概要
学习任何编程语言的时候,一般都会有一种数据类型,称为:字典(dic)或映射(map),以键值对为元素的数据集合。其格式如下所示:
{
"age":"18",
"name":"武沛齐",
"email":"silver@qq.com"
}这种类型的最大特点:就是查找速度非常快,因为他的底层存储的是基于 哈希表 存储的(不同语言实现方式会有点差异)。
go 语言中,map 的特点:
- key 是全局唯一的,如果 key 相同,则是覆盖(可以利用这点去做数据去重的功能)
- key 必须可以比较的,因为需要比较是否相等,go 中 slice、map、func 是不可以比较的
- 无序,每次 for 循环的时候,顺序可能都不一样
- 是引用类型(对散列表的引用),所以必须初始化才能使用。
hash 概述
hash 翻译成中文叫做散列,是一种将任意长度的输入,压缩到某一固定长度的输出摘要的过程。
由于这种转换,属于压缩映射,输入空间远大于输出空间,因此不同的输入,可能会输出相同的结果。
此外,hash 在压缩过程中,会存在部分信息的丢失,所以这种映射关系是不可逆的。
- 可重入性:如果使用相同的 hash 函数算法,相同的 key,必然产生相同的 hash 值
- 离散性:只要两个 key 不相同,不管 key 是否相似,结果都是离散的
- 单向性:因为是压缩映射,企图通过 hash 值,反向映射回 key 是无迹可寻的
- hash 冲突:输入是任意形式的,无穷大的;输出是有限的,因此必然存在,不同 key 映射到相同 hash 值的情况,称之为 hash 冲突
hash 表基本原理
hash 表的基本原理是:
取模+拉链法
- 取模平均分配:
- 首先创建一定数量的数组
- 然后对 key 进行 hash 计算得到一个数值
- 最后
hash值%数组的数量,余数就是存放的数组的索引位置,这样就可以平均分配到 hash 表上 - 拉链法解决 hash 冲突:
- 如果取模后索引的位置相同,则在它后面通过链表再添加一个位置存放数据
如下图所示:
- 创建数量为 4 的 hash 表
- 然后对 name 进行 hash 计算,得到的值是 1239837243423
- 最后
1239837243423%4 = 3,余数是 3,所以放在 hash 表索引值是 3 的这个位置
重复面的过程,age 的余数是 0,就放在了 hash 表索引值为 0 的这个位置。
如果说在来个 key: "email",对 4 取模,得到的也是 0,就会 hash 冲突,那么就在第一个位置往右边,以链表的形式,新增数据。
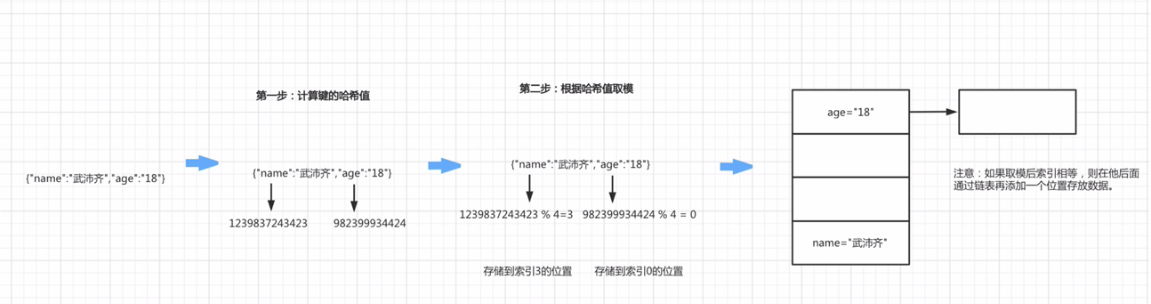
这种结构之所以快,是因为根据 key 可以直接找到数据存放的位置,如果位置相同,可以通过链表从前往后查找比较。
go map 底层原理
go map 的主要原理是:取模+开放寻址和拉链法 的方式。
map 中,会创建一个 $2^B$ 长度的数组标准桶(数组在内存中是连续的)。
- 每个桶固定可以存 8 个键值对,这个 8 个值在内存中是连续的(开放寻址)
- 如果超过 8 个键值对同一个索引中,此时会创建桶链表的方式来化解这个问题(拉链法)。
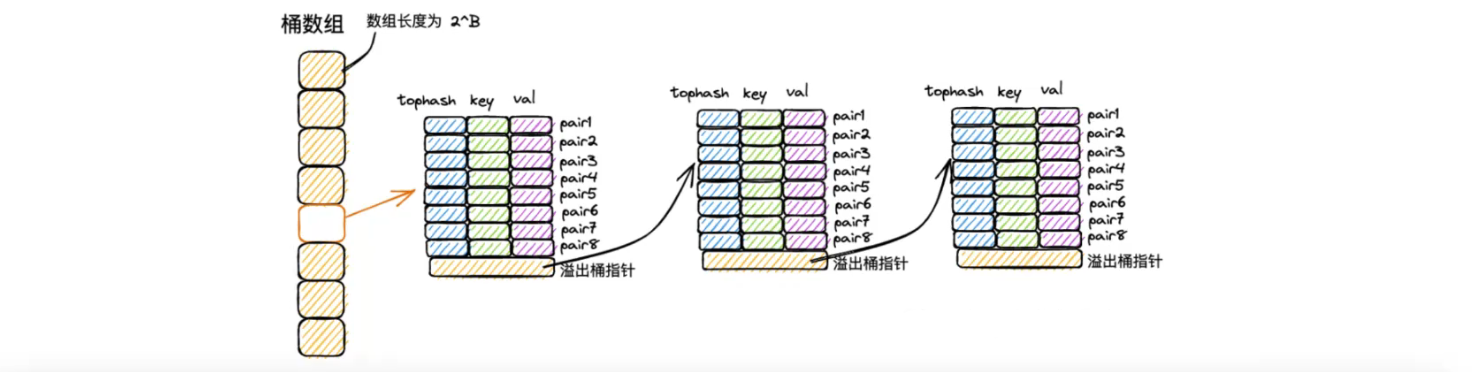
拉链法
将命中同一个桶的元素,通过链表的形式进行链接,因此不需要事先申请内存空间,需要拓展的时候,只需要临时创建一个新的桶,并且把指针指向这个桶。
优点:简单常用,无需预先为元素分配内存。
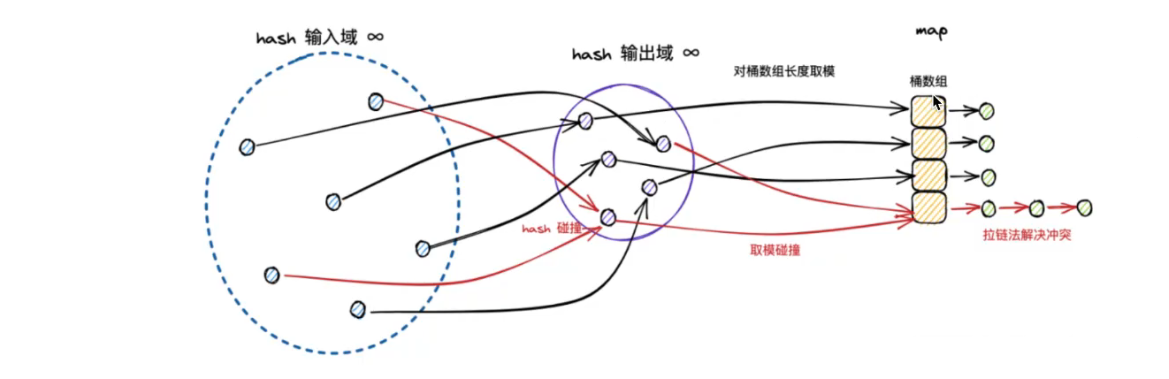
开放寻址法
首先明确一个节点只能存放一条数据,在插入新条目时,会基于一定的探测策略持续寻找空位(例如按数组的索引大小,从小到大查找空位),直到找到一个可用于存放数据的空位为止。
优点:无需额外的指针用于链接元素;需要一次性申请多个数组元素,内存地址完全连续,可以基于局部性原理(相邻内存的数据,cpu 会先缓存起来备用),充分利用 cpu 的高速缓存。
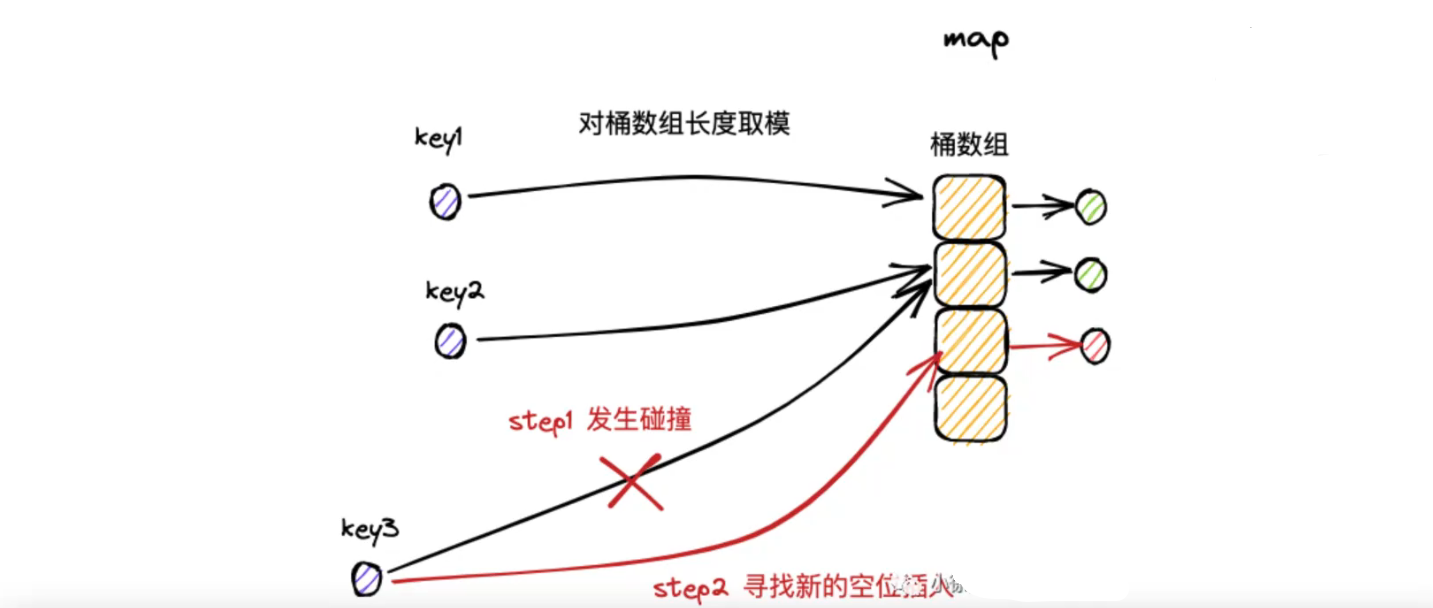
在 map 解决 hash 冲突的时候,实际结合了拉链法和开放寻址法两个思路,充分利用他们的优势。以 map 的插入写流程为例:
- 桶数组中的每个桶,严格意义上是个单向桶链表,以桶为节点进行串联;
- 每个桶可以固定存放 8 个 key-value 对(内存的连续的)
- 当 key 命中一个桶的时候,首先根据开放寻址法,在桶的 8 个位置寻找空位进行插入
- 如果桶的 8 个位置都占满了,则基于桶的溢出同指针,找到下一个桶,重复 3 步骤
- 如果遍历到链表尾部,仍未找到空位,则基于拉链法,在桶链表尾部续接新桶,并插入 key-value 对
go map 的数据结构
goland 中的 map,有自己的一套实现原理,其核心是由 hmap 和 bmap 两个结构体实现,其基础结构如下:
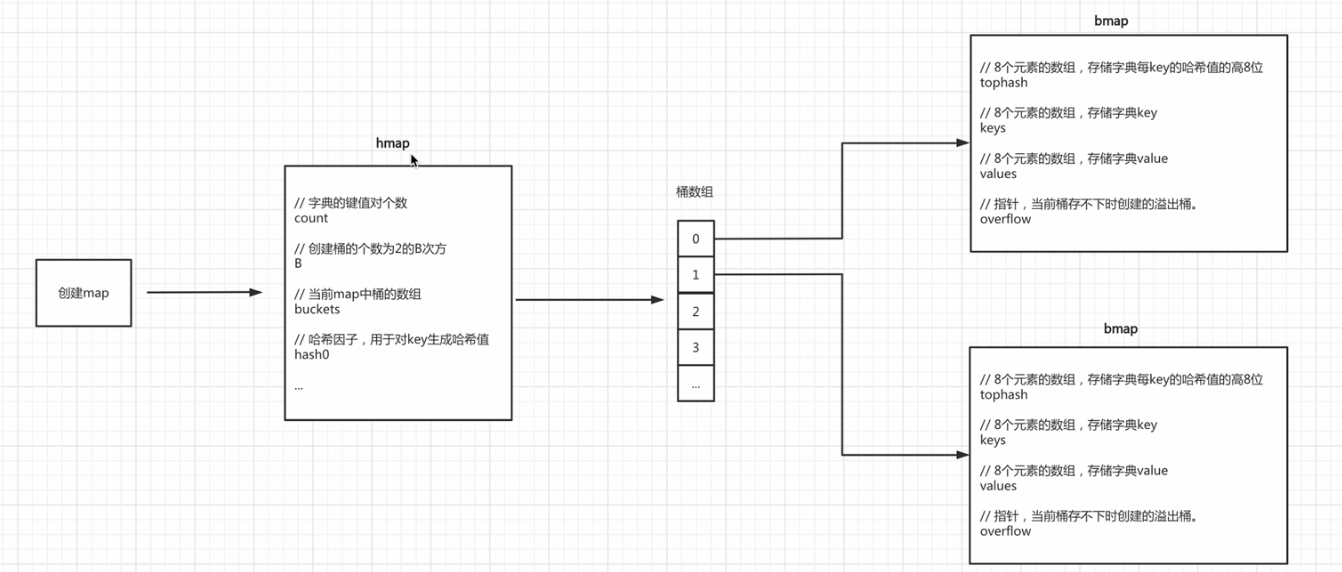
当我们在程序中创建一个 map 时候,底层都会初始化 hmap 结构体对象。在 hmap 中:
- count 成员变量:用于统计键值对的个数,如果增加键值对,这个就会加 1,通过 len 获取键值对个数的时候,实际上就是获取这个属性的值。
- hash0 成员变量:是用于将键生成哈希值用的,通过 hash 函数将 map 的 key 转成哈希值的时候,需要传入这个哈希因子。
- buckets 成员变量数组:用于存放 bmap 的数组,buckets 数组中的每个元素就是 bmap 对象。hmap 结构体对象存的是 map 的基础信息,实际上的键值对是存在一些 bmap 中,而每个 bmap 可以存储 8 个键值对,hmap 负责统管 bmap。
- B 成员变量:规定我们到底要创建多少个 bmap(桶),我们一般称作 bmap 为桶,不然有点乱。
初始化
如下所示,初始化一个可以容纳 10 个元素的的 map
info = make(map[string]string, 10)底层逻辑是:
- 第一步:初始化一个 hmap 结构体对象
- 第二步:生成一个哈希因子 hash0,并赋值到 hmap 对象中,用于后续为 key 创建哈希值
- 第三步:获取传入的参数 hint=10,并且根据算法规则设置 B,当前 B 应该为 1。buckets 桶的数量,等于 $2^B$ ,如果 B=1,则 buckets 的数量等 2
hint B buckets
0~8 0 2的0次方为1,创建1个桶,每个桶里可以存8个键值对
9~13 1 2的1次方为2,创建2个桶,可以存18个键值对
14~26 2 2的2次方,为4,创建就4个桶,可以存32个键值对
....- 第四步:根据 B 去创建桶(bmap 对象),并且放在 buckets 数组中,当前 bmap 的数量应为 2
- 当 B<4 时候,根据 B 创建桶的个数的规则为:$2^B$ (标准桶)
- 当 B>=4 的时候,根据 B 创建桶的个数的规则为:$2^B$ + $2^{B-4}$ (标准桶+溢出桶),预先创建好溢出桶备用
注意:每个 bmap 中可以存放 8 个键值对,当不够存放的时候,需要使用溢出桶,并且将当前 bmap 中的 overflow 字段指向溢出桶的位置。溢出桶也是一个 bmap 对象,也会有 overflow 字段,如果不够的话,还是再指向另外一个溢出桶。
写入数据
如下所示,我们设置了一个键值对:
info["name"] = "厦门"在 map 中写入数据时候,内部的执行流程是:
- 第一步:结合哈希因子和键 name 生成哈希值,例如
0110111100011111110111011011 - 第二步:获取哈希值的后 B 位,假如 B 是 1,那么
0110111100011111110111011011的最后一位是 1,并根据后 B 位的值,来决定将此键值对存放到哪个桶中(bmap)。此例中,最后 1 位的值是 1,所以桶的索引值是 1。 - 第三步:在上步确认哪个桶之后,接下来就是往该桶中写入数据。
- 然后将 hash 值的高 8 位添加到 bmap 中的 tophash 数组中,高八位值是
0110111,比较的时候会先比较高 8 位。 - 把 key 添加到 bmap 中的 keys 数组中
- 把值 value 添加到 bmap 的 values 数组中。
- 如果桶已满,则通过 overflow 找出溢出桶,并在溢出桶中继续写入。以后再桶中查找数据,会基于 tophash 来找,tophash 可能相同,如果 tophash 相同,则再去比较 key,如果 tophash 不相同,可以直接定位 tophash 数组的索引位置,然后根据这个索引位置直接去 keys 和 values 里拿值。
- 然后将 hash 值的高 8 位添加到 bmap 中的 tophash 数组中,高八位值是
- 第四步:hmap 的个数 count++(map 中的元素个数+1)
读取数据
下例中,读取 map:
value := info["name"]在 map 中读取数据时候,内部的执行流程是:
- 第一步:结合 hash 因子,把键
name生成哈希值,例如0110111100011111110111011011 - 第二步:然后去定位到桶,根据哈希值的
后B位,并根据后 B 位的值来决定将此键值对存放到那个桶中(bmap) - 第三步:确定桶后:
- 再根据 key 的 hash 值计算出 tophash(hash 值的高 8 位)
- 然后去 bmap 中的 tophash 成员变量数组中找到。如果则记住它的位置,然后根据这个位置,去 keys 和 values 数组中找到对应的值。如果当前桶中没有找到,则根据 overflow,再去溢出桶中找,均未找到,则表示 key 不存在
扩容
map 中扩容机制包括:等量扩容和翻倍扩容
- 翻倍扩容:当 map 中数据的
总个数/桶个数>6.5, 引发翻倍扩容,也就是桶的数量是原来的两倍 - 等量扩容:使用了太多的溢出桶时(溢出桶使用的太多会导致 map 处理速度降低,需要等量扩容解决这个问题),也就是 bmap 中有溢出桶,溢出桶中又有溢出桶,也会引发扩容
- B<=15, 溢出桶个数>= $2^B$ 时,引发等量扩容(等量扩容桶的数量和原来一样)
- B>15,溢出桶个数>= $2^{15}$ 时,引发等量扩容
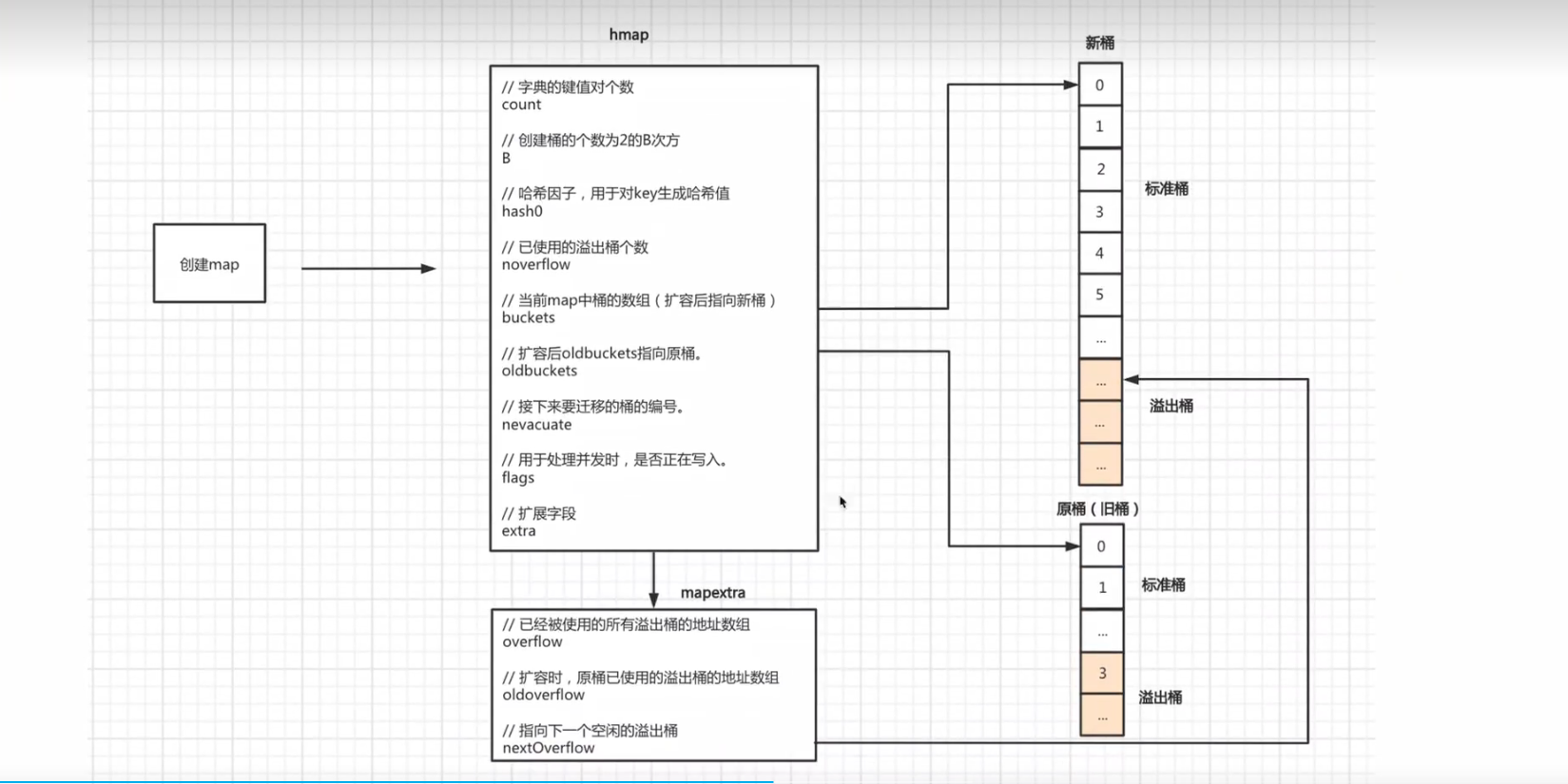
当触发扩容后:
- 第一步:增加 B(翻倍扩容,
新 B=旧 B+1,等量扩容,新 B=旧 B),然后创新新桶,数量是 $2^B$ - 第二步:oldbuckets 成员变量,指向原来的桶(旧桶),旧桶存原来的数据
- 第三步:buckets 成员变量,指向新创建的桶,新通中暂时还没有数据,后期还是需要将旧通道数据迁移到新桶
- 第四步:nevacuate 成员变量,设置为 0,表示如果数据迁移的话,应该从原桶(旧桶)的第 0 个位置开始迁移,这个主要用于将旧桶的数据迁移到新桶,如果是 0 表示把 0 号桶的数据迁移过去,然后 1 号桶数据一个个的去迁移
- 第五步:noverflow 成员变量,设置为 0,扩容后新桶中已使用的溢出桶为 0
- 第六步:extra 成员变量,是另外一个结构体,
extra. oldoverflow设置为原桶(旧桶)已使用的所有溢出桶,即:h.extra. oldoverflow=h.extra. overflow - 第七步:
extra. overflow设置为 nil,因为新桶中还未使用溢出桶,表示的是已经使用的所有的溢出桶的地址数组 - 第八步:
extra.nextOverflow设置为新创建的桶中的第一个溢出桶位置,由原来指向旧桶的溢出桶位置,来指向新桶的溢出桶位置
需要注意的是,扩容后数据还没迁移,还在旧的桶中
迁移
迁移就是将旧桶的数据迁移到新桶中,但是翻倍扩容和等量扩容,他们的迁移机制有所不一样。
迁移策略是什么?
迁移的时候不是一次性迁移,而是通过渐进式迁移的方式进行。每次操作某个桶的时候,就把那个桶的数据迁移到新的桶,这样可以防止性能抖动
翻倍扩容
如果是翻倍扩容,那么迁移规则就是将旧桶中的数据分流到新的两个桶中(比例不定),并且桶的编号的位置为:同编号位置和翻倍后对应编号的位置
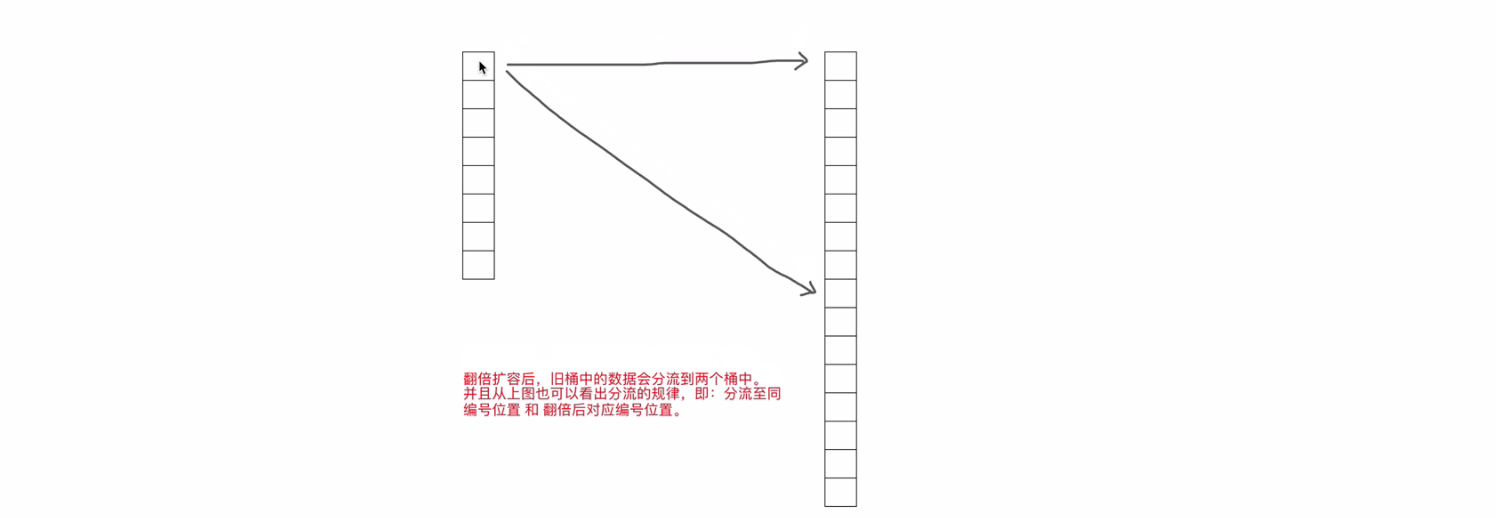
那么问题来了,如何实现这种迁移的呢?
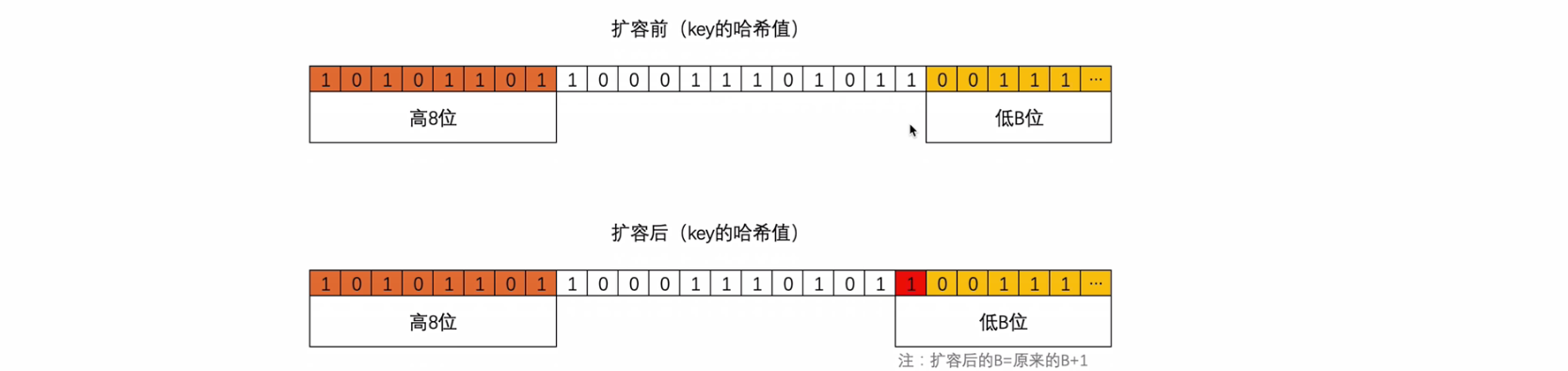
首先,我们要知道如果翻倍扩容后,则新桶个数是旧的的 2 倍,即:map 中的 b 的值要+1。
迁移时候,会遍历某个旧桶中所有的可以,包括溢出桶,并且根据 key 重新生成 hash 值,这个 hash 值和原来一样,根据哈希值的后 b 位,来决定分流到那个新桶中
等量扩容
如果是等量扩容,溢出桶太多引发的扩容,那么数据迁移机制就会比较简单,就是将旧桶(含溢出桶)中的值迁移到新通中。这种扩容和迁移的意义在于:当溢出桶比较多,而每个桶中的数据又不多时(比如被删除,空缺处位置 ),就可以通过等量扩容和迁移,让数据更紧凑,从而减少溢出桶。
map 基本操作
声明
通过 var 关键字进行定义,因为只是定义,没有散列表的引用,所以零值是 nil。
var m map[string]int
if m == nil {
fmt.Println("nil")
}大多数 map 操作都可以在零值 nil 上进行,不会报错,这个行为和空 map (m:=map[string]int{})是一样的,包括:
- 查找元素
- 删除元素
- 获取 map 元素的个数
- range 循环
// 对nil的map进行操作
func main() {
var m map[string]int
if m == nil {
fmt.Println("nil")
}
// 1. 查找元素
fmt.Println(m["name"]) // 0,零值
// 2. 删除元素
delete(m, "age") // 不会报错
// 3. 获取元素的个数
fmt.Println(len(m)) // 0
// 4.range循环
for key, val := range m {
// 进入不了循环体
fmt.Println(key, val)
}
}但是,不能往零值 map 中设置元素,会导致错误
var m map[string]int
m["test"] = 1map 只是声明的话,是 nil,不能对某个 key 进行赋值,那么这样声明有什么用呢?
这个一般用于整体赋值
var row map[string]int
data := map[string]int{
"age":18,
}
// 整体赋值是允许的
row = data初始化
字面量方式
字面量形式的初始化,是在类型后面加 {}
// 完整的声明赋值
var m map[string]string = map[string]string{
"user_name": "张三",
"age": "12",
}
// 类型推导
var b = map[string]string{
"user_name": "张三",
"age": "12",
}
// 简写
userInfo := map[string]string{
"username": "沙河小王子",
"password": "123456",
}
fmt.Println(userInfo)
// 也可以初始化空内容
userInfo := map[string]string{}make 函数方式
通过 make 函数定义的 map,会在内存中初始化零值。格式如下所示:
var m = make(map[KeyType]ValueType, [cap])示例:
scoreMap := make(map[string]int, 8)
fmt.Println(scoreMap == nil) // false关于 cap 参数的理解
cap 容量可以理解为创建了多少位置用于存键值对。
如果 cap 是 10,map 的内部会根据参数 10,计算出合适的容量。一个 map 中会包含很多个桶,每个桶可以存 8 个键值对。那么参数 10,就可以 2 个桶,16 个键值对,实际上有一个公式计算这个桶的数量,会比较复杂。
总而言之,我们可以这么理解,参数 10,表示至少预留了 10 个键值对,实际上会比这个多。
cap 参数注意:
- Cap 表示 map 的容量,并不是必须的要传的,底层会根据一定的算法自动扩容。
- 可以设置一个合适的 cap,避免频繁的申请内存,从而提高运行的效率
- cap 如果设置为 1,并不是说只能添加一个元素,底层会自动扩容
new 函数方式
还有一种是可以通过 new 一个 map,这种也只能整体赋值,例如
value := new(map[string]int)
data := map[string]int{
"age":18,
}
value = &data增删改查
对 map 进行写的时候,需要注意的是,必须要初始化,不然会导致 panic 异常。
添加
给不存在的 key 赋值就是增加
data := map[string]string{}
// age的key不存在,就是增加
data["age"] = 18删除
使用 delete 函数删除,如果 key 不存在或者没有初始化,都不会报错
data := map[string]string{"age":18}
delete(data,"age")改
给已经存在的 key 赋值就修改
data := map[string]string{"age":18}
// age的key存在,就是修改
data["age"] = 19查
第一种方式:
直接读,如果 key 存在,则获取对应的 value,如果 key 不存在,或者 map 为初始化,会返回 value 的零值兜底
data := map[string]string{"age":18}
val := data["age"]第二种方式:
读的同时,添加一个 bool 类型的 flag,标识读取是否成功。如果 ok== false,说明读取失败,key 不存在,所在 map 未初始化。
所以通过这个方式,可以判断 key 是否存在。
data := map[string]string{"age":18}
val,ok := data["age"]获取长度
获取 map 的长度
data := map[string]int{
"age":18,
}
val := len(data) // 1可以通过 cap 函数,获取 map 的容量吗?
当使用 cap 去获取 map 的容量时候,会报错,因为容量是要重新计算的,所以获取掉参数 10 也没什么意义。
info := make(map[string]string,10)
info["xm"] = "厦门"
v1 := len(info) // 长度为1
v2 := cap(info) // 报错map 嵌套
map 的键必须是可以哈希的(int/bool/float/string/array),例如
v1 := make(map[[2]int]float32)
v1[[2]int{1,1}] = 1.6
v1[[2]int{1,2}] = 1.8如果说键是数组,但是数组里又是 map,或者切片,这种是不允许的,因为这种是不能 hash
// 报错,key是切片数组
v := make(map[[2][]int]string)
// 报错,key是map数组
v := make(make[[2]map[string]string]string)map 的键是必须可 hash,但是值是可以任意类型,所以值可以无限嵌套,例如
// 值是基本的int类型
var v1 map[string]int
// 值是切片
var v2 map[string][]int
// 值是map
var v3 map[string]map[int]int
// 值是一个map[string]string类型的数组
var v4 map[string][2]map[string]string变量赋值
go map 赋值,在内存中是同一个地址
v1 := map[string]string{"n1":"厦门","n2":"福州"}
v2 := v1
v1["n1"] = "xiamen"
fmt.Println(v1)//{"n1":"xiamen","n2":"福州"}
fmt.Println(v2)// {"n1":"xiamen","n2":"福州"}特别提醒:无论是否存在扩容,都指向同一个地址。这点和切片不一样,切片如果扩容之后,不再指向同一个地址
遍历
可以使用 for range 对 map 进行遍历。
m := map[string]int{
"zhangSang": 20,
"liSi": 20,
}
for i, v := range m {
fmt.Println(i, v)
}
// 只有一个参数key的话,默认只会拿到键
for key := range m {
fmt.Println(key)
}
// 只拿值
for _,val := range m {
fmt.Println(val)
}需要注意的是,这个迭代顺序不是固定的,第一次可能 zhangsang 在前面,第二次可能就 liSi 在上面了,是随机的,这样不用对 key 进行排序,速度会比较快。
可以对 map 的元素获取地址吗?
由于 map 的元素不是一个变量,不可以对其获取地址,随着元素的增长,它可能会被重新散列到新的存储位置,这样使得获取到的地址无效
m := map[string]int{
"a": 1,
}
fmt.Println(&m["a"]) // 会报错Map 排序
Map 本身是无序的,可以通过切片来排序
var scoreMap = make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i) //生成stu开头的字符串
value := rand.Intn(100) //生成0~99的随机整数
scoreMap[key] = value
}
//取出map中的所有key存入切片keys
var keys = make([]string, 0, 200)
for key := range scoreMap {
keys = append(keys, key)
}
//对切片进行排序
sort.Strings(keys)
//按照排序后的key遍历map
for _, key := range keys {
fmt.Println(key, scoreMap[key])
}比较
和 silce 类型一样,map 类型不能比较,唯一可以比较的是和 nil 进行比较。如果非要比较,可以嵌套变量,每个元素进行比较过去。
并发不安全
map 不是一个并发安全的数据结构,如果一个 map 变量,有多个 goroutine 对齐进行并发读写的话,会抛出 fatal error 错误,这个错误是没法 recover 捕获的,直接杀死进程。
具体规则是:
- 并发读没有问题
- 读的时候,发现有其它 goroutine 在并发的
增删改,抛出 fatal error 增删改的时候,发现有其它的 gooutine 也在并发的增删改,抛出 fatal error
