搜索到
35
篇与
的结果
-
 MySQL在Update或Delete中如何处理In子查询ID的问题 不能在在同一语句中,先select出同一表中的id,再使用where in 语句 update、delete这个表的数据,否则会报You can't specify target table for update in FROM clause的错误。 下例子考虑到更加简单和说服力,已经由原文改为自己的例子了: UPDATE erp_user SET STATUS = 1 WHERE -- 如果查询条件的表是要更新的那张表的话,如这个例子,这样就会遇到这个问题; -- 否则,如果查询条件的表不是要更新的那张表的话,就不会遇到这个问题; id IN ( SELECT id FROM erp_user WHERE STATUS = 2 ); 改写成下面就行了: UPDATE erp_user SET STATUS = 1 WHERE id IN ( SELECT u.id AS id FROM ( SELECT id FROM erp_user WHERE STATUS = 2 ) u ) AND id = 0; 也就是说将select出的结果再通过中间表select一遍,这样就规避了错误。注意,这个问题只出现于mysql,mssql和oracle不会出现此问题
MySQL在Update或Delete中如何处理In子查询ID的问题 不能在在同一语句中,先select出同一表中的id,再使用where in 语句 update、delete这个表的数据,否则会报You can't specify target table for update in FROM clause的错误。 下例子考虑到更加简单和说服力,已经由原文改为自己的例子了: UPDATE erp_user SET STATUS = 1 WHERE -- 如果查询条件的表是要更新的那张表的话,如这个例子,这样就会遇到这个问题; -- 否则,如果查询条件的表不是要更新的那张表的话,就不会遇到这个问题; id IN ( SELECT id FROM erp_user WHERE STATUS = 2 ); 改写成下面就行了: UPDATE erp_user SET STATUS = 1 WHERE id IN ( SELECT u.id AS id FROM ( SELECT id FROM erp_user WHERE STATUS = 2 ) u ) AND id = 0; 也就是说将select出的结果再通过中间表select一遍,这样就规避了错误。注意,这个问题只出现于mysql,mssql和oracle不会出现此问题 -
MySQL 如何区分大小写 - 教程及技术指南 mysql的字符串字段默认是不区分大小写的,例如下例中的网驰 GeForce RTX 2060 电竞 v2的v是小写,确搜索出了大写的结果: 为了解决这个问题,我们只需要先查询出来,然后再比较下即可,因为php是区分大小的,例如 $pn = "网驰 GeForce RTX 2060 电竞 v2"; $materialModel = ErpFacade::callRepository([Erp::C_MATERIAL, 'MaterialRepository@findByPn'], [$pn]); if (!$materialModel || $materialModel->pn != $pn) {// 利用php比较 throw new ActionException('操作失败,物料不存在'); }
-
MySQL用户和权限管理专家 用户管理 mysql验证密码需要验证3个维度:用户名、密码、ip。当3个维度存在不正确的时候,会提示access denied。 mysql的用户表是在mysql数据库下的user表,最好不要直接去修改该表。 创建用户 mysql5.6和5.7都可以这样创建用户,创建完之后就可以用这个用户进行连接了 -- 所有的网都可以访问 create user 'david'@'%' identified by '03203511'; -- 内网段可以访问 create user 'david'@'192.168.1.%' identified by '03203511'; -- 没有identified代表是空的密码 create user 'david'@'192.168.1.%'; 默认创建的用户,只有连接的权限,创建用户就会有连接权限,这个是最小的权限吧 show grants for 'test'@'%'; -- GRANT USAGE ON *.* TO 'test'@'%',这个usage,代表连接的权限 删除用户 5.6和5.7都可以这样删除用户 drop user 'david'@'%'; 执行这个语句之后,只有针对新的连接有效,已经连接的不会退出 修改密码 mysql5.7修改密码,该条语句对于mysql5.6无效 alter user 'test'@'%' identified by '03203512'; mysql5.6 版本使用这个修改密码 SET PASSWORD FOR 'david'@'%' = PASSWORD('mypass'); 权限管理 增加权限 授予所有的权限 grant all on *.* to 'root'@'%'; 授予增删改查的权限 -- 给test库,test用户授予权限 -- create 创建表 -- index 创建索引的权限 grant select,update,insert,delete,create,index on test.* to 'test'@'%'; 设置权限的时候,顺道创建用户,了解即可,不推荐这样,最好的做法是,先创建,然后授权 grant select,update,insert,delete on test.* to 'test1'@'%' identified by '03203511'; 分享自己已有的权限给别人,自己没有的权限不可以分享,了解即可 grant select,update,insert,delete,create,index on test.* to 'test'@'%' with grant option; 删除权限 -- 收回create,index权限 revoke create,index on test.* from 'test'@'%'; -- 回收所有的权限,只剩下usage的登录权限 revoke all on test.* from 'test'@'%'; 限制资源 使用的场景不多,了解即可 max_user_connections,限制该用户同时进行多少个连接 -- test账号,最多只能有一个在线 alter user 'test'@'%' with max_user_connections 1; max_connections_per_hour:限制一个小时最多能够连接的次数 alter user 'test'@'%' with max_connections_per_hour 1; max_updates_per_hour:限制每小时最多能够执行update是次数 alter user 'test'@'%' with max_updates_per_hour 1; max_querys_per_hour:限制每小时最多能够查询的次数 alter user 'test'@'%' with max_queries_per_hour 1;
-
优化MySQL连接 - 快速、稳定、安全 连接MySQL操作是一个连接进程和MySQL数据库实例进行通信。从程序设计的角度来说,本质上是进程通信。如果对进程通信比较了解,可以知道常用的进程通信方式有管道、命名管道、命名字、TCP/IP套接字、UNIX域套接字。MySQL数据库提供的连接方式从本质上看都是上述提及的进程通信方式。 TCP/IP 连接 TCP/IP套接字方式是MySQL数据库在任何平台下都提供的连接方式,也是网络中使用得最多的一种方式。这种方式在TCP/IP连接上建立一个基于网络的连接请求,一 般情况下客户端(client)在一台服务器上,而MySQL实例(server)在另一台服务器上,这两台机器通过一个TCP/IP网络连接。例如用户可以在Windows服务器下请求一台远程Linux服务器下的MySQL实例,如下所示: mysql -h 127.0.0.1 -P 3306 -u root -p 这里需要注意的是,在通过TCP/IP连接到MySQL实例时,MySQL数据库会先检查user表,用来判断发起请求的客户端IP是否允许连接到MySQL实例。 使用ssl加密传输 {message type="warning" content="这部分都是基于5.7版本的实操,如果是5.6的话,估计要有点不大一样,ssl连接主要针对tcp/ip这种远程连接用的"/} 使用ssl连接,可能会对连接性能有点影响,不是非常机密的数据,不使用ssl问题也不大。 首先,我们看下我们的服务器是否支持ssl连接 show variables like '%ssl%'; 如果不支持,可以参考mysql安装的时候,ssl安装步骤:https://www.xiaoqiuyinboke.cn/archives/104.html,安装完重启即可 然后修改强制用户必须使用ssl进行连接 alter user 'test'@'%' require x509; 然后下载数据库目录下的client*.pem给客户端 # 这三个文件 client-cert.pem client-key.pem ca.pem UNIX域套接字 连接 在Linux和UNIX环境下,还可以使用UNIX域套接字。UNIX域套接字其实不是一个网络协议,所以只能在MySQL客户端和数据库实例在一台服务器上的情况下使用。用户可以在配置文件中指定套接字文件的路径,如--socket=/tmp/mysql.sock。当数据库实例启动后,用户可以通过下列命令来进行UNIX域套接字文件的查找: SHOW variables LIKE 'socket'; 在知道了UNX域套接字文件的路径后,就可以使用该方式进行连接了,-hlocalhost,就代表是用socket的方式进行连接: mysql -uroot -S /tmp/mysql.socket1 # 等效 mysql -hlocalhost -uroot -S /tmp/mysql.socket1 如果省略-h参数的话默认就是localhost,所以可以简写 mysql -uroot -S /tmp/mysql.socket1 -S /tmp/mysql.sock参数也可以可以省略,默认是/tmp/mysql.sock,如果sock文件是这个的话,可以简写。 mysql -uroot 一般只有在mysql服务器上,使用mysql客户端进行连接的时候才会使用这种方式,然而客户端和mysql在同一台服务器上的概率是很低的,所以用到的场景不多。
-
MySQL常用函数详解与实例教程 字符串函数 replace replace(s,s1,s2),替换函数,用s2替换s中的s1,例如: -- 结果是1bc SELECT REPLACE("abc","a","1"); group_concat group_concat(要连接的字段),mysql在group by某个字段时候,其列的字段也只被保存一个值,有时候希望其它列的字段,全部被保留,就可以用这个函数,例如 -- 是用英文的,分割 SELECT GROUP_CONCAT(id) FROM o2o_admin_info WHERE id < 100 GROUP BY status ; 需要注意的是,group_concat的最大长度是1024,超过的这个长度的会丢失,可以修改配置文件,来修改这个长度 [mysqld] group_concat_max_len = 102400 concat concat(str1,str2,...) ,将多个字符串连接成一个字符串 concat_ws concat_ws('分隔符',str1,str2) 第一个参数为分隔符,相比于concat函数可以一次性指定分隔符,例如 -- a、b、c用逗号隔开,结果:a,b,c SELECT CONCAT_WS(",","a","b","c"); instr 函数instr(filed,str),作用是返回str子字符串在filed字符串的第一次出现的位置。 -- 返回2,位置是从1开始 SELECT INSTR("abc",'b'); 当instr(filed,str)=0时,表示子符串str不存在于字符串filed中,因此可以用来实现mysql中的模糊查询,与like用法类似。如下: instr(filed,str) > 0 ⇒ file like '%str%' instr(filed,str) = 1 ⇒ file like 'str%' instr(filed,str) = 0 ⇒ file not like '%str%' find_in_set 有时候数据库字段的值是用英文,分开的结构,如果想要查找包含某个值的,就需要用到这个函数,例如: -- 查收sub_menu_id字段中,包含1的这个值的数据 SELECT * FROM o2o_admin_role_purview WHERE FIND_IN_SET(1,sub_menu_id); 控制流函数 if IF(true,a,b),如果为真,则返回a,否则,返回b,例如: -- 返回0<1 SELECT IF(0>1,'0>1','0<1'); ifnull ifnull(expression1,expression2),如果expression1不为null,则返回expression1,否则返回expression2,例如 -- 类似php的null合并运算符: null??'不是null',返回'不是null' SELECT IFNULL(null,'不是null'); case语句 字段相对比较,这种语法只能比较是否相等,例如: select case order_type when 1 then 'RMA单' when 2 then '维修入库单' when 3 then '维修出库单' else '类型不正确' end as 订单类型 from erp_storage_flow_log where id < 100; 字段比较,不仅仅可以比较是否相等 select case when order_type < 2 then '维修入库单' when order_type >= 3 then '维修出库单' else '类型不正确' end as 订单类型 from erp_storage_flow_log where id < 100; 日期时间函数 from_unixtime 可以把时间戳格式化成日期格式 -- 返回2022-08-18 11:48:08 SELECT FROM_UNIXTIME(1660794488); NOW() 命令用于显示当前年份,月份,日期,小时,分钟和秒。如:2022-10-28 14:39:05 CURRENT_DATE() 仅显示当前年份,月份和日期。如:2022-10-28 拓展 http://c.biancheng.net/mysql/function/
-
详细解读MySQL bin目录中的可执行文件 bin/mysqldump 这个是个二进制可执行文件,用于导出数据,默认导出时候会锁定数据库的所有表,加上--lock-tables=false 参数避免锁定表,加上--lock-tables=false 参数。 导出数据库 导出表结构和数据 # -h 主机链接 # -p 密码,交互式输入密码,不可以在这个参数后面加密码 # -B或者--databases,代表导出指定数据库 mysqldump -h localhost -u root -p -B 数据库名 > c:/a.sql 只导出数据库表结构 # -d或者--no-data,参数代表只导出表结构No row information. mysqldump -h localhost -u root -p -d -B 数据库名 > c:/a.sql 导出表 表结构和数据 mysqldump -h localhost -u root -p --B 数据库名 --tables 表名 > c:/a.sql 只包含表结构 # --tables指定导出的表 mysqldump -h localhost -u root -p -d --database 数据库名 --tables 表名 > c:/a.sql bin/mysqld mysqld是一个二进制文件,用于启动mysql的服务,通过以下命令可以查看文件的类型 # 这个命令可以查看文件类型 file mysqld 查看mysql的帮助信息 # 只能这样输入,--help --verbose两个参数必须一起用 ./mysqld --help --verbose mysqld命令还可以用于初始化mysql5.7的数据库,详情见:https://www.xiaoqiuyinboke.cn/archives/104.html 这个二进制文件,最核心的功能是用于启动mysql服务,但是这种方式启动的mysqld,没有守护进程管理mysqld进程 # 默认好像就是用到/etc/my.cnf这个文件 mysqld --defaults-file=/etc/my.cnf # 后台的方式启动 mysqld --defaults-file=/etc/my.cnf & bin/mysqlAdmin 这是一个二进制文件,通过这个脚本,可以不登录mysql客户端,就可以执行sql语句,例如执行shutdown语句来关闭mysqld,和登录mysql客户端后执行shutdown;关闭msqld是等效的,通常是用于shell脚本中执行sql语句时候 ./mysqladmin -uroot -p03203511 -S /tmp/mysql.sock1 shutdown 我们还可以通过kill命令来直接关闭mysql,执行kill mysqld的进程id,mysql会接收到这个信号,来处理一些关闭逻辑,是安全的关闭。但是需要注意的是,不可以执行kill -9 mysqld的进程id来关闭,mysql会被直接关闭,这样是不安全的。 bin/mysqld_safe 是一个shell脚本,mysql官方使用这个命令启动,这个脚本,5.6和5.7是通用的,也就是5.7的mysqld_safe可以启动mysqld5.6、mysqld8。通过这种方式启动mysqld,会生成一个守护进程和mysqld进程,守护进程,如果发现mysqld进程没有里,会立马创建一个新的。通常使用这种方式启动,因为我们希望mysqld被down了之后,会自动起来 ./mysqld_safe --user=mysql # 执行后,会有两个进程 ./mysqld_safe --user=mysql 守护进程,如果发现mysqld进程没有里,会立马创建一个新的 /usr/local/mysql/bin/mysqld 进程 bin/mysql 这个是个二进制的MySQL客户端连接文件,用于登录mysql。 查看帮助信息 ./mysql --help # 或者 ./mysql --help --verbose 连接数据库,可以配置不用输入密码,见配置文件 # -h主机地址,可以省略 # -P端口,可以省略 # -u用户 # -p密码,后面不需要跟任何东西,交互式输入 ./mysql -h localhost -P3306 -uroot -p # 有密码的最少参数 ./mysql -uroot -p # 不需要输入密码的,直接执行就可以了 ./mysql 还可有通过这个脚本查看mysql加载的配置文件顺序 # 输出/etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf mysql --help | grep my.cnf
-
MySQL性能优化与参数设置指南 参数设置的三种方式 set [session] set [session] 参数名=参数值,设置当前会话(连接)参数,范围最小,当这个连接被关闭了之后,会话会自动失效。其中,session关键字可以省略,默认就是session级别。 这个设置的优先级比set global还高。 set global set global 参数名=参数值,设置全局参数,只要mysql没有关闭重启,就一直生效,但是需要注意的是:部分参数需要并不会立即生效,需要重新建立连接才会生效。 这个命令设置的优先级会比配置文件里的配置高,如果配置文件里max_connections = 100,但是执行了SET GLOBAL max_connections = 200;那么,实际使用的会被改成200. 设置应用配置文件 对于一些关键性的参数,我们会在配置文件里配置,window和linux虽然文件名称不一样,但是配置内容是一样的 Window存放到将my.ini应用程序根目录 Linux保存在/etc/my.cnf 配置内容如下所示,因为我们配置一般都是针对服务端配置,所以要写在[mysqld]底下: [mysqld] port = 3306 # 最大连接数,如果没有书写的情况下,默认是151 max_connections = 100 connection连接参数 因为数据库连接是客户端和服务端的通信管道,所以设置的是否合理,对我们整应用程序就至关重要了 max_connections 代表mysql数据允许的最大连接数。mysql连接有两种常见的状态: sleep,代表出于闲置,等待的状态 query,代表正在工作状态 着两个状态的总数量和不能超过max_connections设置的值的,否则会出现"ERROR 1040:Too many connetcions"的错误提示。可以用以下sql查看连接状态: SHOW status LIKE 'Threads%'; Threads_connected,代表当前已经有多少连接,包括sleep和query状态的连接 Threads_created,代表从服务启动,到现在为止,历史总共创建过多少个数据库连接,包括打开的,正在工作的,和已经销毁的等,这个数量不知道为啥比想象的小 Threads_running,代表当前有几个连接出于工作的状态,这个数值其实就是我们系统的并发数了 Threads_cached,代表共缓存过多少连接,如果我们设置了thread_cache_size,当客户端断开之后,连接不会销毁,给其它客户端复用,因为频繁的创建销毁太消耗资源,而是缓存起来,不够如果数量超出设置的缓存上限后,还是会销毁。 那么这个连接数设置多大才是最合适的呢,可以用以下命令来查看: SHOW status LIKE 'Threads%'; Max_used_connections,历史出现的最大连接数,通常这个数值上涨20%左右,就可以作为最大连接数,刚上线的时候,不知道最大的连接数,可先设置的大一些,比如3000,或者5000等,等后续运行一段时间后,在调整为合适的值。但是如果有秒杀等活动的时候,要调整的高一些。 Max_used_connections_time,出现这个最大连接数的时间 back_log 设置保存多少数据库请求到堆栈(缓冲区)中。也就是说,如果mysql的连接数达到max_connections时,新的请求不会被直接拒绝,而是存在缓存中,以等待某一连接释放资源后,就从堆栈中把最顶层的请求拿出来执行。只有缓存的请求,超过了back_log设置的数量之后,将拒绝连接,报错:"unauthenticated user | XXX .XXX.XXX.XXX | NULL | Connect | NULL | login | NULL 的待连接进程." -- 默认值是80,可以适当的调高,比如3000 SHOW variables LIKE 'back_log'; 连接时间 wait_timeout和interactive_timeout参数,这两个连接都是设置数据库连接超过一段时间后,连接自动关闭,默认的28800秒是8个小时,线上可以调整3600。 wait_timeout,代表是交互式连接,也就是mysql客户端连接数据库的都叫交互式连接,这就是很多客户端需要心跳包重新连接 interactive_timeout,代表是非交互式连接,通过jdbc等连接的都是非交互式连接 以下sql可以查看设置的连接时间 SHOW variables LIKE 'wait_timeout'; SHOW variables LIKE 'interactive_timeout'; 我们还可可以通过以下sql,查看连接的时间 SHOW processlist; 其中time列连接的时间,当这个值超过设置的连接时间值的时候,就会被自动的关闭。不过现在的应用一般都有连接池,连接池会对连接进行有效性检查,会自动重新连接,防止自动过期。 查询缓存相关 使用查询缓存,MySQL将查询结果存放在缓冲区中,今后对 同样的select语句(区分大小写) ,将直接从缓冲区中读取结果。 have_query_cache 若要查看MySQL服务器上的查询缓存是否已经打开,要在MySQL命令行界面执行以下命令,如果是YES表示启用查询缓存: SHOW VARIABLES LIKE 'have_query_cache'; 若要开启缓存,只需要配置以下几个参数即可: query_cache_type = 1 query_cache_size = 128MB query_cache_limit = 1M query_cache_size 表是缓存的大小,需要注意的是,最小缓存单位是1024byte,所以最好设置1024的整数倍数,如果不是将会被四舍五入。可以通过以下语句查看缓存的大小 SHOW variables LIKE '%query_cache_size%'; 如果要修改的话,可以执行 -- 单位是字节 SET GLOBAL query_cache_size = 16777216; 那如何知道,我们应该设置的大小呢,并不是越大越好,query_cache_size较合适的值是在100MB和200MB之间,我们对一个中等流量的Magento站点使用了128 MB的配置值,它工作得非常好。将这个值设置为0可以关闭查询缓存。 我们还可以通过以下sql来查看缓存状态来综合判断,这个需要不断的进行跟踪: SHOW status LIKE 'Qcache%'; Qcache_free_memory,query_cache中目前剩余内存的大小,通过这个参数,我们可较为准确的观察当前系统中query cached内存大小是否足够,看下是缓存大小设置的是否合适 Qcache_lowmem_prunes,多少条Query因为内存不足而被清除出Query Cache,通过Qcache_lowmem_prunes和Qcache_free_memory相互结合,能够更清楚的了解到我们系统中Quey Cache的内存大小是否真的足够,是否非常频繁的出现因为内存不足而有Query被换出。这个数字最好是长时间来看,如果这个数字在不断增长,就表示可能碎片化非常严重,或者内存很少。 Qcache_total_blocks,当前Query Cache中block的数量,每个sql语句都是以bloc块为单位进行保存,如果块数越多,这个数量就越大 Qcache_free_blocks,缓存中相邻内存块的个数。如果该值显示过大,则说明Query Cache中的内存碎片较多了,这部分内存无法被有效利用。如果碎片比较多的话,可以用flush query cache来清理。但是需要注意的是,mysql的块默认是4kb为单位,并且这个是最基础的单位,无法拆分,如果数据大小是2kb的话,那么就空闲出了2kb,也会导致内存浪费。 Qcache_hits,表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询能缓存的效果。数字越大缓存效果越理想。 Qcache_inserts,表示多少次未命中而插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行查询处理后把结果insert带查询缓存中。这样的情况次数越多,表示查询缓存应用到的比较少,效果也就不理想。 Qcache_queries_in_cache,当前缓存中缓存的查询数量 Qcache_not_cached,未进入查询缓存的select个数 query_cache_limit 超出此大小的查询将不被缓存,用于限制单个sql语句,所能被缓存的数据大小,如果查询结果的体积大于这个值,将不会被缓存。这个配置值可以通过找到最大的SELECT查询结果的体积而推测出来。,我们的缓存尽可能的去保存数据量小的,访问频发的sql SHOW variables LIKE 'query_cache_limit'; query_cache_type 缓存类型,决定缓存什么样子的查询,注意这个值不能随便设置,必须设置为数字,可选值以及说明如下: 0:OFF相当于禁用了 1:ON将缓存所有结果,除非你的select语句使用了SQL NO CACHE禁用了查询缓存 2:DENAND则只缓存select语句中通过SQL CACHE指定需要缓存的查询。 mysql5.7中,默认是禁用qc的,要启用的话,需要在配置文件中配置,不可以通过set gloabal命令来设置!!!。 -- 结果是off SHOW variables LIKE 'query_cache_type'; query_cache_min_res_unit 缓存块的最小大小,query_cache_min_res_unit的配置是一柄双刃剑,默认是4KB,设置值大对大数据查询有好处,但是如果你查询的都是小数据查询,就容易造成内存碎片和浪费。 排序优化 sort_buffer_size 为每个需要排序的线程分配该大小的一个缓冲区。增加这值加速ORDER BY或GROUP BY操作,如果是sql怎么调优化都没效果的话,可以试着调整这个缓存的大小。 sort_buffer_size是一个connection级的参数,在每个connection(session)第一次需要使用这个buffer的时候,一次性分配设置的内存。 sort_buffer_size并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统的内存资源。例如:500个连接将会消耗508*sort_buffer_size(2M)=1G,很耗内存。 innodb相关的 innodb_buffer_pool_size 缓存池的大小,对innodb表读写的时候,会利用这个缓存池,对数据进行缓存,从而使我们数据的输入和输出的效率提高。虽然这个也是在内存中占用空间,但是和前面的说的查询缓存qc不一样,查询缓存服务于所有的查询语句,和底层的数据库引擎无关,这个innodb_buffer_pool_size是专门用于优化innodb的io。 -- 默认是134217723=128M(默认值) SHOW GLOBAL variables LIKE "innodb_buffer_pool_size"; 但是,这个128M是否够用,可以参考以下三个指标: -- innodb已使用的缓存页数量,每页16k SHOW GLOBAL status LIKE "Innodb_buffer_pool_pages_data"; -- 总共为innodb分配的中页数,如果使用率高的话,可以增加innodb_buffer_pool_size SHOW GLOBAL status LIKE "Innodb_buffer_pool_pages_total"; -- innodb缓存的每个页的长度是多少 SHOW GLOBAL status LIKE "innodb_page_size"; 如果想要调整innodb_buffer_pool_size的大小,可以 set GLOBAL innodb_buffer_pool_size = xxx; 但是需要注意的是,这个会使内存使用大大的增加,io读写效率也会大大的提高。 innodb_flush_log_at_trx_commit 事务提交相关的,在事务控制中,存在"事务区"来保证事务完整性,当开启事务后,首先先把数据提交到事务区中,在事务提交以后,这些事务区的数据会写入到硬盘上,同时事务操作日志(1og)也需要向硬盘中写入。这个参数就是用来控制何时写日志数据的。 它有三个值: 0:log_buffer,将每秒一次地写入1og file中,并且log_file的f1ush(刷到磁盘)操作同时进行。该模式下在事务提交的时候,不会主动触发写入磁盘的操作。这种模式io读写效率最高,但是如果此刻进程崩溃,那么上一秒的所有的数据将会丢失,不太安全,不推荐使用。 1:每次事务提交时mySQL都会把log buffer的数据写入log_file,并且flush(刷到磁盘)中去,该模式为系统默认。这种模式虽然有很好的一致性,但是读写效率很差,因为每次都要读写io。只有主机崩溃的时候,才会丢失一个语句或者一个事务。强事务性系统,比如银行,使用这个。 2:每次事务提交时mySQL都会把log buffer的数据写入log_file,但是flush(刷到磁盘)操作并不会同时进行。该模式下,MySOL会每秒执行一次flush(刷到磁盘)操作。这个比0会安全一点,只有操作系统崩溃,或者断电的时候,才会丢失上一秒的数据。应用在在互联网评论系统这种,就算丢失了,也影响不大的的系统。 实际测试发现,该值对插入数据的速度影响非常大,设置为2时插入10000条记录只需要两秒,设置为0时只需要一秒,设置为1时,则需要229秒。因此,MySOL手册也建议尽量将插入操作合并成一个事务,这样可以大幅度提高速度。 innodb_doublewrite 安全相关的,双写操作,一个数据写两份。因为在日常开发的时候,innodb会把数据存在磁盘上,硬盘有时候并不可靠,比如有坏道。为了杜绝这些情况,就要将数据写两份,存储在不同的地方,这样其中的一个发生了问题,另外一个就会弥补上。这个值默认是开启的: SHOW GLOBAL variables LIKE "innodb_doublewrite"; 这个这默认值就很好,了解就好。 innodb_file_per_table 设置独立的表空间文件,可以看 innodb存储引擎 。可以设置为1,为每个表设置为独立的表文件。 SHOW GLOBAL variables LIKE "innodb_file_per_table"; innodb_thread_concurrency 代表innodb线程的并发数,默认是0表示不限制并发数量。若要设置则与服务器的cPU核心数相同或是CPU的核心数的2倍。 SHOW GLOBAL variables LIKE "innodb_thread_concurrency"; 并发数量并不是越多越好,因为同时执行的数量,只能是cpu核心的数量。这个最好在配置文件中设置,因为是相对底层的设置。
-
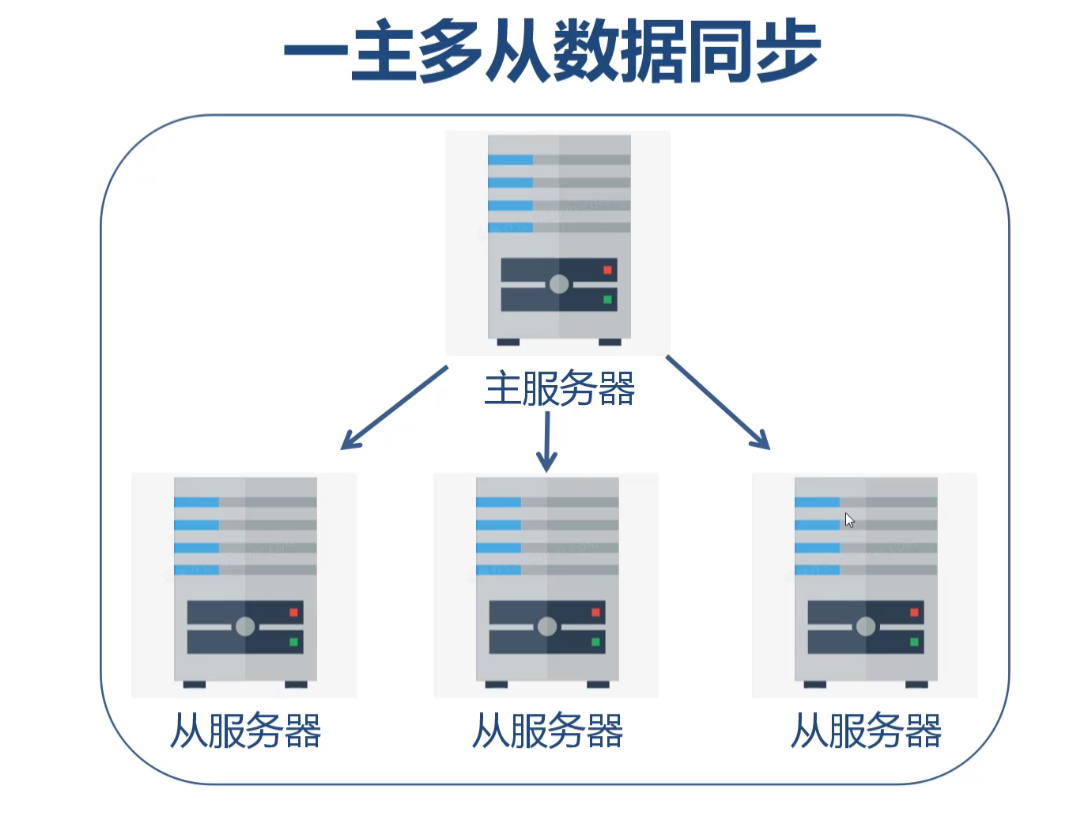
MySQL主从数据同步实践与解决方案 概述 在开发的时候,所有的数据写入的时候,都往主服务器写入,然后通过mysql底层的主从复制的功能,将数据同步分发到从属服务器上,这种一主多从的方案是最常见的,其中一台服务宕机了,其它的可以当作备用机 除此之外,还有两主多从,多主多从等,都是在这个基础上进行扩展的。 配置 主服务器 首先给主服务器配置,配置后重启服务器: [mysqld] port=3310 # 这个每个服务之间不要重复就好 server-id=1000 # 二进制日志名称,不同实例之间,日志文件名称是可以重复的,因为是存储在各自的data目录下 log-bin=mysql-bin 创建一个用户,用于从服务器连接,ip和账号以及密码可以自行设置: create user 'slave'@'192.168.1.1' identified by 'slave'; 然后给这个账号设置权限 grant replication slave on *.* to 'slave'@'192.168.31.156'; flush privileges; 最好我们看下主服务器有没有设置成功,执行完后输出如下记录: show master status; file字段是mysql的二进制日志文件,通过一般的文本编辑器是打不开的,默认是在data目录下,可以通过以下sql查看二进制日志的内容: show binlog events in 'mysql-bin.000001'; 这个日志内容,记录了执行过的sql语句,主从复制的原理很简单,从服务器只要从主服务器的出现过的sql记录,执行一遍即可。Pos字段就是每条日志的编号,是唯一的,从小到大排列。 从服务器 对从服务器进行配置: [mysqld] port=3311 # 这个每个服务之间不要重复就好 server-id=1001 # 二进制日志名称 log-bin=mysql-bin 指定从服务器指向哪个主服务器: change master to master_host = '192.168.1.1' ,master_port=3310 ,master_user='slave' ,master_password='slave' ,master_log_file='mysql-bin.000001' ,master_log_pos=951; -- 从951编号后产生的sql日志,都同步复制,可以在主服务器上执行show master status查看位置 开始主从复制 start slave; 查看从服务器的状态 show slave status; 上图是从服务器的一些概要信息,其中有几个字段比较重要: Slave_IO_Runing,这个代表是主从是否通信正常 Slave_SQL_Runing,这个代表是从服务器的sql是否运行正常
-
-
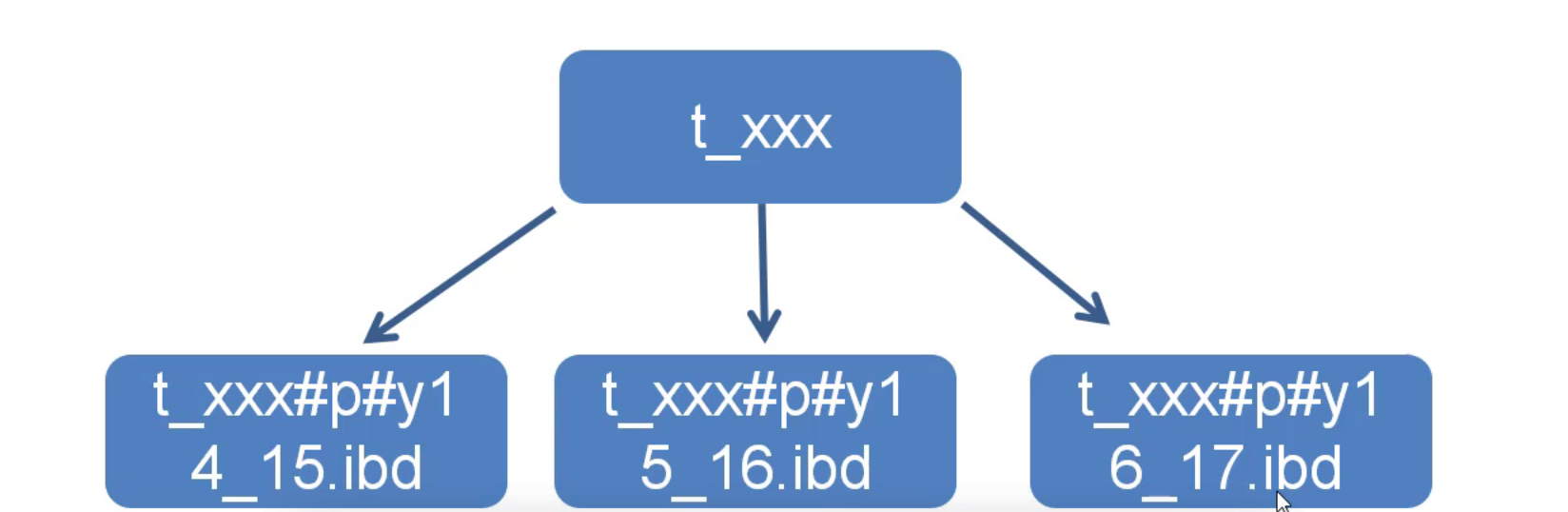
MySQL 分区表Partition 全面解析和实用指南 概述 分区表就是把大表按条件单独存储到不同的”物理小表”中,再构建出的完整”逻辑表”。 下例中,把t_xxx表物理上分为3个表 优点 更少的数据检索范围 拆分超级大的表,将部分热数据加载至内存 分区表的数据更容易维护 分区表数据文件可以分布在不同的硬盘上,并发IO 减少锁的范围,避免大表锁表 可独立备份,恢复分区数据 建立语句 CREATE TABLE test partitionid ( int(11)NOT NULL, create_time datetime NOT NULL, cyear int, -- 年份列 PRIMARY KEY (id,create_time,cyear) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (cyear) -- 指向cyear这一列,表示用这一列进行分区 ( PARTITION y14before VALUES LESSTHAN1(2014),-- 小于2014年的放在分区名称为y14before的表中 PARTITION y14_15 VALUES LESS THAN(2015),-- 2014-2015年之间 PARTITION y15_16 VALUESLESSTHAN(2016), PARTITION y16_17 VALES LESSTHAN(2017), PARTITION y17_18 VALUESLESSTHAN(2018), PARTITION y18_19 VALUESLESSTHAN(2019), PARTITION y19_20 VALUESLESS THAN(2020) PARTITION y20after VALUES LESS THAN maxvalue -- 2020年以后的 ENGINE = InnoDB -- 这个不写也可以,因为默认就是这个 ); 建立完成之后,在数据目录,会拆分成一个个的分区表文件。 我们可以使用以下sql语句,查看每个分区表的数据量: select PARTITION_NAME as"分区",TABLE_ROWS as "行数" from information_schema.partitions where table_schema="testdb"and table_name="test_partition"; 使用的限制 查询必须包含分区列,不允许对分区列进行计算,否则会对所有的分区文件进行全部的扫描 分区列必须是数字类型 分区表不支持建立外键索引 建表时主键必须包含所有的列,这个就是很多人不愿意使用分区表的原因,这个要求有点过分,会让我们的主键索引变得庞大无比 最多1024个分☒