 工具对 go 代码进行编译的。 在 linux 下的位置为 $GOROOT/pkg/tool/linux_amd64/link。 在 windows 下的位置为 $GOROOT/pkg/tool/windows_amd64/link.exe。 使用下面的命令可以查看链接器支持的选项集合: go tool link -help 下面三个是常用的命令行选项标志: -X:设定包中 string 类型变量的值。 -s:不生成符号表。 -w:不生成 DWARF(Debugging With Attributed Record Formats)调试信息。 -H:设置可执行文件格式,eg: -H windowgui,告诉编译器是 gui 程序,不要控制台黑框打开 -X 选项的例子:可以在编译时指定程序的版本。 package main import ( "fmt" "os" ) // 全局变量 var version string func main() { if len(os.Args) > 1 && os.Args[1] == "version" { fmt.Println(version) } } 编译指定变量值,一定要带上包名称,如果多个的话,用空格隔开 -X main.version=v0.1 -X main.author=wqy go build -ldflags="-X main.version=v0.1" 执行二进制文件 ./main.exe version # 输出 v0.1 默认情况下,go build 构建出的可执行文件中都是包含 符号表 和 DWARF 格式的调试信息,这虽然让最终二进制文件的体积都增加了,但是符号表和调试信息对于生产环境下程序异常的现场保存和在线调试都有着重要意义。 如果不在意这些信息,或者对应用的大小比较敏感,那么可以通过-s 和-w 选项将这些信息从最终的二进制文件中剔除。 go build -ldflags="-s -w -X main.version=v0.1" 查看汇编代码 以下命令会输出汇编代码 go tool compile -S main.go 或者用 go run -gcflags="-S" main.go 交叉编译 所谓交叉编译,指的是在一个平台下编译出其他平台所需的可执行文件。 如果只是单纯的 go 代码,没有使用 cgo 调用 c 代码,交叉编译非常方便,只需要使用 GOOS, GOARCH 环境变量指定编译目标平台即可。 GOOS=linux go build # 32位 GOOS=linux GOARCH=386 go build 包含 CGO 代码时,需要指定交叉编译器,我平时用 zig,详细使用,可以查阅相关文档。 GOOS=Linux GOARCH=386 CC="zig cc -target x86-Linux" CXX="zig c++ -target x86-Linux" go build -o test 频繁敲写这些代码比较麻烦,可以边写 Makefile 文件,文件名称就命名为 Makefile 或 MAKEFILE dep: @go mod tidy # 代表执行 make linux 之前先执行 dep linux:dep @GOOS=linux GOARCH=amd64 go build -o main main.go @echo "linux exec is build" # 代表执行 make windows 之前先执行 dep windows:dep @GOOS=windows GOARCH=amd64 go build -o main.exe main.go @echo "windows exec is build" 写好 Makefile 文件后,只需要执行 make linux 或者 make windows 命令即可。 如果想要确认文件是否是对应的架构,可以使用 upx 压缩二进制命令,该命令在压缩的时候,会输出架构 upx -9 main 输出 条件编译 方案一 将平台信息加入文件名尾部 hello_windows_386.go,后面的 386 代表是在 32 位系统架构下,也可以是 amd64,可以不指定。 使用的时候,可以使用 go build -x 查看编译过程,查看使用哪个文件。 假设 main 包有 version_windows.go 文件,内容如下 import "fmt" var OS = "windows" func PrintOs() { fmt.Println("windows io") } version_linux.go 文件,内容如下 package main var OS = "linux" func PrintOs() { fmt.Println("linux io") } 然后,main 包在 window 平台下就可以使用该变量了,window 平台编译的时候会使用该变量 package main import "fmt" func main() { fmt.Println(OS) PrintOs() } 在 window 下编译,go build,执行编译后二进制文件,输出结果会是 windows。在 window 下交叉编译 GOOS=linux go build,然后去 linux 下执行二进制文件,输出结果是 linux。 通过这种方式,就可以实现在不同系统底下,调用不同的内容。 方案二 使用 go build 标签来指定这个文件是哪个操作系统下生效。 需要注意的是,标签和 package 语句之间需要有空行。并且这个新写法是 go 1.17 版本后生效,旧的写法和这个写法不一样,是 //+build windows 如果要再指定系统位数,可以这样 //go build linux && amd64,用 && 符号,或者的话用 ||,非的用 !。老版本用 , 和 空格 来代表与或非。例如 // go build windows || linux // go build windows && amd64 // go build windows && !386 // +build windows,amd64 #并且的关系 // +build windows linux #或者关系 方案三 使用 tag 标签。 然后编译的时候,指定 tag 即可。其实方案二,应该是系统默认会传操作系统的 tag,不用我们手动 -tags 参数指定 如果 tag 是这样,代表是有 release 和 linux 标签才可以,-tags 参数后面用空格隔开代表是并且的关系。
-
如何使用Go生成DLL或SO文件 环境准备 首先,必须要有 gcc 工具,windows 下,可以下载 tdm-gcc。 然后,go env 查看环境变量 # 必须开启 set CGO_ENABLED=1 # 表示是64位 set GOARCH=amd64 编写代码 编写 go 代码,有几个注意点: 必须在 main 包 必须有 main 函数,即使是空的 导出的方法,增加注释 // export Add package main import "C" func init() { // 这个函数可以在初始化的时候做一些事情 } // export Add func Add(a int, b int) int { return a + b } func main() { // 这个函数必须有,但是没啥用 } 然后执行: -ldflags "-s -w",表示将一些调试的符号给删除 -buildmode=c-shared,表示要打包动态链接库 -o api64.dll,表示导出文件 go build -ldflags "-s -w" -buildmode=c-shared -o api64.dll .\api.go 如果要编译 32 位的,可以这样 go env -w GOARCH=386 然后重新打包 go build -ldflags "-s -w" -buildmode=c-shared -o api32.dll .\api.go